Python中X[:,0]和X[:,1]的用法
X[:,0]是numpy中数组的一种写法,表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据,直观来说,X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据。
举例说明:
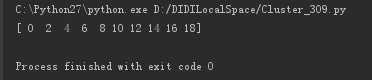
import numpy as np X = np.array([[0,1],[2,3],[4,5],[6,7],[8,9],[10,11],[12,13],[14,15],[16,17],[18,19]]) print X[:,0]
X[:,0]输出结果是:
import numpy as np X = np.array([[0,1],[2,3],[4,5],[6,7],[8,9],[10,11],[12,13],[14,15],[16,17],[18,19]]) print X[:,1]
X[:,1]输出结果是:

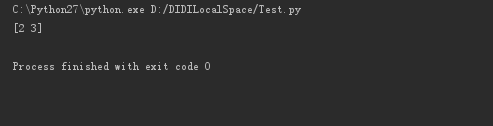
X[n,:]是取第1维中下标为n的元素的所有值。
X[1,:]即取第一维中下标为1的元素的所有值,输出结果:
X[:, m:n],即取所有数据的第m到n-1列数据,含左不含右
例:输出X数组中所有行第1到2列数据
X = np.array([[0,1,2],[3,4,5],[6,7,8],[9,10,11],[12,13,14],[15,16,17],[18,19,20]]) print X[:,1:3]
输出结果:

补充:python中的[1:]、[::-1]、X[:,m:n]和X[1,:]
Python中的[1:]
意思是去掉列表中第一个元素(下标为0),去后面的元素进行操作,以一个示例题为例,用在遍历中统计个数:
题:读入N名学生的成绩,将获得某一给定分数的学生人数输出。
输入格式:
输入在第1行给出不超过10^5^的正整数N,即学生总人数。随后1行给出N名学生的百分制整数成绩,中间以空格分隔。最后1行给出要查询的分数个数K(不超过N的正整数),随后是K个分数,中间以空格分隔。
输出格式:
在一行中按查询顺序给出得分等于指定分数的学生人数,中间以空格分隔,但行末不得有多余空格。
stu_num = input('请输入学生总人数:')
stu_grade = input('请输入每位学生的成绩(百分制),并以空格分开:').split() # 将如数的字符串转化成列表
num_and_grade = input('请输入要统计几个分数,以及每个分数值,以空格分开:').split() # 转成列表格式
result = [] # 定义一个新列表保存结果
for i in num_and_grade[1:]: # 定义变量i,遍历num_and_grade[]列表中除了第一个元素的其他元素
result.append(str(stu_grade.count(i))) # 利用Python的count()函数统计相应i值在列表stu_grade[]列表中的个数,转换成字符串格式并追加到result[]列表中
print(" ".join(result)) # 列表转换成字符串格式,打印结果
结果:
请输入学生总人数:10
请输入每位学生的成绩(百分制),并以空格分开:88 99 75 88 95 42 78 88 95 99
请输入要统计几个分数,以及每个分数值,以空格分开:3 88 99 95
3 2 2
Python中的[::-1]
这个是python的slice notation的特殊用法。
b = a[i:j] 表示复制a[i]到a[j-1],以生成新的list对象
当i缺省时,默认为0,即 a[:3]相当于 a[0:3]
当j缺省时,默认为len(alist), 即a[1:]相当于a[1:10]
当i,j都缺省时,a[:]就相当于完整复制一份a了
b = a[i:j:s]这种格式呢,i,j与上面的一样,但s表示步进,缺省为1.
