R语言数据框中的负索引介绍
以R语言自带的mtcars数据框为例:
这是原始的mtcars数据:

这里只列出了前面几行数据。
然后负索引mtcars[,-2:-3],得到的结果
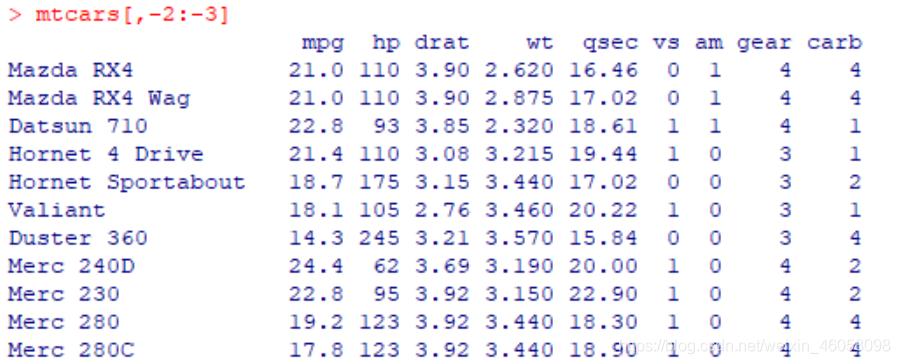
删除了第二列和第三列数据
所以R语言数据框中的负索引是指删除数据框中对应的列(或者行)
ps:这和Python里面的规则好像不太一样,Python里的负索引好像是指倒数第几列(或者第几行),这里这两个软件区别还挺大的~~写个笔记提醒一下自己~
补充:R语言中的负整数索引
看代码吧~
> x<-matrix(c(1,2,3,4,5,6,7,8,9),nrow = 3,ncol = 3,byrow = TRUE)
> x
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> x[-1,]
[,1] [,2] [,3]
[1,] 4 5 6
[2,] 7 8 9
这在R中称为负整数索引向量,这种索引向量指定被排除的元素而不是包括进来,因此x[-1,]表示取出矩阵x的除了第一行元素外的其他元素。
补充:R语言-基本语法、数据类型及索引
1. 基本语法
print() 、cat()打印输出
#单行注释
if(FALSE){code block}多行注释
2. 数据类型
class():查看数据类型
2.1 基本数据类型
| 基本数据类型 | 示例 |
|---|---|
| 逻辑值(logical) | 真:TRUE、T,假:FALSE、F |
| 数字(numeric) | 123、5 |
| 整型(integer) | 2L、34L |
| 复数(complex) | 3+2i |
| 字符(character) | 'good' |
2.2 向量Vector
c()函数创建向量。
注意:必须保证元素类型相同,否则会默认进行类型转换。
> x <- c(1, 2)
> class(x)
[1] "numeric"
> x <- c('s')
> class(x)
[1] "character"
> x <- c(1, 2, 's')
> class(x)
[1] "character"
2.3 列表List
列表可以包含许多不同类型的元素,如向量、函数、嵌套列表。
注意:[]与[[]]的区别。[]取出来的仍是一个列表,[[]]取出来的是本身的数据类型。
> list1 <- list(c(2,3), 21, 's', sin) # 分别包含列表、数字、字符、函数
> class(list1)
[1] "list"
> list1[1] # 取出来的仍是一个列表
[[1]]
[1] 2 3
> list1[[1]] # 取出来的是子列表中的元素
[1] 2 3
> class(list1[1])
[1] "list"
> class(list1[[1]])
[1] "numeric"
> list1[[2]]
[1] 21
> list1[2] + 2
Error in list1[2] + 2 : non-numeric argument to binary operator
> list1[[2]] + 2
[1] 23
> list1[[4]]
function (x) .Primitive("sin")
> class(list1[[4]])
[1] "function"
2.4 矩阵Matrix
矩阵是二维数据集,它可以使用矩阵函数的向量输入创建。
byrow参数决定元素存放的顺序。
> M <- matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
> M
[,1] [,2] [,3]
[1,] "a" "a" "b"
[2,] "c" "b" "a"
> M[,1] # 取出第一列数据
[1] "a" "c"
> M[1,] # 取出第一行数据
[1] "a" "a" "b"
> M[2,1] # 取出单个元素
[1] "c"
2.5 数组Array
利用数组可以创建任意维度的数据。
> array1 <- array(c('green','yellow'), dim=c(3,3,2))
> array1
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"
2.6 因子Factor
因子是使用向量创建的对象。它将向量与向量中元素的不同值一起存储为标签。 标签是字符类型。 它们在统计建模中非常有用。
使用factor()函数创建因子。nlevels函数给出级别计数。
> apple_colors <- c('green','green','yellow','red','red','red','green')
> factor_apple <- factor(apple_colors)
> factor_apple
[1] green green yellow red red red green
Levels: green red yellow
> nlevels(factor_apple)
[1] 3
2.7 数据框Data Frame
表格数据对象。每列可以包含不同的数据类型。 第一列可以是数字,而第二列可以是字符,第三列可以是逻辑的。 它是等长度的向量的列表。
使用data.frame()函数创建数据框。
# 创建数据框,表格对象
> BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
> BMI
gender height weight Age
1 Male 152.0 81 42
2 Male 171.5 93 38
