Python爬取雪中悍刀行弹幕分析并可视化详程
目录
- 哔哔一下
- 爬虫部分
- 代码部分
- 效果展示
- 数据可视化
- 代码展示
- 效果展示
- 福利环节
哔哔一下
雪中悍刀行兄弟们都看过了吗?感觉看了个寂寞,但又感觉还行,原谅我没看过原著小说~
豆瓣评分5.8,说明我还是没说错它的。

当然,这并不妨碍它波播放量嘎嘎上涨,半个月25亿播放,平均一集一个亿,就是每天只有一集有点难受。
我们今天就来采集一下它的弹幕,实现数据可视化,看看弹幕文化都输出了什么~
爬虫部分
我们将它的弹幕先采集下来,保存到Excel表格~
首先安装一下这两个模块
requests # 发送网络请求 pandas as pd # 保存数据
不会安装模块移步主页看我置顶文章,有专门详细讲解安装模块问题。
代码部分
import requests # 发送网络请求
import pandas as pd # 保存数据
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
# 构建一个列表储存数据
data_list = []
for page in range(15, 1500, 30):
try:
url = f'https://mfm.video.qq.com/danmu?otype=json&target_id=7626435152%26vid%3Dp0041oidttf&session_key=0%2C174%2C1642248894×tamp={page}'
# 1. 发送网络请求
response = requests.get(url=url, headers=headers)
# 2. 获取数据 弹幕内容 <Response [200]>: 告诉我们响应成功
json_data = response.json()
# print(json_data)
# 3. 解析数据(筛选数据) 提取想要的一些内容 不想要的忽略掉
comments = json_data['comments']
for comment in comments:
data_dict = {}
data_dict['commentid'] = comment['commentid']
data_dict['content'] = comment['content']
data_dict['opername'] = comment['opername']
print(data_dict)
data_list.append(data_dict)
except:
pass
# 4. 保存数据 wps 默认以gbk的方式打开的
df = pd.DataFrame(data_list)
# 乱码, 指定编码 为 utf-8 或者是 gbk 或者 utf-8-sig
df.to_csv('data.csv', encoding='utf-8-sig', index=False)
效果展示

数据可视化
数据到手了,咱们就开始制作词云图分析了。
这两个模块需要安装一下
jieba
pyecharts
代码展示
import jieba
from pyecharts.charts import WordCloud
import pandas as pd
from pyecharts import options as opts
wordlist = []
data = pd.read_csv('data.csv')['content']
data
data_list = data.values.tolist()
data_str = ' '.join(data_list)
words = jieba.lcut(data_str)
for word in words:
if len(word) > 1:
wordlist.append({'word':word, 'count':1})
df = pd.DataFrame(wordlist)
dfword = df.groupby('word')['count'].sum()
dfword2 = dfword.sort_values(ascending=False)
dfword = df.groupby('word')['count'].sum()
dfword2 = dfword.sort_values(ascending=False)
dfword3['word'] = dfword3.index
dfword3
word = dfword3['word'].tolist()
count = dfword3['count'].tolist()
a = [list(z) for z in zip(word, count)]
c = (
WordCloud()
.add('', a, word_size_range=[10, 50], shape='circle')
.set_global_opts(title_opts=opts.TitleOpts(title="词云图"))
)
c.render_notebook()
效果展示
词云图效果

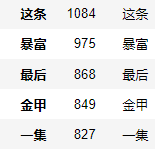
可以看到,这条、暴富和最后三个评论数据最多,咱们看看统计数据。
视频讲解
所有步骤都在视频有详细讲解
Python爬虫+数据分析+数据可视化(分析《雪中悍刀行》弹幕)
福利环节
弹幕和词云图都有了,没有视频就说不过去,代码我整出来了,大家可以自己去试试,我就不展示了,展示了你们就看不到了。
import requests
import re
from tqdm import tqdm
url = 'https://vd.l.qq.com/proxyhttp'
data = {