所以a[i:j:1]相当于a[i:j]
当s<0时:i缺省时,默认为-1; j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。
a = ['a','b','c','d','e','f','g','h','g','k','l','m'] b = a[:] # 列表切片,表示把列表a[]的值全部正序复制到列表b[]中 print(b) # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'g', 'k', 'l', 'm'] # b = a[n:m]表示列表切片,复制列表a[n]到a[m-1]的内容到新的列表对象b[] # 当n缺省时,默认为0,即a[:m] # 当m缺省时,默认到最后,即a[n:] b1 = a[1:4] print(b1) # ['b', 'c', 'd'] b2 = a[:3] print(b2) # ['a', 'b', 'c'] b3 = a[1:] print(b3) # ['b', 'c', 'd', 'e', 'f', 'g', 'h', 'g', 'k', 'l', 'm'] # b = a[i:j:s]这种格式呢,i,j与上面的一样,但s表示步进,缺省为1,s可以取任何数字. # 所以a[i:j:1]相当于a[i:j] b4 = a[1:5:2] print(b4) # ['b', 'd'] b5 = a[:5:-1] # 从末尾倒数取值 print(b5) # ['m', 'l', 'k', 'g', 'h', 'g'] b6 = a[5::-2] print(b6) # 从a[n]处倒数取值 b7 = a[::-1] # 到这取值 print(b7) # ['m', 'l', 'k', 'g', 'h', 'g', 'f', 'e', 'd', 'c', 'b', 'a']
输出结果:
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'g', 'k', 'l', 'm']
['b', 'c', 'd']
['a', 'b', 'c']
['b', 'c', 'd', 'e', 'f', 'g', 'h', 'g', 'k', 'l', 'm']
['b', 'd']
['m', 'l', 'k', 'g', 'h', 'g']
['f', 'd', 'b']
['m', 'l', 'k', 'g', 'h', 'g', 'f', 'e', 'd', 'c', 'b', 'a']
Python中的X[:,m:n]和X[1,:]
X[:,0]是numpy中数组的一种写法,表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据,直观来说,X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据。
X[n,:]是取第1维中下标为n的元素的所有值。
X[:, m:n],即取所有数据的第m到n-1列数据,含左不含右
import numpy as np X = np.array([[0,1,2,3],[4,5,6,7],[8,9,10,11],[12,13,14,15]]) # 定义二维数组 print(X[:,0]) # 取数组X二维数组中每一个的0号下标对应的值 [0 4 8 12] print(X[1,:]) # 取数组X一维数组中的第一组全部数值 [0 1 2 3] print(X[:,1:3]) #取所有数据的第1列到3-1列数据,从第0列开始计算,结果如下: ''' [[1 2] [5 6] [9 10] [13 14]] '''
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
python面试题Python2.x和Python3.x的区别
下面看下python2.x和python3.x的区别 1.大环境不同 python2.x:源码重复,不规范 python3.x:整合源码,更清晰优美简单 2.默认编码不同 python2.x:默认编码ASCII编码 python3.x:默认编码UTF-8 3.python3.x没有长整型 python2.x:有长整型long python3.x:long整数类型被废弃,统一为int 4.打印方式不同 python2.x:print语句,print空格+打印内容 python3.x:print()
-
Python中的X[:,0]、X[:,1]、X[:,:,0]、X[:,:,1]、X[:,m:n]和X[:,:,m:n]
Python中对于数组和列表进行切片操作是很频繁的,当然对于切片的操作可供我们直接使用的函数也是很遍历了,我们今天主要简单总结一下常用集中索引化方式,希望对大家有所帮助吧. 对于列表的切片比较简单,在我之前的博客里面有详细的讲解,需要的话可以去看看,这里就不再详细说了,今天主要是讲解对于Python中Array对象的操作,我们平时使用比较频繁的一般也就是三维的矩阵了,再高维度的处理方式是相同的,这里我们只讲解三维和二维的使用. 对于X[:,0]; 是取二维数组中第一维的所有数据 对于X[:,1]
-
Python2.x与Python3.x的区别
Python的3.0版本,常被称为Python 3000,或简称Py3k.相对于Python的早期版本,这是一个较大的升级. 为了不带入过多的累赘,Python 3.0在设计的时候没有考虑向下相容. 许多针对早期Python版本设计的程式都无法在Python 3.0上正常执行. 为了照顾现有程式,Python 2.6作为一个过渡版本,基本使用了Python 2.x的语法和库,同时考虑了向Python 3.0的迁移,允许使用部分Python 3.0的语法与函数. 新的Python程式建议使用P
-
![Python中X[:,0]和X[:,1]的用法](/assets/blank.gif)
Python中X[:,0]和X[:,1]的用法
