基础语音识别-食物语音识别baseline(CNN)
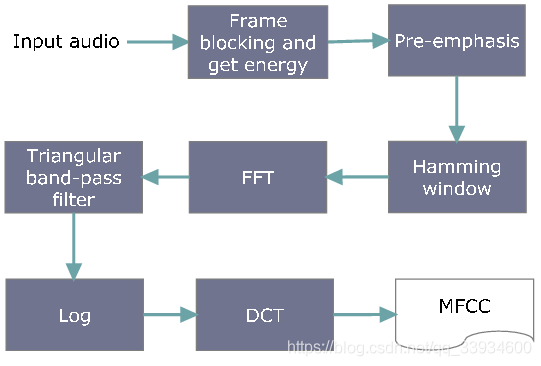
MFCC
梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC)。
MFCC通常有以下之过程:
- 将一段语音信号分解为多个讯框。
- 将语音信号预强化,通过一个高通滤波器。
- 进行傅立叶变换,将信号变换至频域。
- 将每个讯框获得的频谱通过梅尔滤波器(三角重叠窗口),得到梅尔刻度。
- 在每个梅尔刻度上提取对数能量。
- 对上面获得的结果进行离散傅里叶反变换,变换到倒频谱域。
- MFCC就是这个倒频谱图的幅度(amplitudes)。一般使用12个系数,与讯框能量叠加得13维的系数。
数据集
数据集来自Eating Sound Collection,数据集中包含20种不同食物的咀嚼声音,赛题任务是给这些声音数据建模,准确分类。
类别包括: aloe, ice-cream, ribs, chocolate, cabbage, candied_fruits, soup, jelly, grapes, pizza, gummies, salmon, wings, burger, pickles, carrots, fries, chips, noodles, drinks
训练集的大小: 750
测试集的大小: 250
1 下载和解压数据集
!wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531887/train_sample.zip !unzip -qq train_sample.zip !\rm train_sample.zip !wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531887/test_a.zip !unzip -qq test_a.zip !\rm test_a.zip
2 加载库函数
# 基本库 import pandas as pd import numpy as np from sklearn.model_selection import train_test_split #划分数据集 from sklearn.metrics import classification_report #用于显示主要分类指标的文本报告 from sklearn.model_selection import GridSearchCV #自动调参 from sklearn.preprocessing import MinMaxScaler #归一化
加载深度学习框架
# 搭建分类模型所需要的库 from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, Flatten, Dense, MaxPool2D, Dropout from tensorflow.keras.utils import to_categorical from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC #支持向量分类 !pip install librosa --user #加载音频处理库 # 其他库 import os import librosa #音频处理库 import librosa.display import glob
3 特征提取以及数据集的建立
建立类别标签字典
feature = []
label = []
# 建立类别标签,不同类别对应不同的数字。
label_dict = {'aloe': 0, 'burger': 1, 'cabbage': 2,'candied_fruits':3, 'carrots': 4, 'chips':5,
'chocolate': 6, 'drinks': 7, 'fries': 8, 'grapes': 9, 'gummies': 10, 'ice-cream':11,
'jelly': 12, 'noodles': 13, 'pickles': 14, 'pizza': 15, 'ribs': 16, 'salmon':17,
'soup': 18, 'wings': 19}
label_dict_inv = {v:k for k,v in label_dict.items()}
提取梅尔频谱特征
from tqdm import tqdm
def extract_features(parent_dir, sub_dirs, max_file=10, file_ext="*.wav"):
c = 0
label, feature = [], []
for sub_dir in sub_dirs:
for fn in tqdm(glob.glob(os.path.join(parent_dir, sub_dir, file_ext))[:max_file]): # 遍历数据集的所有文件
# segment_log_specgrams, segment_labels = [], []
#sound_clip,sr = librosa.load(fn)
#print(fn)
label_name = fn.split('/')[-2]
label.extend([label_dict[label_name]])
X, sample_rate = librosa.load(fn,res_type='kaiser_fast')
mels = np.mean(librosa.feature.melspectrogram(y=X,sr=sample_rate).T,axis=0) # 计算梅尔频谱(mel spectrogram),并把它作为特征
feature.extend([mels])
return [feature, label]
# 自己更改目录
parent_dir = './train_sample/'