'adparam': "pf=in&ad_type=LD%7CKB%7CPVL&pf_ex=pc&url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fmzc0020036ro0ux%2Fc004159c18o.html&refer=https%3A%2F%2Fv.qq.com%2Fx%2Fsearch%2F&ty=web&plugin=1.0.0&v=3.5.57&coverid=mzc0020036ro0ux&vid=c004159c18o&pt=&flowid=55e20b5f153b460e8de68e7a25ede1bc_10201&vptag=www_baidu_com%7Cx&pu=-1&chid=0&adaptor=2&dtype=1&live=0&resp_type=json&guid=58c04061fed6ba662bd7d4c4a7babf4f&req_type=1&from=0&appversion=1.0.171&uid=115600983&tkn=3ICG94Dn33DKf8LgTEl_Qw..<=qq&platform=10201&opid=03A0BB50713BC1C977C0F256056D2E36&atkn=75C3D1F2FFB4B3897DF78DB2CF27A207&appid=101483052&tpid=3&rfid=f4e2ed2359bc13aa3d87abb6912642cf_1642247026",
'buid': "vinfoad",
'vinfoparam': "spsrt=1&charge=1&defaultfmt=auto&otype=ojson&guid=58c04061fed6ba662bd7d4c4a7babf4f&flowid=55e20b5f153b460e8de68e7a25ede1bc_10201&platform=10201&sdtfrom=v1010&defnpayver=1&appVer=3.5.57&host=v.qq.com&ehost=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fmzc0020036ro0ux%2Fc004159c18o.html&refer=v.qq.com&sphttps=1&tm=1642255530&spwm=4&logintoken=%7B%22main_login%22%3A%22qq%22%2C%22openid%22%3A%2203A0BB50713BC1C977C0F256056D2E36%22%2C%22appid%22%3A%22101483052%22%2C%22access_token%22%3A%2275C3D1F2FFB4B3897DF78DB2CF27A207%22%2C%22vuserid%22%3A%22115600983%22%2C%22vusession%22%3A%223ICG94Dn33DKf8LgTEl_Qw..%22%7D&vid=c004159c18o&defn=&fhdswitch=0&show1080p=1&isHLS=1&dtype=3&sphls=2&spgzip=1&dlver=2&drm=32&hdcp=0&spau=1&spaudio=15&defsrc=1&encryptVer=9.1&cKey=1WuhcCc07Wp6JZEItZs_lpJX5WB4a2CdS8kEoQvxVaqtHEZQ1c_W6myJ8hQOnmDFHMUnGJTDNTvp2vPBr-xE-uhvZyEMY131vUh1H4pgCXe2Op8F_DerfPItmE508flzsHwnEERQEN_AluNDEH6IC8EOljLQ2VfW2sTdospNPlD9535CNT9iSo3cLRH93ogtX_OJeYNVWrDYS8b5t1pjAAuGkoYGNScB_8lMah6WVCJtO-Ygxs9f-BtA8o_vOrSIjG_VH7z0wWI3--x_AUNIsHEG9zgzglpES47qAUrvH-0706f5Jz35DBkQKl4XAh32cbzm4aSDFig3gLiesH-TyztJ3B01YYG7cwclU8WtX7G2Y6UGD4Z1z5rYoM5NpAQ7Yr8GBgYGBgZKAPma&fp2p=1&spadseg=3"
}
headers = {
'cookie': 'pgv_pvid=7300130020; tvfe_boss_uuid=242c5295a1cb156d; appuser=BF299CB445E3A324; RK=6izJ0rkfNn; ptcz=622f5bd082de70e3e6e9a077923b48f72600cafd5e4b1e585e5f418570fa30fe; ptui_loginuin=1321228067; luin=o3452264669; lskey=000100003e4c51dfb8abf410ca319e572ee445f5a77020ba69d109f47c2ab3d67e58bd099a40c2294c41dbd6; o_cookie=3452264669; uid=169583373; fqm_pvqid=89ea2cc7-6806-4091-989f-5bc2f2cdea5c; fqm_sessionid=7fccc616-7386-4dd4-bba5-26396082df8d; pgv_info=ssid=s2517394073; _qpsvr_localtk=0.13663981383113954; login_type=2; vversion_name=8.2.95; video_omgid=d91995430fa12ed8; LCZCturn=798; lv_play_index=39; o_minduid=9ViQems9p2CBCM5AfqLWT4aEa-btvy40; LPSJturn=643; LVINturn=328; LPHLSturn=389; LZTturn=218; ufc=r24_7_1642333009_1642255508; LPPBturn=919; LPDFturn=470',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
response = requests.post(url=url, json=data, headers=headers)
html_data = response.json()['vinfo']
