深度学习小工程练习之tensorflow垃圾分类详解
介绍
这是一个基于深度学习的垃圾分类小工程,用深度残差网络构建
软件架构
- 使用深度残差网络resnet50作为基石,在后续添加需要的层以适应不同的分类任务
- 模型的训练需要用生成器将数据集循环写入内存,同时图像增强以泛化模型
- 使用不包含网络输出部分的resnet50权重文件进行迁移学习,只训练我们在5个stage后增加的层
安装教程
- 需要的第三方库主要有tensorflow1.x,keras,opencv,Pillow,scikit-learn,numpy
- 安装方式很简单,打开terminal,例如:pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
- 数据集与权重文件比较大,所以没有上传
- 如果环境配置方面有问题或者需要数据集与模型权重文件,可以在评论区说明您的问题,我将远程帮助您
使用说明
- 文件夹theory记录了我在本次深度学习中收获的笔记,与模型训练的控制台打印信息
- 迁移学习需要的初始权重与模型定义文件resnet50.py放在model
- 下训练运行trainNet.py,训练结束会创建models文件夹,并将结果权重garclass.h5写入该文件夹
- datagen文件夹下的genit.py用于进行图像预处理以及数据生成器接口
- 使用训练好的模型进行垃圾分类,运行Demo.py
结果演示
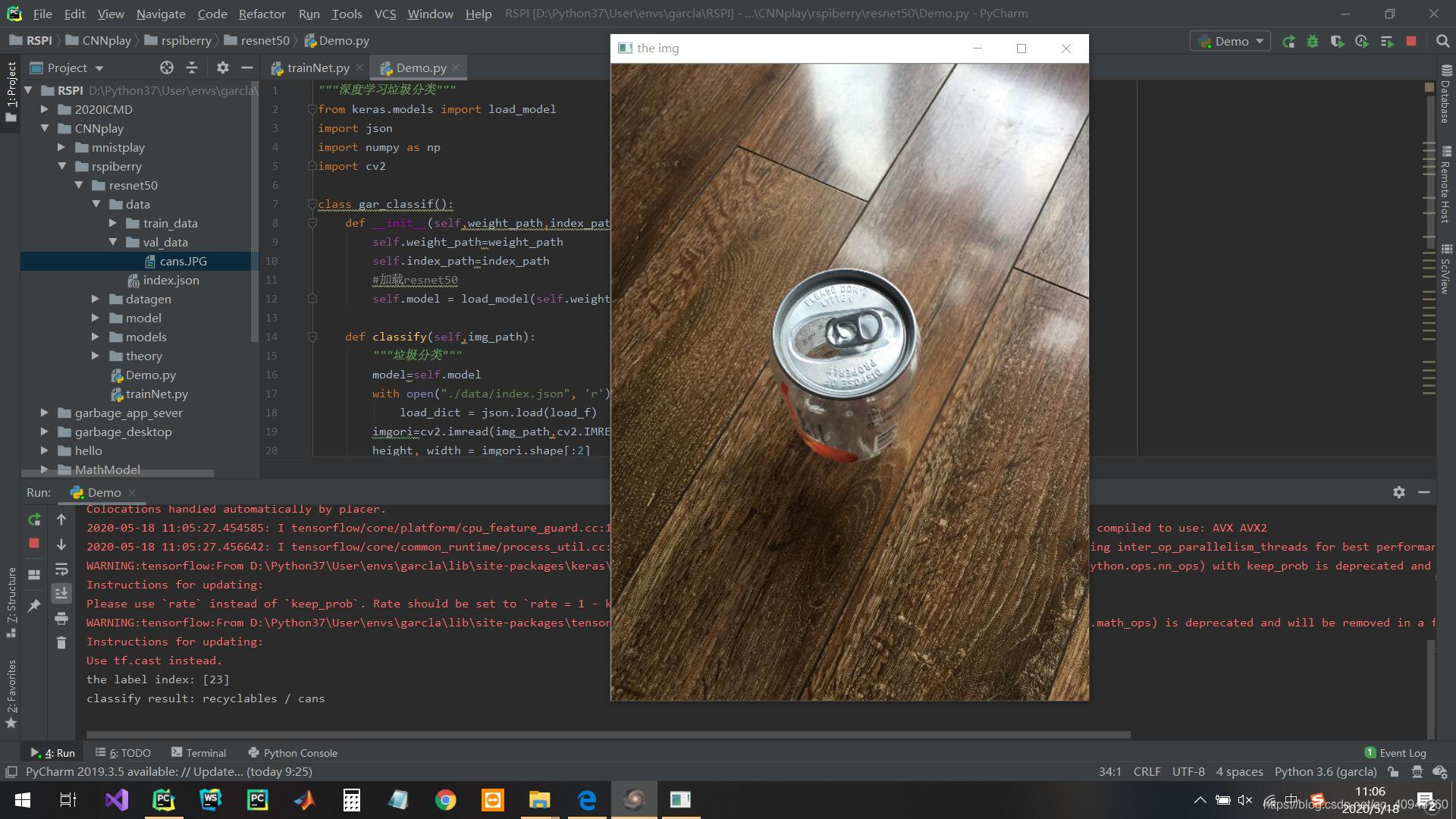
cans易拉罐
代码解释
在实际的模型中,我们只使用了resnet50的5个stage,后面的输出部分需要我们自己定制,网络的结构图如下:

stage5后我们的定制网络如下:
"""定制resnet后面的层"""
def custom(input_size,num_classes,pretrain):
# 引入初始化resnet50模型
base_model = ResNet50(weights=pretrain,
include_top=False,
pooling=None,
input_shape=(input_size,input_size, 3),
classes=num_classes)
#由于有预权重,前部分冻结,后面进行迁移学习
for layer in base_model.layers:
layer.trainable = False
#添加后面的层
x = base_model.output
x = layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = layers.Dropout(0.5,name='dropout1')(x)
#regularizers正则化层,正则化器允许在优化过程中对层的参数或层的激活情况进行惩罚
#对损失函数进行最小化的同时,也需要让对参数添加限制,这个限制也就是正则化惩罚项,使用l2范数
x = layers.Dense(512,activation='relu',kernel_regularizer= regularizers.l2(0.0001),name='fc2')(x)
x = layers.BatchNormalization(name='bn_fc_01')(x)
x = layers.Dropout(0.5,name='dropout2')(x)
#40个分类
x = layers.Dense(num_classes,activation='softmax')(x)
model = Model(inputs=base_model.input,outputs=x)
#模型编译
model.compile(optimizer="adam",loss = 'categorical_crossentropy',metrics=['accuracy'])
return model
