pandas 使用merge实现百倍加速的操作
对于非连续数据集,数据可视化时候需要每七天一个采样点。要求是选择此前最新的数据作为当日的数据展示,譬如今天是2019-06-18,而数据集里只有2019-06-15,那就用2019-06-15的数据作为2019-06-18的数据去描点。
每七天一个采样点,会使得每天展示所选的数据都会有所不同。当时间往后推移一天,日期为2019-06-19,那么最新数据点从2019-06-19开始,第二个就是2019-06-12。这里就需要一个算法来快速的根据当前日期去选出(填充)一系列数据供数据可视化之用。
一个非常直接的实现方法:
先生成一串目标时间序列,从某个开始日到今天为止,每七天一个日期。
把这些日期map到数据集的日期, Eg. {“2019-06-18”:“2019-06-15”…} 。
把map到的数据抽出来用pd.concat接起来。
代码如下:
target_dates = pd.date_range(end=now, periods=100, freq="7D") full_dates = pd.date_range(start, now).tolist() org_dates = df.date.tolist() last_date = None for d in full_dates: if d in org_dates: date_map[d] = d last_date = d elif last_date is not None: date_map[d] = last_date else: continue new_df = pd.DataFrame() for td in target_dates: new_df = pd.concat([new_df, df[df["date"]==date_map[td]])
这样的一个算法处理一个接近千万量级的数据集上大概需要十多分钟。仔细检查发现,每一次合并的dataframe数据量并不小,而且总的操作次数达到上万次。
所以就想如何避免高频次地使用pd.concat去合并dataframe。
最终想到了一个巧妙的方法,只需要修改一下前面的第三步,把日期的map转换成dataframe,然后和原始数据集做merge操作就可以了。
target_dates = pd.date_range(end=now, periods=100, freq="7D")
full_dates = pd.date_range(start, now).tolist()
org_dates = df.date.tolist()
last_date = None
for d in full_dates:
if d in org_dates:
date_map[d] = d
last_date = d
elif last_date is not None:
date_map[d] = last_date
else:
continue
#### main change is from here #####
date_map_list = []
for td in target_dates:
date_map_list.append({"target_date":td, "org_date":date_map[td]})
date_map_df = pd.DataFrame(date_map_list)
new_df = date_map_df.merge(df, left_on=["org_date"], right_on=["date"], how="inner")
改进之后,所有的循环操作都在一个微数量级上,最后一个merge操作得到了所有有用的数据,运行时间在5秒左右,大大提升了性能。
补充:Pandas DataFrames 中 merge 合并的坑点(出现重复连接键)
在我的实际开发中遇到的坑点,查阅了相关文档 总结一下
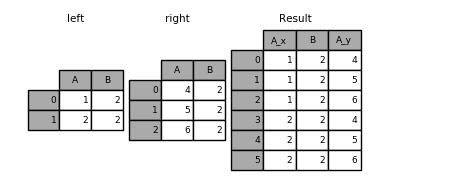
left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})

right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})

result = pd.merge(left, right, on='B', how='outer')
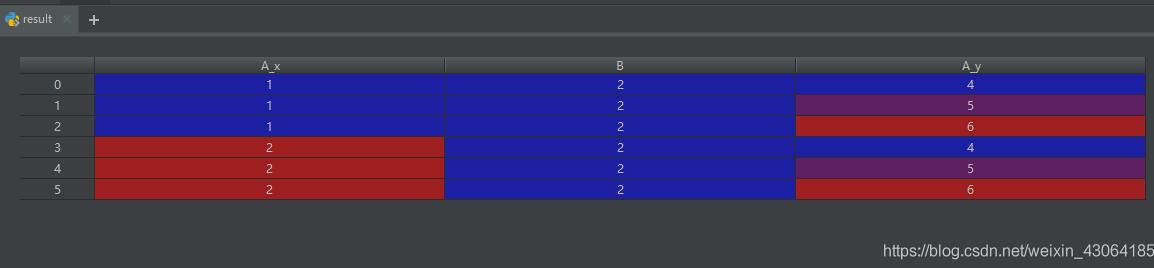
警告:在重复键上加入/合并可能导致返回的帧是行维度的乘法,这可能导致内存溢出。在加入大型DataFrame之前,重复值。
检查重复键
如果知道右侧的重复项DataFrame但希望确保左侧DataFrame中没有重复项,则可以使用该 validate='one_to_many'参数,这不会引发异常。
pd.merge(left, right, on='B', how='outer', validate="one_to_many") # 打印的结果: A_x B A_y 0 1 1 NaN 1 2 2 4.0 2 2 2 5.0 3 2 2 6.0
参数:
validate : str, optional If specified, checks if merge is of specified type. “one_to_one” or “1:1”: check if merge keys are unique in both left and right datasets. “one_to_many” or “1:m”: check if merge keys are unique in left dataset. “many_to_one” or “m:1”: check if merge keys are unique in right dataset. “many_to_many” or “m:m”: allowed, but does not result in checks.