print(html_data)
m3u8_url = re.findall('url":"(.*?)",', html_data)[3]
m3u8_data = requests.get(url=m3u8_url).text
m3u8_data = re.sub('#E.*', '', m3u8_data).split()
for ts in tqdm(m3u8_data):
ts_1 = 'https://apd-327e87624fa9c6fc7e4593b5030502b1.v.smtcdns.com/vipts.tc.qq.com/AaFUPCn0gS17yiKCHnFtZa7vI5SOO0s7QXr0_3AkkLrQ/uwMROfz2r55goaQXGdGnC2de645-3UDsSmF-Av4cmvPV0YOx/svp_50112/vaemO__lrQCQrrgtQzL5v1kmLVKQZEaG2UBQO4eMRu4BAw6vBUoD1HAf7yUD8BtrL3NLr7bf9yrfSaqK5ufP8vmfEejwt0tuD8aNhyny1M-GJ8T1L1qi0R47t-v8KxV0ha-jJhALtc2N3tgRaTSfRwXwJ_vQObnhIdbyaVlJ2DzvMKoIlKYb_g/'
ts_url = ts_1 + ts
ts_content = requests.get(url=ts_url).content
with open('斗破12.mp4', mode='ab') as f:
f.write(ts_content)
print('斗破下载完成')
到此这篇关于Python爬取雪中悍刀行弹幕分析并可视化详程的文章就介绍到这了,更多相关Python 爬取雪中悍刀行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python采集电视剧《开端》弹幕做成词云图
目录 知识点介绍 环境介绍 网站分析 完整爬虫代码实现 结果展示 总结 知识点介绍 爬虫基本思路流程 requests模块的使用 pandas保存表格数据 pyecharts做词云图可视化 环境介绍 python 3.8 pycharm requests >>> pip install requests pyecharts >>> pip install pyecharts 网站分析 打开X讯视频的网页,点开<开端>,播放视频,弹幕随之出现再屏幕之上. 首先
-
Python实现爬取某站视频弹幕并绘制词云图
目录 前言 爬取弹幕 爬虫基本思路流程 导入模块 代码 制作词云图 导入模块 读取弹幕数据 前言 [课 题]: Python爬取某站视频弹幕或者腾讯视频弹幕,绘制词云图 [知识点]: 1. 爬虫基本流程 2. 正则 3. requests >>> pip install requests 4. jieba >>> pip install jieba 5. imageio >>> pip install imageio 6. wordcloud >
-
Python爬取英雄联盟MSI直播间弹幕并生成词云图
一.环境准备 安装相关第三方库 pip install jieba pip install wordcloud 二.数据准备 爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息 爬取对象路径: 方式1.根据开发者工具(F12),获取请求url.请求头.cookie等信息: 方式2:根据直播地址url,前+字符i 我们这里演示的是,采用方式2. 三.代码如下 import requests, re import jieba, wordcloud """ # 以下是练习代
-
Python基于Tkinter开发一个爬取B站直播弹幕的工具
简介 使用Python Tkinter开发一个爬取B站直播弹幕的工具,启动后在弹窗中输入房间号即可,弹幕内容会保存在脚本文件同级目录下的.log扩展名的文件中 开发工具 python 3.7.9 pycharm 2019.3.5 实现代码 import threading import time import tkinter.simpledialog # 使用Tkinter前需要先导入 from tkinter import END, messagebox import requests # 全
-
python实现b站直播自动发送弹幕功能
基本开发环境 · Python 3.6 · Pycharm 相关模块使用 import requests import time from tkinter import * import random 目标i网页分析 首先你要登陆B站账号,然后随便点击一个直播间,这里建议先选择人气少的,弹幕少的,这样方便查看效果 如上图所示,先打开开发者工具,定位到xhr输入发送内容,点击发送,会有一个post请求的send数据接口. 所以只需要请求这个数据接口即可发送弹幕.就是正常的时候爬取数据,使用requ
-
基于Python实现给喜欢的主播自动发弹幕
目录 前言 实现步骤 全部代码 前言 发弹幕只是其中一个小小的功能,还可以自动点赞.收藏.投币.自动播放.私信等等,但是我们只演示这个,其它的不做展示. 实现步骤 先打开一个视频或者直播,F12打开开发者工具,点击network. 然后点这个清空一下 再发送一个弹幕,然后可以看到这个send,有一个post请求. 点击payload可以看到我们刚刚发送的弹幕相关数据 然后来写代码 首先导入模块 import random import time 这是我们的url url = 'https://a
-
用Python采集《雪中悍刀行》弹幕做成词云实例
目录 前言 知识点介绍 环境介绍 代码实现 1. 导入模块 2. 发送网络请求 3. 获取数据 弹幕内容 4. 解析数据(筛选数据) 提取想要的一些内容 不想要的忽略掉 5. 保存数据 6. 词云图可视化 总结 前言 最近已经播完第一季的电视剧<雪中悍刀行>,从播放量就可以看出观众对于这部剧的期待,总播放量达到50亿,可让人遗憾的是,豆瓣评分只有5.7,甚至都没有破6. 很多人会把这个剧和<庆余年>做对比,因为主创班底相同 400余万字的同名小说曾被捧为网文界里的“名著”,不少粉丝
