pytorch训练神经网络爆内存的解决方案
训练的时候内存一直在增加,最后内存爆满,被迫中断。
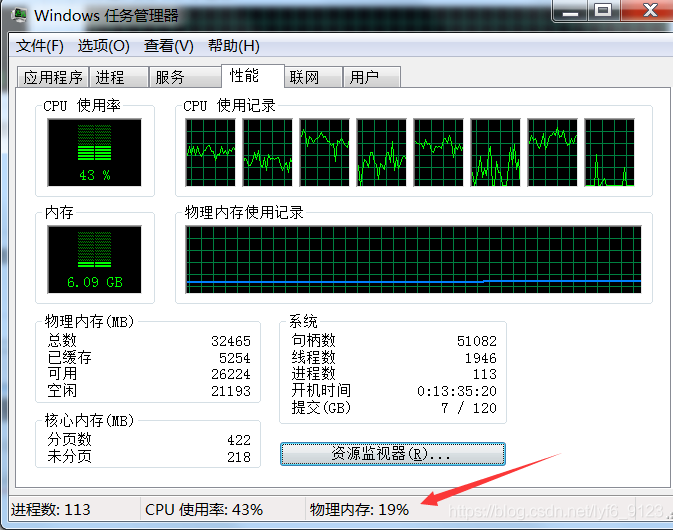
后来换了一个电脑发现还是这样,考虑是代码的问题。
检查才发现我的代码两次存了loss,只有一个地方写的是loss.item()。问题就在loss,因为loss是variable类型。
要写成loss_train = loss_train + loss.item(),不能直接写loss_train = loss_train + loss。否则就会发现随着epoch的增加,占的内存也在一点一点增加。
算是一个小坑吧,希望大家还是要仔细。
补充:pytorch神经网络解决回归问题(非常易懂)
对于pytorch的深度学习框架
在建立人工神经网络时整体的步骤主要有以下四步:
1、载入原始数据
2、构建具体神经网络
3、进行数据的训练
4、数据测试和验证
pytorch神经网络的数据载入,以MINIST书写字体的原始数据为例:
import torch
import matplotlib.pyplot as plt
def plot_curve(data):
fig=plt.figure()
plt.plot(range(len(data)),data,color="blue")
plt.legend(["value"],loc="upper right")
plt.xlabel("step")
plt.ylabel("value")
plt.show()
def plot_image(img,label,name):
fig=plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307,cmap="gray",interpolation="none")
plt.title("{}:{}".format(name, label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
def one_hot(label,depth=10):
out=torch.zeros(label.size(0),depth)
idx=torch.LongTensor(label).view(-1,1)
out.scatter_(dim=1,index=idx,value=1)
return out
batch_size=512
import torch
from torch import nn #完成神经网络的构建包
from torch.nn import functional as F #包含常用的函数包
from torch import optim #优化工具包
import torchvision #视觉工具包
import matplotlib.pyplot as plt
from utils import plot_curve,plot_image,one_hot
#step1 load dataset 加载数据包
train_loader=torch.utils.data.DataLoader(
torchvision.datasets.MNIST("minist_data",train=True,download=True,transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
test_loader=torch.utils.data.DataLoader(
torchvision.datasets.MNIST("minist_data",train=True,download=False,transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=False)
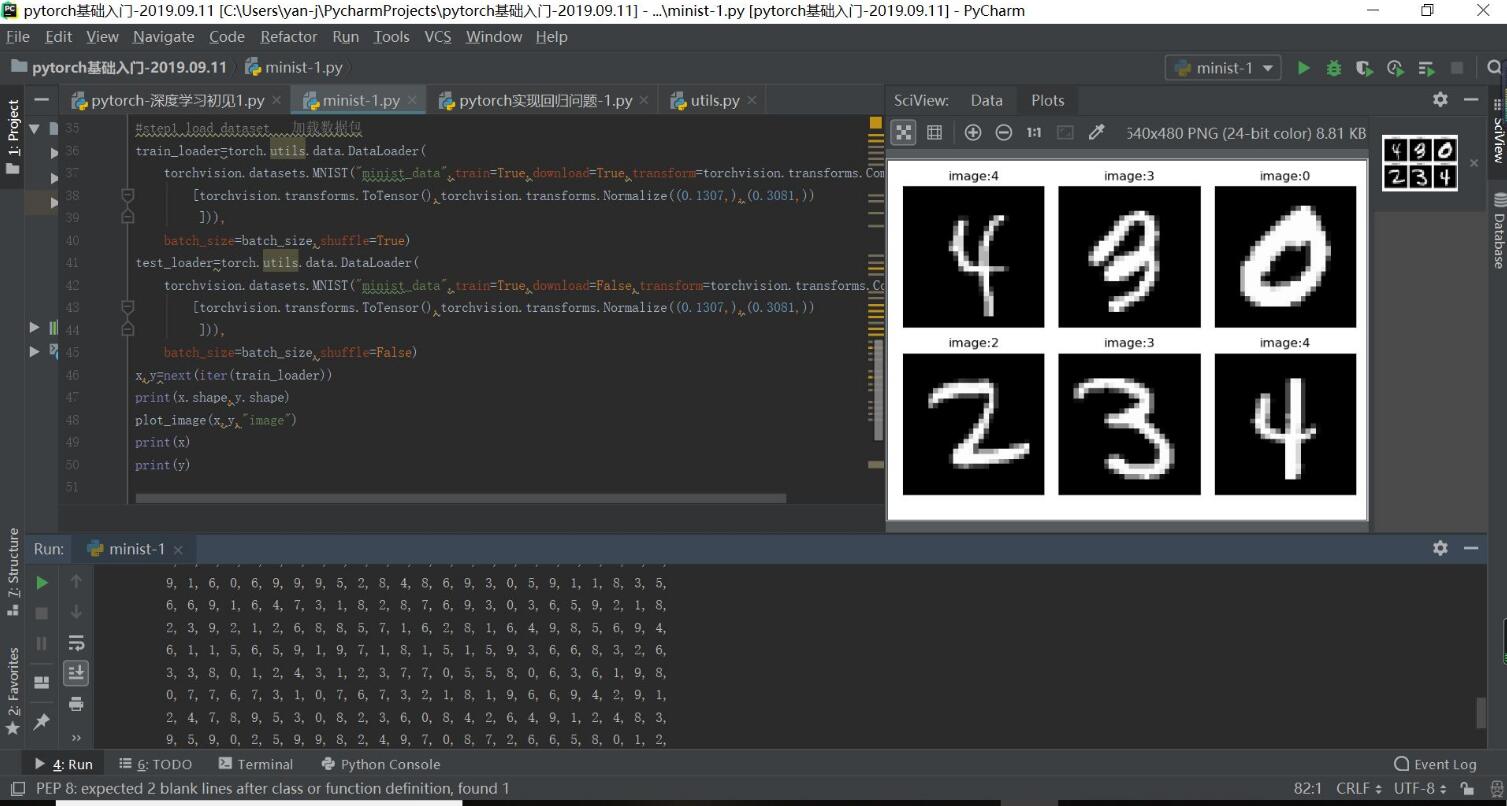
x,y=next(iter(train_loader))
print(x.shape,y.shape)
plot_image(x,y,"image")
print(x)
print(y)