3 Female 165.0 78 26
# 获取第二列
> BMI[2]
height
1 152.0
2 171.5
3 165.0
# 获取第一行
> BMI[1,]
gender height weight Age
1 Male 152 81 42
# 获取第一列数据,类型为DataFrame
> BMI[1]
gender
1 Male
2 Male
3 Female
> class(BMI[1])
[1] "data.frame"
# 获取第一列,并将其转换为factor类型
> BMI[,1]
[1] Male Male Female
Levels: Female Male
# 获取第一个元素,转换为factor类型
> BMI[1,1]
[1] Male
Levels: Female Male
# 获取第二列,不改变数据类型
> BMI[2]
height
1 152.0
2 171.5
3 165.0
# 获取第二列,改变数据类型
> BMI[,2]
[1] 152.0 171.5 165.0
# 根据列的名称获取factor类型数据
data_frame$col_name
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言 查找满足条件的数并获取索引的操作
1.在R语言中,如何找到满足条件的数呢? 例如给定一个向量c2,要求找到数值大于0的数: > c2 [1] 0.00 0.00 0.00 0.00 0.00 0.00 0.06 0.09 0.20 0.09 0.08 0.14 0.14 0.23 [15] 0.08 0.06 0.12 0.20 0.14 0.11 0.20 0.14 0.17 0.15 0.18 0.15 0.20 0.12 [29] 0.23 0.08 0.12 0.08 0.23 0.12 0.08 0.17 0.18 0
-

R语言 install.packages 无法读取索引的解决方案
问题描述 在公司的Centos服务器上安装R的包,总是安装不成功,然后有如下提醒: Warning: 无法在貯藏處https://mirrors.ustc.edu.cn/CRAN/src/contrib中读写索引 Warning message: package 'DBI' is not available (for R version 3.2.2) 问题修复 [更好的方案请直接看最后边PS] 执行下边这条命令,随便选几个源. setRepositories(addURLs = c(CRANxt
-
R语言:数据筛选match的使用详解
数据筛选是在分析中最常用的步骤,如微生物组分析中,你的OTU表.实验设计.物种注释之间都要不断筛选,来进行数据对齐,或局部分析. 今天来详解一下此函数的用法. match match:匹配两个向量,返回x中存在的返回索引或TRUE.FALSE match函数使用格式有如下两种: 第一种方便设置参数,返回x中元素在table中的位置 match(x, table, nomatch = NA_integer_, incomparables = NULL) 第二种简洁,返回x中每个元素在table中是
-
教你利用R语言测试电脑的性能
利用R语言测试电脑的性能如何 同事新配了一个电脑,想用R语言编写一个程序,看一下电脑性能如何,让我写个代码测试一下. 我能怎么样,我也不懂如何测试电脑啊,那就计算一下矩阵的运算吧.因为我理解的电脑运行性能就是矩阵计算了. 编写代码 rm(list=ls()) set.seed(123) # 设置矩阵的行数 n = 10000 # 生成一个矩阵 value = rnorm(n*n, 10,3) mat = matrix(value,n,n) # 测试电脑性能 system.time({ # 矩阵求
-
R语言ggplot2之图例的设置
引言 图例的设置包括移除图例.改变图例的位置.改变标签的顺序.改变图例的标题等. 移除图例 有时候你想移除图例,使用 guides(). library(ggplot2) p <- ggplot(PlantGrowth, aes(x=group, y=weight, fill=group)) + geom_boxplot() p + guides(fill=FALSE) 改变图例的位置 我们可以用theme(legend.position=-)将图例移到图表的上方.下方.左边和右边. p <-
-
R语言-解决处理矩阵遇到内存不足的问题
如下: Error : cannot allocate vector of size X Gb 类似于这种问题的可能处理办法: 1. 可以用matrix尽量不要用data frame; 2. 可以用integer matrix尽量不要用 double matrix; 3. 对于大量运算后最好加上一个gc(), 强制R语言回收内存: 4. 对于大矩阵而言用bigmemory包,可以将大矩阵放到临时文件中,不占用内存. 补充:R语言之内存管理 在处理大型数据过程中,R语言的内存管理就显得十分重要,以
-
R语言中文本文件分割 符号 sep的用法
一般情况下: csv 文件 sep = "," # 以逗号分割 txt 文件 sep = "\t" #以制表符分割 其他文件 sep = " " #以空格分割 具体情况,具体调整 sep= 文件中的字段分离符,用于文件数据文本的读取和保存过程中指定分割符号. 补充:用R语言把超大文本文件拆分成几个小文本文件 近一段时间一直在研究一些医院的数据. 前两天遇到一个尴尬:想打开一个仅有3G左右的文本文件(有时候必须要打开,直接传到数据库满足不了需求),
-
R语言数据框中的负索引介绍