save_dir = "./"
folds = sub_dirs = np.array(['aloe','burger','cabbage','candied_fruits',
'carrots','chips','chocolate','drinks','fries',
'grapes','gummies','ice-cream','jelly','noodles','pickles',
'pizza','ribs','salmon','soup','wings'])
# 获取特征feature以及类别的label
temp = extract_features(parent_dir,sub_dirs,max_file=100)
temp = np.array(temp)
data = temp.transpose()
获取特征和标签
# 获取特征
X = np.vstack(data[:, 0])
# 获取标签
Y = np.array(data[:, 1])
print('X的特征尺寸是:',X.shape)
print('Y的特征尺寸是:',Y.shape)
X的特征尺寸是: (1000, 128)
Y的特征尺寸是: (1000,)
独热编码
# 在Keras库中:to_categorical就是将类别向量转换为二进制(只有0和1)的矩阵类型表示 Y = to_categorical(Y) print(X.shape) print(Y.shape)
(1000, 128)
(1000, 20)
把数据集划分为训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state = 1, stratify=Y)
print('训练集的大小',len(X_train))
print('测试集的大小',len(X_test))
训练集的大小 750
测试集的大小 250
X_train = X_train.reshape(-1, 16, 8, 1) X_test = X_test.reshape(-1, 16, 8, 1)
4 建立模型
搭建CNN网络
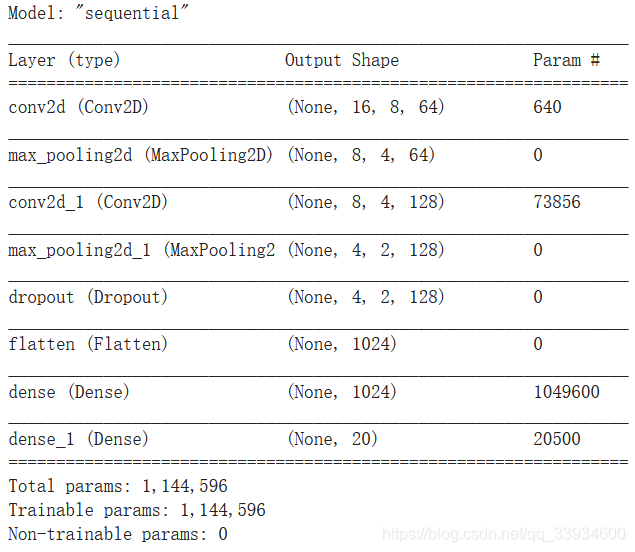
model = Sequential() # 输入的大小 input_dim = (16, 8, 1) model.add(Conv2D(64, (3, 3), padding = "same", activation = "tanh", input_shape = input_dim))# 卷积层 model.add(MaxPool2D(pool_size=(2, 2)))# 最大池化 model.add(Conv2D(128, (3, 3), padding = "same", activation = "tanh")) #卷积层 model.add(MaxPool2D(pool_size=(2, 2))) # 最大池化层 model.add(Dropout(0.1)) model.add(Flatten()) # 展开 model.add(Dense(1024, activation = "tanh")) model.add(Dense(20, activation = "softmax")) # 输出层:20个units输出20个类的概率 # 编译模型,设置损失函数,优化方法以及评价标准 model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy']) model.summary()
训练模型
# 训练模型 model.fit(X_train, Y_train, epochs = 100, batch_size = 15, validation_data = (X_test, Y_test))
5 预测测试集
def extract_features(test_dir, file_ext="*.wav"):
feature = []
for fn in tqdm(glob.glob(os.path.join(test_dir, file_ext))[:]): # 遍历数据集的所有文件
X, sample_rate = librosa.load(fn,res_type='kaiser_fast')
mels = np.mean(librosa.feature.melspectrogram(y=X,sr=sample_rate).T,axis=0) # 计算梅尔频谱(mel spectrogram),并把它作为特征
feature.extend([mels])
return feature
X_test = extract_features('./test_a/')
X_test = np.vstack(X_test)
predictions = model.predict(X_test.reshape(-1, 16, 8, 1))
preds = np.argmax(predictions, axis = 1)
preds = [label_dict_inv[x] for x in preds]
path = glob.glob('./test_a/*.wav')
result = pd.DataFrame({'name':path, 'label': preds})
result['name'] = result['name'].apply(lambda x: x.split('/')[-1])
result.to_csv('submit.csv',index=None)
!ls ./test_a/*.wav | wc -l
!wc -l submit.csv
6 结果

到此这篇关于基础语音识别-食物语音识别baseline(CNN)的文章就介绍到这了,更多相关语音识别的内容请搜索我们以前的文章或继续浏览下面的相关文章,希望大家以后多多支持我们!