以构建一个简单的回归问题的神经网络为例,
其具体的实现代码如下所示:
import torch
import torch.nn.functional as F # 激励函数都在这
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = x.pow(2) + 0.2 * torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
class Net(torch.nn.Module): # 继承 torch 的 Module(固定)
def __init__(self, n_feature, n_hidden, n_output): # 定义层的信息,n_feature多少个输入, n_hidden每层神经元, n_output多少个输出
super(Net, self).__init__() # 继承 __init__ 功能(固定)
# 定义每层用什么样的形式
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 定义隐藏层,线性输出
self.predict = torch.nn.Linear(n_hidden, n_output) # 定义输出层线性输出
def forward(self, x): # x是输入信息就是data,同时也是 Module 中的 forward 功能,定义神经网络前向传递的过程,把__init__中的层信息一个一个的组合起来
# 正向传播输入值, 神经网络分析出输出值
x = F.relu(self.hidden(x)) # 定义激励函数(隐藏层的线性值)
x = self.predict(x) # 输出层,输出值
return x
net = Net(n_feature=1, n_hidden=10, n_output=1)
print(net) # net 的结构
"""
Net (
(hidden): Linear (1 -> 10)
(predict): Linear (10 -> 1)
)
"""
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.2) # 传入 net 的所有参数, 学习率
loss_func = torch.nn.MSELoss() # 预测值和真实值的误差计算公式 (均方差)
for t in range(100): # 训练的步数100步
prediction = net(x) # 喂给 net 训练数据 x, 每迭代一步,输出预测值
loss = loss_func(prediction, y) # 计算两者的误差
# 优化步骤:
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
import matplotlib.pyplot as plt
plt.ion() # 实时画图something about plotting
for t in range(200):
prediction = net(x) # input x and predict based on x
loss = loss_func(prediction, y) # must be (1. nn output, 2. target)
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if t % 5 == 0: # 每五步绘一次图
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

PyTorch学习笔记之回归实战
本文主要是用PyTorch来实现一个简单的回归任务. 编辑器:spyder 1.引入相应的包及生成伪数据 import torch import torch.nn.functional as F # 主要实现激活函数 import matplotlib.pyplot as plt # 绘图的工具 from torch.autograd import Variable # 生成伪数据 x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim = 1)