网络的训练是迁移学习过程,使用已有的初始resnet50权重(5个stage已经训练过,卷积层已经能够提取特征),我们只训练后面的全连接层部分,4个epoch后再对较后面的层进行训练微调一下,获得更高准确率,训练过程如下:
class Net():
def __init__(self,img_size,gar_num,data_dir,batch_size,pretrain):
self.img_size=img_size
self.gar_num=gar_num
self.data_dir=data_dir
self.batch_size=batch_size
self.pretrain=pretrain
def build_train(self):
"""迁移学习"""
model = resnet.custom(self.img_size, self.gar_num, self.pretrain)
model.summary()
train_sequence, validation_sequence = genit.gendata(self.data_dir, self.batch_size, self.gar_num, self.img_size)
epochs=4
model.fit_generator(train_sequence,steps_per_epoch=len(train_sequence),epochs=epochs,verbose=1,validation_data=validation_sequence,
max_queue_size=10,shuffle=True)
#微调,在实际工程中,激活函数也被算进层里,所以总共181层,微调是为了重新训练部分卷积层,同时训练最后的全连接层
layers=149
learning_rate=1e-4
for layer in model.layers[:layers]:
layer.trainable = False
for layer in model.layers[layers:]:
layer.trainable = True
Adam =adam(lr=learning_rate, decay=0.0005)
model.compile(optimizer=Adam, loss='categorical_crossentropy', metrics=['accuracy'])
model.fit_generator(train_sequence,steps_per_epoch=len(train_sequence),epochs=epochs * 2,verbose=1,
callbacks=[
callbacks.ModelCheckpoint('./models/garclass.h5',monitor='val_loss', save_best_only=True, mode='min'),
callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.1,patience=10, mode='min'),
callbacks.EarlyStopping(monitor='val_loss', patience=10),],
validation_data=validation_sequence,max_queue_size=10,shuffle=True)
print('finish train,look for garclass.h5')
训练结果如下:
"""
loss: 0.7949 - acc: 0.9494 - val_loss: 0.9900 - val_acc: 0.8797
训练用了9小时左右
"""
如果使用更好的显卡,可以更快完成训练
最后
希望大家可以体验到深度学习带来的收获,能和大家学习很开心,更多关于深度学习的资料请关注我们其它相关文章!