官方文档连接:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
pandas中.loc和.iloc以及.at和.iat的区别说明
显示索引和隐式索引 import pandas as pd df = pd.DataFrame({'姓名':['张三','李四','王五'],'成绩':[85,59,76]}) 传入冒号':',表示所有行或者列 显示索引:.loc,第一个参数为 index切片,第二个为 columns列名 df.loc[2] #index为2的记录,这里是王五的成绩. df.loc[:,'姓名'] #第一个参数为冒号,表示所有行,这里是筛选姓名这列记录. 隐式索引:.iloc(integer_location)
-
pandas 颠倒列顺序的两种解决方案
在数据预处理过程中可能需要将列的顺序颠倒,有两种方法. import numpy as np import pandas as pd df = pd.DataFrame(np.array(range(20)).reshape(4,5)) print(df) 原始dataframe如下: 0 1 2 3 4 0 0 1 2 3 4 1 5 6 7 8 9 2 10 11 12 13 14 3 15 16 17 18 19 1. 方法一 手动设置列名列表,应用在dataframe中(适合列名比较少的
-
python中pandas.read_csv()函数的深入讲解
这里将更新最新的最全面的read_csv()函数功能以及参数介绍,参考资料来源于官网. pandas库简介 官方网站里详细说明了pandas库的安装以及使用方法,在这里获取最新的pandas库信息,不过官网仅支持英文. pandas是一个Python包,并且它提供快速,灵活和富有表现力的数据结构.这样当我们处理"关系"或"标记"的数据(一维和二维数据结构)时既容易又直观. pandas是我们运用Python进行实际.真实数据分析的基础,同时它是建立在NumPy之上的
-

Python基础之教你怎么在M1系统上使用pandas
一.问题 目前为止,M1系统上还不能使用pip3安装pandas库,无法使用pandas进行数据分析和处理.虽然网上也有专门适配M1的python环境,但实施起来也比较麻烦,不够纯粹. 那在M1上,如何使用pandas? 二.方案 docker新版本已经支持M1了,我们不妨尝试一下,是否可以用vscode+docker使用pandas. 1.安装M1版本的docker 访问https://docs.docker.com/docker-for-mac/install/,下载M1版本的docker.