相关推荐
-
基于python实现百度语音识别和图灵对话
图例如下 https://github.com/Dongvdong/python_Smartvoice 上电后,只要周围声音超过 2000,开始录音5S 录音上传百度识别,并返回结果文字输出 继续等待,周围声音是否超过2000,没有就等待. 点用电脑API语音交互 代码如下 # -*- coding: utf-8 -*- # 树莓派 from pyaudio import PyAudio, paInt16 import numpy as np from datetime import datet
-
使用Python和百度语音识别生成视频字幕的实现
从视频中提取音频 安装 moviepy pip install moviepy 相关代码: audio_file = work_path + '\\out.wav' video = VideoFileClip(video_file) video.audio.write_audiofile(audio_file,ffmpeg_params=['-ar','16000','-ac','1']) 根据静音对音频分段 使用音频库 pydub,安装: pip install pydub 第一种方法: #
-

Python结合百度语音识别实现实时翻译软件的实现
一.所需库安装 pip install PyAudio pip install SpeechRecognition pip install baidu-aip pip install Wave pip install Wheel pip install Pyinstaller 二.百度官网申请服务 三.源代码分享 import pyaudio import wave from aip import AipSpeech import time # 用Pyaudio库录制音频 # out_file:
-
Python实现简单的语音识别系统
最近认识了一个做Python语音识别的朋友,聊天时候说到,未来五到十年,Python人工智能会在国内掀起一股狂潮,对各种应用的冲击,不下于淘宝对实体经济的冲击.在本地(江苏某三线城市)做这一行,短期可能显不出效果,但从长远来看,绝对是一个高明的选择.朋友老家山东的,毕业来这里创业,也是十分有想法啊. 将AI课上学习的知识进行简单的整理,可以识别简单的0-9的单个语音.基本方法就是利用库函数提取mfcc,然后计算误差矩阵,再利用动态规划计算累积矩阵.并且限制了匹配路径的范围.具体的技术网上很多,不
-
对Python 语音识别框架详解
如下所示: from win32com.client import constants import os import win32com.client import pythoncom speaker = win32com.client.Dispatch("SAPI.SPVOICE") class SpeechRecognition: def __init__(self, wordsToAdd): self.speaker = win32com.client.Dispatch(&qu
-
基础语音识别-食物语音识别baseline(CNN)
MFCC 梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC). MFCC通常有以下之过程: 将一段语音信号分解为多个讯框. 将语音信号预强化,通过一个高通滤波器. 进行傅立叶变换,将信号变换至频域. 将每个讯框获得的频谱通过梅尔滤波器(三角重叠窗口),得到梅尔刻度. 在每个梅尔刻度上提取对数能量. 对上面获得的结果进行离散傅里叶反变换,变换到倒频谱域. MFCC就是这个倒频谱图的幅度(amplitudes).一般使用12个系数,与讯框能
-
Python-OpenCV深度学习入门示例详解
目录 0. 前言 1. 计算机视觉中的深度学习简介 1.1 深度学习的特点 1.2 深度学习大爆发 2. 用于图像分类的深度学习简介 3. 用于目标检测的深度学习简介 4. 深度学习框架 keras 介绍与使用 4.1 keras 库简介与安装 4.2 使用 keras 实现线性回归模型 4.3 使用 keras 进行手写数字识别 小结 0. 前言 深度学习已经成为机器学习中最受欢迎和发展最快的领域.自 2012 年深度学习性能超越机器学习等传统方法以来,深度学习架构开始快速应用于包括计算机视觉
-
浅析如何利用JavaScript进行语音识别