相关推荐
-

吴恩达机器学习练习:神经网络(反向传播)
1 Neural Networks 神经网络 1.1 Visualizing the data 可视化数据 这部分我们随机选取100个样本并可视化.训练集共有5000个训练样本,每个样本是20*20像素的数字的灰度图像.每个像素代表一个浮点数,表示该位置的灰度强度.20×20的像素网格被展开成一个400维的向量.在我们的数据矩阵X中,每一个样本都变成了一行,这给了我们一个5000×400矩阵X,每一行都是一个手写数字图像的训练样本. import numpy as np import matpl
-
深度学习详解之初试机器学习
机器学习可应用在各个方面,本篇将在系统性进入机器学习方向前,初步认识机器学习,利用线性回归预测波士顿房价: 原理简介 利用线性回归最简单的形式预测房价,只需要把它当做是一次线性函数y=kx+b即可.我要做的就是利用已有数据,去学习得到这条直线,有了这条直线,则对于某个特征x(比如住宅平均房间数)的任意取值,都可以找到直线上对应的房价y,也就是模型的预测值. 从上面的问题看出,这应该是一个有监督学习中的回归问题,待学习的参数为实数k和实数b(因为就只有一个特征x),从样本集合sample中取出一对
-
深度学习tensorflow基础mnist
软件架构 mnist数据集的识别使用了两个非常小的网络来实现,第一个是最简单的全连接网络,第二个是卷积网络,mnist数据集是入门数据集,所以不需要进行图像增强,或者用生成器读入内存,直接使用简单的fit()命令就可以一次性训练 安装教程 使用到的主要第三方库有tensorflow1.x,基于TensorFlow的Keras,基础的库包括numpy,matplotlib 安装方式也很简答,例如:pip install numpy -i https://pypi.tuna.tsinghua.edu
-
机器深度学习二分类电影的情感问题
二分类问题可能是应用最广泛的机器学习问题.今天我们将学习根据电影评论的文字内容将其划分为正面或负面. 一.数据集来源 我们使用的是IMDB数据集,它包含来自互联网电影数据库(IMDB)的50000条严重两极分化的评论.为了避免模型过拟合只记住训练数据,我们将数据集分为用于训练的25000条评论与用于测试的25000条评论,训练集和测试集都包含50%的正面评论和50%的负面评论. 与MNIST数据集一样,IMDB数据集也内置于Keras库.它已经过预处理:评论(单词序列)已经被转换为整数序列,其中
-
深度学习小工程练习之tensorflow垃圾分类详解
介绍 这是一个基于深度学习的垃圾分类小工程,用深度残差网络构建 软件架构 使用深度残差网络resnet50作为基石,在后续添加需要的层以适应不同的分类任务 模型的训练需要用生成器将数据集循环写入内存,同时图像增强以泛化模型 使用不包含网络输出部分的resnet50权重文件进行迁移学习,只训练我们在5个stage后增加的层 安装教程 需要的第三方库主要有tensorflow1.x,keras,opencv,Pillow,scikit-learn,numpy 安装方式很简单,打开terminal,例
-
Python深度学习之图像标签标注软件labelme详解
前言 labelme是一个非常好用的免费的标注软件,博主看了很多其他的博客,有的直接是翻译稿,有的不全面.对于新手入门还是有点困难.因此,本文的主要是详细介绍labelme该如何使用. 一.labelme是什么? labelme是图形图像注释工具,它是用Python编写的,并将Qt用于其图形界面.说直白点,它是有界面的, 像软件一样,可以交互,但是它又是由命令行启动的,比软件的使用稍微麻烦点.其界面如下图: 它的功能很多,包括: 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目
-
PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
Python深度学习实战PyQt5布局管理项目示例详解