X[:,0]是numpy中数组的一种写法,表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据,直观来说,X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据. 举例说明: import numpy as np X = np.array([[0,1],[2,3],[4,5],[6,7],[8,9],[10,11],[12,13],[14,15],[16,17],[18,19]]) print X[:,0] X[:,0]输出结果是: import nu
-
Python中的异常处理try/except/finally/raise用法分析
本文实例分析了Python中的异常处理try/except/finally/raise用法.分享给大家供大家参考,具体如下: 异常发生在程序执行的过程中,如果python无法正常处理程序就会发生异常,导致整个程序终止执行,python中使用try/except语句可以捕获异常. try/except 异常的种类有很多,在不确定可能发生的异常类型时可以使用Exception捕获所有异常: try: pass except Exception, e: print Exception, ":"
-
Python中字典与恒等运算符的用法分析
本文实例讲述了Python中字典与恒等运算符的用法.分享给大家供大家参考,具体如下: 字典 字典是可变数据类型,其中存储的是唯一键到值的映射. elements = {"hydrogen": 1, "helium": 2, "carbon": 6} 字典的键可以是任何不可变类型,例如整数或元组,而不仅仅是字符串.甚至每个键都不一定要是相同的类型! print(elements["helium"]) # 2 我们可以使用方括号并
-
python中的 zip函数详解及用法举例
python中zip()函数用法举例 定义:zip([iterable, ...]) zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表).若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同.利用*号操作符,可以将list unzip(解压),看下面的例子就明白了: 示例1 x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] x
-
Python中使用Lambda函数的5种用法
引言 Lambda 函数(也称为匿名函数)是函数式编程中的核心概念之一. 支持多编程范例的 Python 也提供了一种简单的方法来定义 lambda 函数. 用 Python 编写 lambda 函数的模板是: lambda arguments : expression 它包括三个部分: · Lambda 关键字 · 函数将接收的参数 · 结果为函数返回值的表达式 由于它的简单性,lambda 函数可以使我们的 Python 代码在某些使用场景中更加优雅.这篇文章将演示在 Python 中 la
-
Python中最好用的json库orjson用法详解
目录 1 简介 2 orjson常用方法 2.1 序列化 2.2 反序列化 2.3 丰富的option选项 2.4 针对dataclass.datetime添加自定义处理策略 总结 1 简介 大家好,我们在日常使用 Python 的过程中,经常会使用 json 格式存储一些数据,尤其是在 web 开发中.而 Python 原生的 json 库性能差.功能少,只能堪堪应对简单轻量的 json 数据存储转换需求. 而本文我要给大家介绍的第三方 json 库 orjson ,在公开的各项基准性能测试中
-
Python中的枚举函数enumerate()的具体用法
相比于range,list等简易单词,enumerate仅凭外形都不太让人愿意用.事实上,enumerate还是很好用的. enumerate()是python的内置函数.适用于python2.x和python3.x enumerate在字典上是枚举.列举的意思 enumerate参数为可遍历/可迭代的对象(如列表.字符串) enumerate多用于在for循环中得到计数,利用它可以同时获得索引和值,即需要index和value值的时候可以使用enumerate enumerate()返回的是一
-
python中Requests请求的安装与常见用法
目录 一.requests 二.requests安装方式 三.说说常见的两种请求,get和post 1.get请求 2.post请求 四.requests发送请求 五.response 补充:requests中遇到问题 总结 一.requests request的说法网上有很多,简单来说就是就是python里的很强大的类库,可以帮助你发很多的网络请求,比如get,post,put,delete等等,这里最常见的应该就是get和post 二.requests安装方式 $ pip install r
-
python中map、any、all函数用法分析
本文实例讲述了python中map.any.all函数用法.分享给大家供大家参考.具体分析如下: 最近想学python,就一直比较关注python,昨天在python吧看到有个帖子提问怎么在python中怎么判断密码是否符合规范,回帖中有很多用循环的,除此外还有一个没有用循环,代码非常简练,下面是代码: def volid(pwd): a = any(map(str.isupper,pwd)) b = any(map(str.islower,pwd)) c = any(map(str.isdig
-
对Python中class和instance以及self的用法详解
一. Python 的类和实例 在面向对象中,最重要的概念就是类(class)和实例(instance),类是抽象的模板,而实例是根据类创建出来的一个个具体的 "对象". 就好比,学生是个较为抽象的概念,同时拥有很多属性,可以用一个 Student 类来描述,类中可定义学生的分数.身高等属性,但是没有具体的数值.而实例是类创建的一个个具体的对象, 每一个对象都从类中继承有相同的方法,但是属性值可能不同,如创建一个实例叫 hansry 的学生,其分数为 93,身高为 176,则这个实例拥