Python的字符串示例讲解
之前我们学习过一个不可变的序列叫元组,今天我们探讨的字符串,也是一个不可变序列。
1. 字符串的创建
一个概念: 字符串的驻留机制
那什么是字符串的驻留机制呢?
意思是: 仅保留一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时候,不会开辟新的空间,而是把该字符串的地址重新赋值给新建的变量。
1) 字符串的定义
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s a='itlaoxin' b="itlaoxin" c='''itlaoxiin''' print(a,b,c,id(a),id(b),id(c))
输出结果

可以看到ID都是一样的。
在内存中只有一份
几点注意事项:
在交互模式下,能实现驻留机制的情况:
- 字符串的长度为0 或者1时
- 符合标识符的字符串
- 字符串只在编译时候进行驻留,而非运行时
- 【-5,256】之间的整数数字

2. 字符串的常用操作
关于字符串的操作,我们可以把字符串看成是关于字符的列表:
1) 查询操作
- index() 查找字符串substr第一次出现的位置,如果查找的子串不存在,抛出异常
- rindex() 查找字符串substr最后一次出现的问题,如果不存在,则报异常
- find() 查找子串substr第一次出现的位置,不存在返回-1
- rfind 查找子串substr最后一次出现的位置,若不存在返回 -1
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
s='hello,world'
print(s.index('l')) #2
print(s.find('l')) #2
print(s.rfind('l')) #9
print(s.rindex('l')) #9
这里建议大家使用find,或者rfind,因为不会报异常
2) 字符串的常用操作
a) 大小写转换
- upper() 把字符串中所有的字符都转化成大写字母(会产生新的字符串对象)
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" a=s.upper() print(s) print(a)
- lower() 把字符串中所有的字符都转换成小写字母
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" a=s.lower() print(s) print(a)
输出结果:
hello,ITlaoxin
hello,itlaoxin
swapcase() 把字符串中所有的大写字母转换成小写字母,把所有的小写字母转换成大写字母
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" a=s.swapcase() print(a,id(a)) print(s,id(s))
- capitalize() 把第一个字符转换成大写,把其余的字符转换成小写
- tilele( )把每个单词的第一个字符转换成大写,把每个读单词的剩余字符转换成小写
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" a=s.title() print(a)
b) 字符串内容对齐操作
- center() 居中对齐
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" print(s.center(20,'*'))

一共14个字符,定义20个字符,左右各三个
- ljust() 左对齐
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" print(s.ljust(20,"*"))
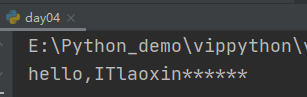
如果不写* ,默认是空格
- rjust 右对齐
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" print(s.rjust(20,"*"))

- zfill 右对齐
这种方式会用0填充
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" print(s.zfill(20))
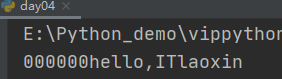
c) 字符串的拆分
- split() 分割,从左边开始,默认的分割符是空格,分割完后是列表
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello,ITlaoxin" lst=s.split() print(lst)
输出结果:
我们可以指定分割符,用sep=‘|' 的形式
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello|ITlaoxin|gaosh" lst=s.split(sep='|') print(lst)
输出结果
['hello,ITlaoxin']
如果这个地方我们用默认的空格会是什么结果:
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello|ITlaoxin|gaosh" lst=s.split() print(lst)
结果
['hello|ITlaoxin|gaosh']
可以看到,因为这个字符串中没有空格,所以他就是一个元素的列表。
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello|ITlaoxin|gaosh" lst=s.split(sep='|',maxsplit=1) print(lst)
结果:
['hello', 'ITlaoxin|gaosh']
这里只拆分了一次。
- rsplit() 从字符右边开始拆分,默认拆分字符是空格,返回值是一个列表
maxsplit可以指定最大拆分次数
这个和split的使用方法一样,只是rsplist是从右边开始拆分,splist从左边拆分
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s s="hello|ITlaoxin|gaosh" lst=s.split(sep='|',maxsplit=1) print(lst) lst1=s.rsplit(sep='|',maxsplit=1) print(lst1)
结果如图所示:

d) 字符串的判断方法
- isidentifier() 判断指定的字符串是否是合法的标识符
- isspace() 判断指定的字符串是否全部由空白字符组成(回车,换行,水平指制表符)
- issalpha() 判断字符串是否全部由字母组成
- isdecimal( )判断指定字符串是否全部是十进制组成
- isnumeric() 判断指定的字符串全部由数字组成
- isalnum()判断指定字符串是否全部由字母和数字组成
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
s='hello,world,python'
print('1',s.isidentifier())
print('2','hello'.isidentifier())
print('3','\t'.isidentifier())
print('4','abc'.isspace())
print('5','abc'.isalpha())
print('6','1'.isspace())
print('7','123'.isnumeric())
print('8','abc123'.isalnum())
print('9','123abc!'.isalnum())
e) 字符串的其他操作 字符串的替换replace()
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
s='hello,world,python'
print(s.replace('python','itlaoxin'))
s1='hello,python,python ,python'
print(s1.replace('python','itlaoxin',2))
结果:
hello,world,itlaoxin
hello,itlaoxin,itlaoxin ,python
字符串的合并 join()
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
lst=['hello','java','python']
print('|'.join(lst))
结果:hello|java|python
f) 字符串的比较
使用运算符 >,>= ,<,<= ,= ,!=
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
print('1','itlaoxin'>'laoxin')
print('2','itlaoxin'>'itlaox')
结果:
False
True
如果第一个字母就不相同,就比较原始值 ord()
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
print('1','itlaoxin'>'laoxin')
print('2','itlaoxin'>'itlaox')
print('3','python'>'java')
## 相当于
print(ord('p'),ord('j'))
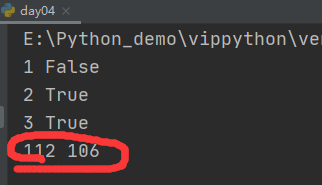
第三个相当于112与106比较
g) 字符串的切片
字符串是不可变类型,不具备增删改查的操作,切片是会产生新的对象的
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s a='hello,world,itlaoxin' print(a[:5])
输出结果:
hello
不写起始位置,它会从index0开始切
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s a='hello,world,itlaoxin' print(a[6:]) #world,itlaoxin
没有指定结束位置,会切到最后
step是指定步长
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s a='hello,world,itlaoxin' print(a[1:8:2]) #el,o
# 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s a='hello,world,itlaoxin' print(a[1:8:2]) print(a[::2]) #hlowrdiloi
h) 格式化字符串
为什么要格式化字符串呢?
字符串的拼接会产生新的Id,会造成空间浪费, 这个时候就需要使用字符串的格式化。
格式化字符串的两种方式:
% 做占位符
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
#第一种方式%
name='互联网老辛'
age=40
print('我叫%s,今年%d岁了'%(name,age))
{} 做占位符
要使用到format()方法
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
#第一种方式%
name='互联网老辛'
age='40'
print('我叫{0},今年{1}岁了'.format(name,age))
除此之外还可以表示精读和宽度:
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
print('%d'% 99)
print('%10d'% 99)
这里的10表示的就是宽度
精度:
保留3位小数
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
print('%.3f' % 3.11516)
混合使用:
# 作者:互联网老辛
# 开发时间:2021/4/4/0004 6s
print('%10.3f' % 3.11516)
%10.3f
总宽度为10,小数点保留3位
总结
到现在所有的数据类型的基本操作就介绍完了,这些应该都算是基础,接下来我们要进入到函数的章节。
到此这篇关于Python的字符串示例讲解的文章就介绍到这了,更多相关Python的字符串内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python中过滤字符串列表的方法
Python使用列表数据类型在顺序索引中存储多个数据.它的工作方式类似于其他编程语言的数字数组.filter()方法是Python的一种非常有用的方法.可以使用filter()方法从Python中的任何字符串.列表或字典中过滤一个或多个数值.它根据任何特定条件过滤数据.当条件返回true时,它将存储数据,而返回false时将丢弃数据.本文通过使用不同的示例展示了如何在Python中过滤列表中的字符串数据.您必须使用Python 3+来测试本文的示例. 使用另一个列表过滤字符串列表 本示例说明了如
-
浅析python字符串前加r、f、u、l 的区别
先给大家介绍下Python 字符串前面加u,r,b,f的含义(字符串前缀) 1.字符串前加 u 例:u"我是含有中文字符组成的字符串." 作用: 后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码. 2.字符串前加 r 例:r"\n\n\n\n" # 表示一个普通生字符串 \n\n\n\n,而不表示换行了. 作用: 去掉反斜杠的转移机制. (特殊字符:即那些,反斜杠加上对应字母,表示对应的特殊含义的
-