-
Python编程实现下载器自动爬取采集B站弹幕示例
目录 实现效果 UI界面 数据采集 小结 大家好,我是小张! 在<Python编程实现小姐姐跳舞并生成词云视频示例>文章中简单介绍了B站弹幕的爬取方法,只需找到视频中的参数 cid,就能采集到该视频下的所有弹幕:思路虽然很简单,但个人感觉还是比较麻烦,例如之后的某一天,我想采集B站上的某个视频弹幕,还需要从头开始:找cid参数.写代码,重复单调: 因此我在想有没有可能一步到位,以后采集某个视频弹幕时只需一步操作,比如输入想爬取的视频链接,程序能自动识别下载 实现效果 基于此,借助 PyQt5
-
python基于selenium爬取斗鱼弹幕
针对弹幕的爬取我们如果只需要获取看到的网页里面的而数据,使用selenium就能实现,对于直播平台来说,往往有第三方平台api让你获取数据(可以获取发弹幕,发弹幕者的名字礼物等等,这需要客户端向弹幕服务器发送登录请求,心跳信息的发送等等)只获取弹幕信息储存到txt文件中,上代码,上图片 代码如下: import time from selenium import webdriver chrome_options = webdriver.ChromeOptions() # 使用headless无界
-
Python爬取雪中悍刀行弹幕分析并可视化详程
目录 哔哔一下 爬虫部分 代码部分 效果展示 数据可视化 代码展示 效果展示 福利环节 哔哔一下 雪中悍刀行兄弟们都看过了吗?感觉看了个寂寞,但又感觉还行,原谅我没看过原著小说~ 豆瓣评分5.8,说明我还是没说错它的. 当然,这并不妨碍它波播放量嘎嘎上涨,半个月25亿播放,平均一集一个亿,就是每天只有一集有点难受. 我们今天就来采集一下它的弹幕,实现数据可视化,看看弹幕文化都输出了什么~ 爬虫部分 我们将它的弹幕先采集下来,保存到Excel表格~ 首先安装一下这两个模块 requests # 发
-
python爬取51job中hr的邮箱
本文实例为大家分享了python爬取51job中hr的邮箱具体代码,供大家参考,具体内容如下 #encoding=utf8 import urllib2 import cookielib import re import lxml.html from _ast import TryExcept from warnings import catch_warnings f = open('/root/Desktop/51-01.txt','a+') def read(city): url = 'ht
-
python爬取晋江文学城小说评论(情绪分析)
1. 收集数据 1.1 爬取晋江文学城收藏排行榜前50页的小说信息 获取收藏榜前50页的小说列表,第一页网址为 'http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&pa
-
Python爬取网页中的图片(搜狗图片)详解
前言 最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片http://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它- 进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome. 右键图片>>检查 发现我们需要的图片src是在img标签下的,于是先试着用
-
简单实现Python爬取网络图片
本文实例为大家分享了Python爬取网络图片的具体代码,供大家参考,具体内容如下 代码: import urllib import urllib.request import re #打开网页,下载器 def open_html ( url): require=urllib.request.Request(url) reponse=urllib.request.urlopen(require) html=reponse.read() return html #下载图片 def load_imag
-
python如何爬取网页中的文字
用Python进行爬取网页文字的代码: #!/usr/bin/python # -*- coding: UTF-8 -*- import requests import re # 下载一个网页 url = 'https://www.biquge.tw/75_75273/3900155.html' # 模拟浏览器发送http请求 response = requests.get(url) # 编码方式 response.encoding='utf-8' # 目标小说主页的网页源码 html = re
-
Python实现爬取网页中动态加载的数据
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中,无法抓取动态加载的可用数据.例如,获取某网页中,商品价格时就会出现此类现象.如下图所示.本文将实现爬取网页中类似的动态加载的数据. 1. 那么什么是动态加载的数据? 我们通过requests模块进行数据爬取无法每次都是可见即可得,有些数据是通过非浏览器地址栏中的url请求得到的.而是通过其他请求请求到的数据,那么这些通过其他请求请求到的数据就是动态加载的数据.(猜测有可能是js代码当咱们访问此页面时就会发送得get请求,到其
-
Python爬取动态网页中图片的完整实例
动态网页爬取是爬虫学习中的一个难点.本文将以知名插画网站pixiv为例,简要介绍动态网页爬取的方法. 写在前面 本代码的功能是输入画师的pixiv id,下载画师的所有插画.由于本人水平所限,所以代码不能实现自动登录pixiv,需要在运行时手动输入网站的cookie值. 重点:请求头的构造,json文件网址的查找,json中信息的提取 分析 创建文件夹 根据画师的id创建文件夹(相关路径需要自行调整). def makefolder(id): # 根据画师的id创建对应的文件夹 try: fol