目录 1. 从绝对定位到布局管理 1.1 什么是布局管理 1.2 Qt 中的布局管理方法 2. 水平布局(Horizontal Layout) 3. 垂直布局(Vertical Layout) 4. 栅格布局(Grid Layout) 5. 表格布局(Form Layout) 6. 嵌套布局 7. 容器布局 布局管理就是管理图形窗口中各个部件的位置和排列.图形窗口中的大量部件也需要通过布局管理,对部件进行整理分组.排列定位,才能使界面整齐有序.美观大方. 1. 从绝对定位到布局管理 1.1 什么
-
TensorFlow人工智能学习张量及高阶操作示例详解
目录 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 2.tf.clip_by_norm() 二.张量排序 1.tf.sort/argsort() 2.tf.math.topk() 三.TensorFlow高阶操作 1.tf.where() 2.tf.scatter_nd() 3.tf.meshgrid() 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 该方法按数值裁剪,传入tensor和阈值,maximum是把数
-
OpenCV学习之图像的分割与修复详解
目录 背景 一.分水岭法 二.GrabCut法 三.MeanShift法 四.MOG前景背景分离法 五.拓展方法 六.图像修复 总结 背景 图像分割本质就是将前景目标从背景中分离出来.在当前的实际项目中,应用传统分割的并不多,大多是采用深度学习的方法以达到更好的效果:当然,了解传统的方法对于分割的整体认知具有很大帮助,本篇将介绍些传统分割的一些算法: 一.分水岭法 原理图如下: 利用二值图像的梯度关系,设置一定边界,给定不同颜色实现分割: 实现步骤: 标记背景 —— 标记前景 —— 标记未知区域
-
微信小程序组件之srcoll-view的详解
微信小程序组件之srcoll-view的详解 今天记录一下scroll-view学习中遇到的问题及解决办法,希望能对其他同学有所帮助. 首先展示一下想达到的效果.↓ vertical scroll实现上下滚动,horizontal实现左右滚动. 先附上wxml的代码. <view class="container"> <view> <text>vertical scroll</text> <scroll-view scroll-y
-
微信小程序switch开关选择器使用详解
本文为大家分享了微信小程序switch开关选择器使用方法,供大家参考,具体内容如下 效果图 WXML <view class="tui-list-box"> <view class="tui-menu-list"> <text>状态:{{isChecked1}}</text> <switch class="tui-fr" checked="{{isChecked1}}" b
-
微信小程序数字滚动插件使用详解
用es6语法方式写了个微信小程序小插件–数字滚动: 效果图: wxml页面布局代码: <!--pages/main/index.wxml--><view class="animate-number"> <view class="num num1">{{num1}}{{num1Complete}}</view> <view class="num num2">{{num2}}{{num2Co
-
python3爬虫学习之数据存储txt的案例详解
上一篇实战爬取知乎热门话题的实战,并且保存为本地的txt文本 先上代码,有很多细节和坑需要规避,弄了两个半小时 import requests import re headers = { "user-agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64)" " AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari" &quo