一.基础用法 var recognition = new webkitSpeechRecognition(); recognition.onresult = function(event) { console.log(event) } recognition.start(); 这里操作实际会让用户授权页面开启麦克风,如果用户允许的话,用户可以开始说话了,如果你停说话了,onresult注册的时间 则会被触发,并会讲捕获的音频返回成一个JavaScript对象. 二.响应流 你需要等待用户准备好对
-
Android基于讯飞语音SDK实现语音识别
一.准备工作 1.你需要android手机应用开发基础 2.科大讯飞语音识别SDK android版 3.科大讯飞语音识别开发API文档 4.android手机 关于科大讯飞SDK及API文档,请到科大语音官网下载:http://www.xfyun.cn/ 当然SDK和API有多个版本可选,按照你的需要下载,其次,下载需要填写资料申请注册,申请通过或可获得Appid 如下图,申请一个APPID,就可以了. 二.语音识别流程 1.创建识别控件 函数原型 Public RecognizerDialo
-
Python实现语音识别和语音合成功能
声音的本质是震动,震动的本质是位移关于时间的函数,波形文件(.wav)中记录了不同采样时刻的位移. 通过傅里叶变换,可以将时间域的声音函数分解为一系列不同频率的正弦函数的叠加,通过频率谱线的特殊分布,建立音频内容和文本的对应关系,以此作为模型训练的基础. 案例:画出语音信号的波形和频率分布,(freq.wav数据地址) # -*- encoding:utf-8 -*- import numpy as np import numpy.fft as nf import scipy.io.wavfil
-
Linux下利用python实现语音识别详细教程
目录 语音识别工作原理简介 选择合适的python语音识别包 安装SpeechRecognition 识别器类 音频文件的使用 英文的语音识别 噪音对语音识别的影响 麦克风的使用 中文的语音识别 小范围中文识别 语音合成 语音识别工作原理简介 语音识别源于 20 世纪 50 年代早期在贝尔实验室所做的研究.早期语音识别系统仅能识别单个讲话者以及只有约十几个单词的词汇量.现代语音识别系统已经取得了很大进步,可以识别多个讲话者,并且拥有识别多种语言的庞大词汇表.语音识别的首要部分当然是语音.通过麦克
-
iOS10语音识别框架SpeechFramework应用详解
摘要: iOS10语音识别框架SpeechFramework应用 一.引言 iOS10系统是一个较有突破性的系统,其在Message,Notification等方面都开放了很多实用性的开发接口.本篇博客将主要探讨iOS10中新引入的SpeechFramework框架.有个这个框架,开发者可以十分容易的为自己的App添加语音识别功能,不需要再依赖于其他第三方的语音识别服务,并且,Apple的Siri应用的强大也证明了Apple的语音服务是足够强大的,不通过第三方,也大大增强了用户的安全性. 二.S
-
微信公众平台开发之语音识别.Net代码解析
语音识别这个功能属于高级功能,必须微信实名认证后才能实现,认证费用300元/年,如果你作为开发者可以申请测试帐号,也是可以的.首先建立一个微信消息类,这个类比之前多了一个属性. class wxmessage { public string FromUserName { get; set; } public string ToUserName { get; set; } public string MsgType { get; set; } public string EventName { g
-
Android使用百度语音识别的示例代码
本文使用百度语音识别,完成语音识别的功能,使用百度语音识别,先要申请APP ID,这个直接到百度网站上有说明文档,本文不再赘述.申请之后,下载SDK包,按照百度官网要求,合并libs和res两个目录到项目中,然后在build.gradle(module:app)中的Android{...}下添加 sourceSets{ main{ jniLibs.srcDirs=['libs'] } } 这样, 百度语音识别的so文件才能正常使用. Manifest文件中添加权限 <uses-permissio
-
百度语音识别(Baidu Voice) Android studio版本详解
百度语音识别(Baidu Voice) Android studio版本 已同步更新至个人blog:http://dxjia.cn/2016/02/29/baidu-voice-helper/ 最近在一个练手小项目里要用到语音识别,搜索了一下,比较容易集成的就算Baidu voice跟讯飞语音了,baidu提供了直接可以使用的显示控件,而讯飞需要自己实现,另外baidu提供每天5W次的调用频率,对于我来说足够使用啦.所以就选择使用Baidu Voice(控件会有baidu logo和关键字,所以