-
Python基础之pandas数据合并
一.concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) axis: 需要合并链接的轴,0是行,1是列join:连接的方式 inner,或者outer 二.相同字段的表首尾相接 #现将表构成l
-
python-pandas创建Series数据类型的操作
1.什么是pandas 2.查看pandas版本信息 print(pd.__version__) 输出: 0.24.1 3.常见数据类型 常见的数据类型: - 一维: Series - 二维: DataFrame - 三维: Panel - - 四维: Panel4D - - N维: PanelND - 4.pandas创建Series数据类型对象 1). 通过列表创建Series对象 array = ["粉条", "粉丝", "粉带"] # 如
-
pandas读取excel时获取读取进度的实现
写在前面 QQ群里偶然看到群友问这个问题, pandas读取大文件时怎么才能获取进度? 我第一反应是: 除非pandas的read_excel等函数提供了回调函数的接口, 否则应该没办法做到. 搜索了一下官方文档和网上的帖子, 果然是没有现成的方案, 只能自己动手. 准备工作 确定方案 一开始我就确认了实现方案, 那就是增加回调函数. 这里现学现卖科普一下什么是回调函数. 简单的说就是: 所使用的模块里面, 会调用一个你给定的外部方法/函数, 就是回调函数. 拿本次的尝试作为例子, 我会编写一个
-
pandas快速处理Excel,替换Nan,转字典的操作
pandas读取Excel import pandas as pd # 参数1:文件路径,参数2:sheet名 pf = pd.read_excel(path, sheet_name='sheet1') 删除指定列 # 通过列名删除指定列 pf.drop(['序号', '替代', '签名'], axis=1, inplace=True) 替换列名 # 旧列名 新列名对照 columns_map = { '列名1': 'newname_1', '列名2': 'newname_2', '列名3':
-
解决使用pandas聚类时的小坑
问题背景: 之前运行测试好好的程序,忽然出现了报错,还是merge时候的类型错误,这个bug有点蹊跷. 问题分析: 代码:进行聚类之后计算平均值与方差 tmp_df = df[['object1', 'float']].groupby(['object1']).head(20).groupby(['object1'])['float'].agg(['mean', 'sum']).reset_index() 这个输出的就是原本的数据类型:一个object,一个float64 tmp_df = ht
-
浅谈Pandas dataframe数据处理方法的速度比较
数据修改主要以增删改差为主,这里比较几种写法在数据处理时间上的巨大差别. 数据量大概是500万行级别的数据,文件大小为100M. 1.iloc iloc是一种速度极其慢的写法.这里我们对每个csv文件中的每一行循环再用iloc处理,示例代码如下: for index in range(len(df)): df.iloc['attr'][index] = xxx 使用这种方法对五百万行的数据进行处理大概需要5个小时,实在是很慢. 2.at at相比于iloc有了很大的性能提升,也是for循环处理,
-
Python数据分析之pandas函数详解
一.apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) print(df) print(np.abs(df)) 运行结果: 0 1 2 3 0 -0.062413 0.844813 -1.853721 -1.980717 1 -0.539628 -1.975173 -0.856597 -2.612406
-
python基于Pandas读写MySQL数据库
要实现 pandas 对 mysql 的读写需要三个库 pandas sqlalchemy pymysql 可能有的同学会问,单独用 pymysql 或 sqlalchemy 来读写数据库不香么,为什么要同时用三个库?主要是使用场景不同,个人觉得就大数据处理而言,用 pandas 读写数据库更加便捷. 1.read_sql_query 读取 mysql read_sql_query 或 read_sql 方法传入参数均为 sql 语句,读取数据库后,返回内容是 dateframe 对象.普及一下
-
pandas调整列的顺序以及添加列的实现
在对excel的操作中,调整列的顺序以及添加一些列也是经常用到的,下面我们用pandas实现这一功能. 1.调整列的顺序 >>> df = pd.read_excel(r'D:/myExcel/1.xlsx') >>> df A B C D 0 bob 12 78 87 1 millor 15 92 21 >>> df.columns Index(['A', 'B', 'C', 'D'], dtype='object') # 这是最简单常用的一种方法,
-
详细介绍在pandas中创建category类型数据的几种方法
在pandas中创建category类型数据的几种方法之详细攻略 T1.直接创建 category类型数据 可知,在category类型数据中,每一个元素的值要么是预设好的类型中的某一个,要么是空值(np.nan). T2.利用分箱机制(结合max.mean.min实现二分类)动态添加 category类型数据 输出结果 [NaN, 'medium', 'medium', 'fat'] Categories (2, object): ['medium', 'fat'] name ID