用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈。
今天分享个如何简单处理滑动图片的验证码的案例。

类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别。同时也能拦截掉大部分初级爬虫。
作为一只python爬虫,如何正确地自动完成这个验证过程呢?
先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium等工具完成拖动的操作。
我们可以借用opencv来解决这个问题,主要步骤:

opencv 是什么?
OpenCV(Open Source Computer Vision Library)是开放源代码计算机视觉库,主要算法涉及图像处理、计算机视觉和机器学习相关方法,可用于开发实时的图像处理、计算机视觉以及模式识别程序。
直接安装

首先将图片进行高斯模糊处理,高斯模糊的主要作用是减少图像的噪声,用于预处理阶段。

处理后的效果

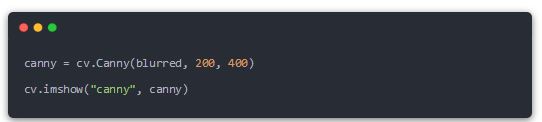
接着用Canny边缘检测到得到一个包含“窄边界”的二值图像。所谓二值图像就是黑白图,只有黑色和白色。
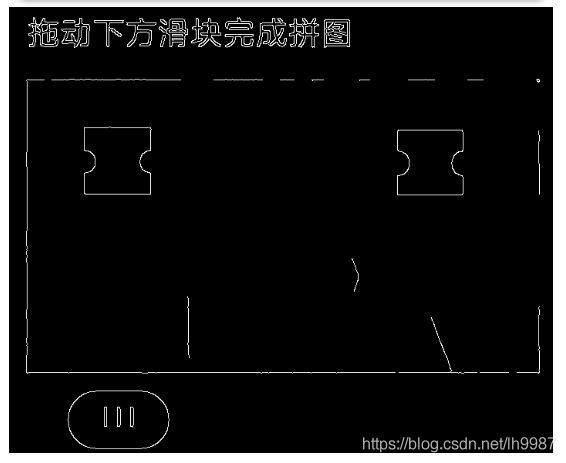
轮廓检测

找出所有的轮廓,并用红色线框将其绘制标识出来了,看出来大大小小有几十个轮廓

剩下的问题就好办了,我们只需要对轮廓的面积或者周长范围做限制,就能过滤出目标轮廓的位置, 前提是我们对目标位置的轮廓大小是预先确定的。

轮廓的面积大概是6000到8000之间,周长在300到500之间, 最后用外接矩形获取该轮廓图的坐标位置和宽高大小。

如上就找到了目标位置,剩下的工作就是将滑块移动到指定位置即可
到此这篇关于用Python爬虫破解滑动验证码的案例解析的文章就介绍到这了,更多相关Python爬虫破解滑动验证码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python验证码识别教程之滑动验证码
前言 上篇文章记录了2种分割验证码的方法,此外还有一种叫做"滴水算法"(Drop Fall Algorithm)的方法,但本人智商原因看这个算法看的云里雾里的,所以今天记录滑动验证码的处理吧.网上据说有大神已经破解了滑动验证码的算法,可以不使用selenium来破解,但本人能力不足还是使用笨方法吧. 基础原理很简单,首先点击验证码按钮后的图片是滑动后的完整结果,点击一下滑块后会出现拼图,对这2个分别截图后比较像素值来找出滑动距离,并结合selenium来实现拖拽效果. 至于seleni
-
Python3网络爬虫开发实战之极验滑动验证码的识别
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级,本节来讲解下极验验证码的识别过程. 1. 本节目标 本节我们的目标是用程序来识别并通过极验验证码的验证,其步骤有分析识别思路.识别缺口位置.生成滑块拖动路径,最后模拟实现滑块拼合通过验证. 2. 准备工作 本次我们使用的 Python 库是 Selen
-