-
详解Pytorch 使用Pytorch拟合多项式(多项式回归)
使用Pytorch来编写神经网络具有很多优势,比起Tensorflow,我认为Pytorch更加简单,结构更加清晰. 希望通过实战几个Pytorch的例子,让大家熟悉Pytorch的使用方法,包括数据集创建,各种网络层结构的定义,以及前向传播与权重更新方式. 比如这里给出 很显然,这里我们只需要假定 这里我们只需要设置一个合适尺寸的全连接网络,根据不断迭代,求出最接近的参数即可. 但是这里需要思考一个问题,使用全连接网络结构是毫无疑问的,但是我们的输入与输出格式是什么样的呢? 只将一个x作为输入
-
Pytorch 搭建分类回归神经网络并用GPU进行加速的例子
分类网络 import torch import torch.nn.functional as F from torch.autograd import Variable import matplotlib.pyplot as plt # 构造数据 n_data = torch.ones(100, 2) x0 = torch.normal(3*n_data, 1) x1 = torch.normal(-3*n_data, 1) # 标记为y0=0,y1=1两类标签 y0 = torch.zero
-
PyTorch上搭建简单神经网络实现回归和分类的示例
本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一.PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可得到Linux下conda指令: conda install pytorch torchvision -c soumith 目前PyTorch仅支持MacOS和Linux,暂不支持Windows.安装 PyTorch 会安装两个模块,一个是torch,一个 torch
-
pytorch训练神经网络爆内存的解决方案
训练的时候内存一直在增加,最后内存爆满,被迫中断. 后来换了一个电脑发现还是这样,考虑是代码的问题. 检查才发现我的代码两次存了loss,只有一个地方写的是loss.item().问题就在loss,因为loss是variable类型. 要写成loss_train = loss_train + loss.item(),不能直接写loss_train = loss_train + loss.否则就会发现随着epoch的增加,占的内存也在一点一点增加. 算是一个小坑吧,希望大家还是要仔细. 补充:py
-
Pytorch测试神经网络时出现 RuntimeError:的解决方案
Pytorch测试神经网络时出现"RuntimeError: Error(s) in loading state_dict for Net" 解决方法: load_state_dict(torch.load('net.pth') 在前,增加 model = nn.DataParallel(model) 就可以了. 比如 net = NET() net.cuda() net = nn.DataParallel(net) net.load_state_dict(torch.load('ne
-
解决Pytorch 训练与测试时爆显存(out of memory)的问题
Pytorch 训练时有时候会因为加载的东西过多而爆显存,有些时候这种情况还可以使用cuda的清理技术进行修整,当然如果模型实在太大,那也没办法. 使用torch.cuda.empty_cache()删除一些不需要的变量代码示例如下: try: output = model(input) except RuntimeError as exception: if "out of memory" in str(exception): print("WARNING: out of
-
Pytorch 使用Google Colab训练神经网络深度学习