以R语言自带的mtcars数据框为例: 这是原始的mtcars数据: 这里只列出了前面几行数据. 然后负索引mtcars[,-2:-3],得到的结果 删除了第二列和第三列数据 所以R语言数据框中的负索引是指删除数据框中对应的列(或者行) ps:这和Python里面的规则好像不太一样,Python里的负索引好像是指倒数第几列(或者第几行),这里这两个软件区别还挺大的~~写个笔记提醒一下自己~ 补充:R语言中的负整数索引 看代码吧~ > x<-matrix(c(1,2,3,4,5,6,7,8,9)
-
R语言数据框合并(merge)的几种方式小结
merge data frames (inner, outer, left, right) 数据 > df1 = data.frame(CustomerId = c(1:6), Product = c(rep("Toaster", 3), rep("Radio", 3))) > df1 > CustomerId Product 1 1 Toaster 2 2 Toaster 3 3 Toaster 4 4 Radio 5 5 Radio 6 6 R
-
R语言删除/添加数据框中的某一行/列
假如数据是这样的,这是有一个数据框 > A <- data.frame(姓名 = c("张三", "李四", "王五"), 体重 = c(50, 70, 80), 视力 = c(5.0, 4.8, 5.2)) > A 姓名 体重 视力 1 张三 50 5.0 2 李四 70 4.8 3 王五 80 5.2 删除第一行"张三"的信息 > A <- A[-1,] > A 姓名 体重 视力 2 李
-
R语言 实现将数据框中的字符类型数字转换为数值
场景1 我现在有一个数据框datexpr,里面的数字都是以字符型表示的,像这样 > datexpr[1,1] [1] " 1.143773961" 现在我想把这个数据框中的字符型数字全部转为数值型数字 使用下面语句即可 datexpr2=as.data.frame(lapply(datexpr,as.numeric)) 现在再次查看,就是数值型啦,整个数据框中的内容也都是数值型的啦 > datexpr2[1,1] [1] 1.143774 场景2 我现在有一个数据框date
-
R语言数据可视化学习之图形参数修改详解
1.图形参数的修改par()函数 我们可以通过使用par()函数来修改图形的参数,其调用格式为par(optionname=name, optionname=name,-).当par()不加参数时,返回当前图形参数设置的列表:par(no.readonly=T)将生成一个可以修改当前参数设置的列表.注意以这种方式修改参数设置,除非参数再次被修改,否则一直执行此参数设置. 例如现在想画出mtcars数据集中mpg的折线图,并用虚线代替实线,并将两幅图排列在同一幅图里,代码及图形如下: > opar
-
详解R语言数据合并一行代码搞定
数据的合并 需要的函数 cbind(),rbind(),bind_rows(),merge() 准备数据 我们先构造一组数据,以便下面的演示 > data1<-data.frame( + namea=c("海波","立波","秀波"), + value=c("一波","接","一波") + ) > data1 namea value 1 海波 一波 2 立波 接 3 秀
-
R语言 数据表匹配和拼接 merge函数的使用
R中的merge函数类似于Excel中的Vlookup,可以实现对两个数据表进行匹配和拼接的功能. merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), incomparables = NULL, ...) x,y:用于合并的两个
-
R语言数据可视化ggplot添加左右y轴绘制天猫双十一销售图
目录 构造数据集 绘制散点 修改两坐标轴信息 本文是以天猫双十一销量与增长率为例,原始的数据可以参考上一篇文章:用 ggplot 重绘天猫双十一销售额图,这里不再作过多的介绍. 同时整个的天猫双十一的销售额数据分析可以关注:天猫双十一"数据造假"是真的吗? 老规矩,先上最终成果(两张图只是颜色的差别): 上图左边 y 轴表示增长率的刻度,右边 y 轴表示销售额的数据,我们将两者在同一张图上进行展现.其实将两个统计图在同一个坐标系中呈现不算是这个绘图的难点,其真正的难点在与刻度的变换以及
-
R语言数据建模流程分析
目录 Intro 项目背景 前期准备 数据描述 数据清洗 预分析及预处理 数值型数据 类别型数据 特征 Boruta算法 建模 模型对比 Intro 近期在整理数据分析流程,找到了之前写的一篇代码,分享给大家.这是我上学时候做的一个项目,当时由于经验不足产生了一些问题,这些问题会在之后一点一点给大家讨论,避免各位踩坑.本篇分享会带一些讲解,可能有些地方不够清楚,欢迎留言讨论. 本次除了分享之外也是对自己之前项目的一个复盘.还是使用R语言(毕竟是我钟爱的语言).Python的如果有需求之后会放别的
-
R语言数据重塑知识点总结
R 语言中的数据重塑是关于改变数据被组织成行和列的方式. 大多数时间 R 语言中的数据处理是通过将输入数据作为数据帧来完成的. 很容易从数据帧的行和列中提取数据,但是在某些情况下,我们需要的数据帧格式与我们接收数据帧的格式不同. R 语言具有许多功能,在数据帧中拆分,合并和将行更改为列,反之亦然. 于数据帧中加入列和行 我们可以使用 cbind() 函数连接多个向量来创建数据帧. 此外,我们可以使用 rbind() 函数合并两个数据帧. # Create vector objects. city