Python 200行代码实现一个滑动验证码过程详解
前言 做网络爬虫的同学肯定见过各种各样的验证码,比较高级的有滑动.点选等样式,看起来好像挺复杂的,但实际上它们的核心原理还是还是很清晰的,本文章大致说明下这些验证码的原理以及带大家实现一个滑动验证码. 实际上这类验证码的校验是分为两个步骤的: 1.第一步就是前端的校验.一般来说,登录注册页面在点击提交的时候都会伴随着一个表单提交,在表单提交的时候会有 JavaScript 事件的触发.如果加入了验证码,那么在表单提交的时候会多加一个额外的验证,判断这个验证码是否已经成功完成了操作.如果没有的话,
-
Python3爬虫关于识别检验滑动验证码的实例
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级,本节来讲解下极验验证码的识别过程. 1. 本节目标 本节我们的目标是用程序来识别并通过极验验证码的验证,其步骤有分析识别思路.识别缺口位置.生成滑块拖动路径,最后模拟实现滑块拼合通过验证. 2. 准备工作 本次我们使用的 Python 库是 Selen
-
使用Python的OpenCV模块识别滑动验证码的缺口(推荐)
最近终于找到一个好的方法,使用Python的OpenCV模块识别滑动验证码的缺口,可以将滑动验证码中的缺口识别出来了. 测试使用如下两张图片: target.jpg template.png 现在想要通过"template.png"在"target.jpg"中找到对应的缺口,代码实现如下: # encoding=utf8 import cv2 import numpy as np def show(name): cv2.imshow('Show', name) cv
-
python爬虫之验证码篇3-滑动验证码识别技术
滑动验证码介绍 本篇涉及到的验证码为滑动验证码,不同于极验证,本验证码难度略低,需要的将滑块拖动到矩形区域右侧即可完成. 这类验证码不常见了,官方介绍地址为:https://promotion.aliyun.com/ntms/act/captchaIntroAndDemo.html 使用起来肯定是非常安全的了,不是很好通过机器检测 如何判断验证码类型 这个验证码的标识一般比较明显,在页面源码中一般存在一个 nc.js 基本可以判定是阿里云的验证码了 <script type="text/j
-
用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈. 今天分享个如何简单处理滑动图片的验证码的案例. 类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别.同时也能拦截掉大部分初级爬虫. 作为一只python爬虫,如何正确地自动完成这个验证过程呢? 先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium
-
基于python实现破解滑动验证码过程解析
前言: 很多小伙伴们反馈,在web自动化的过程中,经常会被登录的验证码给卡住,不知道如何去通过验证码的验证.今天专门给大家来聊聊验证码的问题,一般的情况下遇到验证码我们可以都可以找开发去帮忙解决,关闭验证码,或者给一个万能的验证码!那么如果开发不提供帮助的话,我们自己有没有办法来处理这些验证码的问题呢?答案当然是有的,常见的验证码一般分为两类,一类是图文验证码,一类是滑动验证码! 今天我们主要来聊聊滑动验证码如何去识别破解. 滑动验证破解思路 关于滑动验证码破解的思路大体上来讲就是以下两个步骤:
-
python自动化测试之破解滑动验证码
在Web自动化测试的过程中,经常会被登录的验证码给卡住,不知道如何去通过验证码的验证.一般的情况下遇到验证码我们可以都可以找开发去帮忙解决,关闭验证码,或者给一个万能的验证码!那么如果开发不提供帮助的话,我们自己有没有办法来处理这些验证码的问题呢?答案当然是有的,常见的验证码一般分为两类,一类是图文验证码,一类是滑动验证码! 滑动验证破解思路 关于滑动验证码破解的思路大体上来讲就是以下两个步骤: 1.获取滑块滑动的距离 2.模拟拖动滑块,通过验证. 关于这种滑动的验证码,滑块和缺口背景都是分别是
-
python爬虫破解字体加密案例详解
本次案例以爬取起小点小说为例 案例目的: 通过爬取起小点小说月票榜的名称和月票数,介绍如何破解字体加密的反爬,将加密的数据转化成明文数据. 程序功能: 输入要爬取的页数,得到每一页对应的小说名称和月票数. 案例分析: 找到目标的url: (右键检查)找到小说名称所在的位置: 通过名称所在的节点位置,找到小说名称的xpath语法: (右键检查)找到月票数所在的位置: 由上图发现,检查月票数据的文本,得到一串加密数据. 我们通过xpathhelper进行调试发现,无法找到加密数据的语法.因此,需要通
-
python绕过图片滑动验证码实现爬取PTA所有题目功能 附源码
最近学了python爬虫,本着学以致用的态度去应用在生活中.突然发现算法的考试要来了,范围就是PTA刷过的题.让我一个个复制粘贴?不可能,必须爬它! 先开页面,人傻了,PTA的题目是异步加载的,爬了个寂寞(空数据).AJAX我又不熟,突然想到了selenium. selenium可以模拟人的操作让浏览器自动执行动作,具体的自己去了解,不多说了.干货来了: 登录界面有个图片的滑动验证码 破解它的最好方式就是用opencv,opencv巨强,自己了解. 思路开始: 1.将背景图片和可滑动的图片下载
-
Python Selenium破解滑块验证码最新版(GEETEST95%以上通过率)
一.滑块验证码简述 有爬虫,自然就有反爬虫,就像病毒和杀毒软件一样,有攻就有防,两者彼此推进发展.而目前最流行的反爬技术验证码,为了防止爬虫自动注册,批量生成垃圾账号,几乎所有网站的注册页面都会用到验证码技术.其实验证码的英文为 CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart),翻译成中文就是全自动区分计算机和人类的公开图灵测试,它是一种可以区分用户是计算机还是人的测试,只要能通
-
Python爬虫破解登陆哔哩哔哩的方法
写在前面 作为一名找不到工作的爬虫菜鸡人士来说,登陆这一块肯定是个比较大的难题. 从今天开始准备一点点对大型网站进行逐个登陆破解.加深自己爬虫水平. 环境搭建 Python 3.7.7环境,Mac电脑测试 Python内置库 第三方库:rsa.urllib.requests PC端登陆 全部代码: '''PC登录哔哩哔哩''' class Bilibili_For_PC(): def __init__(self, **kwargs): for key, value in kwargs.item
-
Python爬虫之Scrapy环境搭建案例教程
Python爬虫之Scrapy环境搭建 如何搭建Scrapy环境 首先要安装Python环境,Python环境搭建见:https://blog.csdn.net/alice_tl/article/details/76793590 接下来安装Scrapy 1.安装Scrapy,在终端使用pip install Scrapy(注意最好是国外的环境) 进度提示如下: alicedeMacBook-Pro:~ alice$ pip install Scrapy Collecting Scrapy Usi
-
Python+selenium破解拼图验证码的脚本
目录 实现思路 核心代码 实现思路 很多网站都有拼图验证码 1.首先要了解拼图验证码的生成原理 2.制定破解计划,考虑其可能性和成功率. 3.编写脚本 很多网站的拼图验证码都是直接借助第三方插件,也就是一类一种解法. 笔者遇到的这种拼图验证码实际上是多个小碎片经过重新组合成的一张整体,首先要在网站上抓取这种小碎片图片并下载到本地 我们先捋一捋大体思路: 获取所有碎片图片----找出他们的排列顺序逻辑-----找出他们中含有颜色深的真正位置的那个小碎块的序号-----根据每块碎片的宽度和上下和这个
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http