目录 学习前言 什么是Google Colab 相关链接 利用Colab进行训练 一.数据集与预训练权重的上传 1.数据集的上传 2.预训练权重的上传 二.打开Colab并配置环境 1.笔记本的创建 2.环境的简单配置 3.深度学习库的下载 4.数据集的复制与解压 5.保存路径设置 三.开始训练 1.标注文件的处理 2.训练文件的处理 3.开始训练 断线怎么办? 1.防掉线措施 2.完了还是掉线呀? 总结 学习前言 Colab是谷歌提供的一个云学习平台,Very Nice,最近卡不够用了决定去白
-
Pytorch训练网络过程中loss突然变为0的解决方案
问题 // loss 突然变成0 python train.py -b=8 INFO: Using device cpu INFO: Network: 1 input channels 7 output channels (classes) Bilinear upscaling INFO: Creating dataset with 868 examples INFO: Starting training: Epochs: 5 Batch size: 8 Learning rate: 0.001
-
解决Pytorch训练过程中loss不下降的问题
在使用Pytorch进行神经网络训练时,有时会遇到训练学习率不下降的问题.出现这种问题的可能原因有很多,包括学习率过小,数据没有进行Normalization等.不过除了这些常规的原因,还有一种难以发现的原因:在计算loss时数据维数不匹配. 下面是我的代码: loss_function = torch.nn.MSE_loss() optimizer.zero_grad() output = model(x_train) loss = loss_function(output, y_train)
-
Pytorch训练过程出现nan的解决方式
今天使用shuffleNetV2+,使用自己的数据集,遇到了loss是nan的情况,而且top1精确率出现断崖式上升,这显示是不正常的. 在网上查了下解决方案.我的问题是出在学习率上了. 我自己做的样本数据集比较小,就三类,每类大概三百多张,初始学习率是0.5.后来设置为0.1就解决了. 按照解决方案上写的.出现nan的情况还有以下几种: 学习率太大,但是样本数据集又很小.(我的情况) 自定义的loss除以了一个很小的数字,小到接近0. 数据不干净,数据本身就有nan,可以用numpy.isna
-
Pytorch实现神经网络的分类方式
本文用于利用Pytorch实现神经网络的分类!!! 1.训练神经网络分类模型 import torch from torch.autograd import Variable import matplotlib.pyplot as plt import torch.nn.functional as F import torch.utils.data as Data torch.manual_seed(1)#设置随机种子,使得每次生成的随机数是确定的 BATCH_SIZE = 5#设置batch
-
使用PyTorch训练一个图像分类器实例
如下所示: import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np print("torch: %s" % torch.__version__) print("tortorchvisionch: %s" % torchvision.__version__) print(&
-
使用 pytorch 创建神经网络拟合sin函数的实现
我们知道深度神经网络的本质是输入端数据和输出端数据的一种高维非线性拟合,如何更好的理解它,下面尝试拟合一个正弦函数,本文可以通过简单设置节点数,实现任意隐藏层数的拟合. 基于pytorch的深度神经网络实战,无论任务多么复杂,都可以将其拆分成必要的几个模块来进行理解. 1)构建数据集,包括输入,对应的标签y 2) 构建神经网络模型,一般基于nn.Module继承一个net类,必须的是__init__函数和forward函数.__init__构造函数包括创建该类是必须的参数,比如输入节点数,隐藏层