使用Python提取文本中含有特定字符串的方法示例
今天搞了一天的文本处理,发现python真的太适合做数据处理了.废话不多说,一起学习吧! 1.我的原始数据是这样的,如图 2.如果要提取每行含有pass的字符串,代码如下: import re filepath = "E:/untitled1/analyze_log/test.log" txt = open(filepath, "r").read() result="" test_text = re.findall(".........
-
Python 处理带有 \u 的字符串操作
最近遇到一个头疼的问题,用socket接收到一个字符串 格式如下: {"trade_status": {"desc": "\u30106\u3011 - \u8d22\u52a1\u7ed3\u7b97\u5df2\u5b8c\u6210 "}}/end/ 其中含有一段含有\u的编码字串,怎么将其转化为汉字. decode().encode('utf-8') 不行,decode.encode半天搞不定,后来偶然发现,在decode时可以选则uni
-
去除python中的字符串空格的简单方法
python编程中,我们在修改代码,遇到空格很多的情况下,我们要删除空格.本文小编整理了三种字符串去除空格的方法: 方法一:使用字符串函数replace,去除全部空格. 实例: >>> a = " a b c " >>> a.replace(" ", "") 'abc' 方法二:使用字符串函数split,去除字符串开头或者结尾的空格. 实例: >>> a = ''.join(a.split()
-
Python的字符串示例讲解
之前我们学习过一个不可变的序列叫元组,今天我们探讨的字符串,也是一个不可变序列. 1. 字符串的创建 一个概念: 字符串的驻留机制 那什么是字符串的驻留机制呢? 意思是: 仅保留一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时候,不会开辟新的空间,而是把该字符串的地址重新赋值给新建的变量. 1) 字符串的定义 # 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s a='itlaoxin' b=
-
python difflib模块示例讲解
difflib模块提供的类和方法用来进行序列的差异化比较,它能够比对文件并生成差异结果文本或者html格式的差异化比较页面,如果需要比较目录的不同,可以使用filecmp模块. class difflib.SequenceMatcher 此类提供了比较任意可哈希类型序列对方法.此方法将寻找没有包含'垃圾'元素的最大连续匹配序列. 通过对算法的复杂度比较,它由于原始的完形匹配算法,在最坏情况下有n的平方次运算,在最好情况下,具有线性的效率. 它具有自动垃圾启发式,可以将重复超过片段1%或者重复20
-
python中字符串变二维数组的实例讲解
有一道算法题题目的意思是在二维数组里找到一个峰值.要求复杂度为n. 解题思路是找田字(四边和中间横竖两行)中最大值,用分治法递归下一个象限的田字. 在用python定义一个二维数组时可以有list和numpy.array两种方式,看了几篇python中二维数组的建立的博客发现大多都是建立的初始化的二维数组,而我需要通过文件读取得到的是字符串,再把字符串转换为二维数组,找不到解决方法还是决定自己来转换. 首先,最开始的字符串输出如下,数字之间有空格 思路就是把先按换行符进行切片,再对每一行的字符再
-
将python运行结果保存至本地文件中的示例讲解
一.建立文件,保存数据 1.使用python中内置的open函数 打开txt文件 #mode 模式 #w 只能操作写入 r 只能读取 a 向文件追加 #w+ 可读可写 r+可读可写 a+可读可追加 #wb+写入进制数据 #w模式打开文件,如果而文件中有数据,再次写入内容,会把原来的覆盖掉 file_handle=open('1.txt',mode='w') 2.向文件中写入数据 2.1 write写入 #\n 换行符 file_handle.write('hello word 你好 \n') 2
-
对python创建及引用动态变量名的示例讲解
实际上在python中用列表就可以实现动态变量名的管理,python中的列表中可以存储任何类型的元素: listA = [0,"str",B()] 上述列表分别存储了整数,字符串,对象.使用和创建时只需配合列表下标即可. 但python确实有创建动态表量名的方法: names = locals() for i in range(1,10): names['a%i'%i] = input('Abss %d'%i) for i in range(1,10): print(names['a%
-
对python自动生成接口测试的示例讲解
在python中Template可以将字符串的格式固定下来,重复利用. 同一套测试框架为了可以复用,所以我们可以将用例部分做参数化,然后运用到各个项目中. 代码如下: coding=utf-8 ''' 作者:大石 功能:自动生成pyunit框架下的接口测试用例 环境:python2.7.6 用法:将用户给的参数处理成对应格式,然后调用模块类生成函数,并将参数传入即可 ''' from string import Template #动态生成单个测试用例函数字符串 def singleMethod
-
Python计算IV值的示例讲解
在对变量分箱后,需要计算变量的重要性,IV是评估变量区分度或重要性的统计量之一,python计算IV值的代码如下: def CalcIV(Xvar, Yvar): N_0 = np.sum(Yvar==0) N_1 = np.sum(Yvar==1) N_0_group = np.zeros(np.unique(Xvar).shape) N_1_group = np.zeros(np.unique(Xvar).shape) for i in range(len(np.unique(Xvar)))
-
Python实现购物系统(示例讲解)
要求: 用户入口 1.商品信息存在文件里 2.已购商品,余额记录. 商家入口 可以添加商品,修改商品价格 Code: 商家入口: # Author:P J J import os ps = ''' 1 >>>>>> 修改商品 2 >>>>>> 添加商品 按q为退出程序 ''' # 打开两个文件,f文件为原来存取商品文件,f_new文件为修改后的商品文件 f = open('commodit', 'r', encoding='utf-8
-
Python 由字符串函数名得到对应的函数(实例讲解)
把函数作为参数的用法比较直观: def func(a, b): return a + b def test(f, a, b): print f(a, b) test(func, 3, 5) 但有些情况下,'要传递哪个函数'这个问题事先还不确定,例如函数名与某变量有关. 可以利用 func = globals().get(func_name) 来得到函数: def func_year(s): print 'func_year:', s def func_month(s): print 'func_
-
Python实现字符串匹配算法代码示例
字符串匹配存在的问题 Python中在一个长字符串中查找子串是否存在可以用两种方法:一是str的find()函数,find()函数只返回子串匹配到的起始位置,若没有,则返回-1:二是re模块的findall函数,可以返回所有匹配到的子串. 但是如果用findall函数时需要注意字符串中存在的特殊字符 蛮力法字符串匹配: 将模式对准文本的前m(模式长度)个字符,然后从左到右匹配每一对对应的字符,直到全部匹配或遇到一个不匹配的字符.后一种情况下,模式向右移一位. 代码如下: def string_m