Python爬取百度翻译实现中英互译功能
目录
- 基础步骤
- 提交表单
- 获取响应并处理结果
- 消除警告
- main.py
- sign.py
由于下学期报了一个Python的入门课程
所以寒假一直在自己摸索,毕竟到时候不能挂科,也是水水学分
最近心血来潮打算试试爬一下百度翻译
肝了一天终于搞出来了
话不多说,直接开搞(环境是Python 3.8 PyCharm Community Edition 2021.3.1)
基础步骤
百度翻译会识别到爬虫,所以得用headers隐藏一下
以chorme浏览器为例
在百度翻译页面点击鼠标右键,选择“检查”(或者直接F12)
显示以下界面
依次选Network-Fetch/XHR-Headers
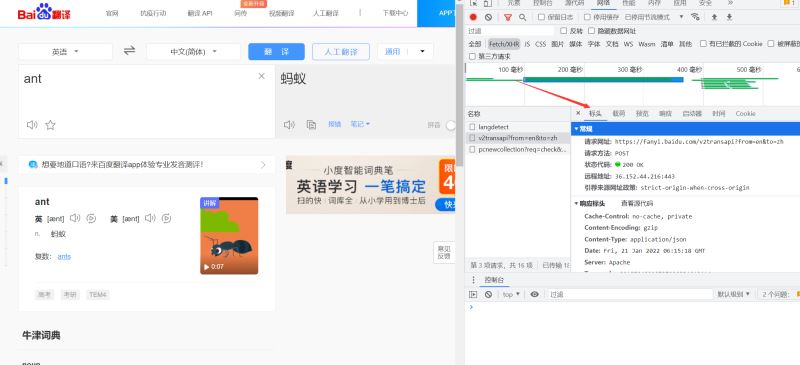
然后就能看到我们需要的标头
我们需要的是Cookie和User-Agent,用于表示是特定用户通过浏览器打开此网站
也就是伪装爬虫
然后我们复制到Pycharm当中即可
1 headers = {"User-Agent": Your User-Agent, "Cookie": Your Cookie}
2 # 后面填写你获取到的User-Agent和Cookie即可
提交表单
伪装好了之后,需要准备让爬虫向网站提交表单
但是我们提交之前需要看看我们要提交哪些数据
继续查看网站
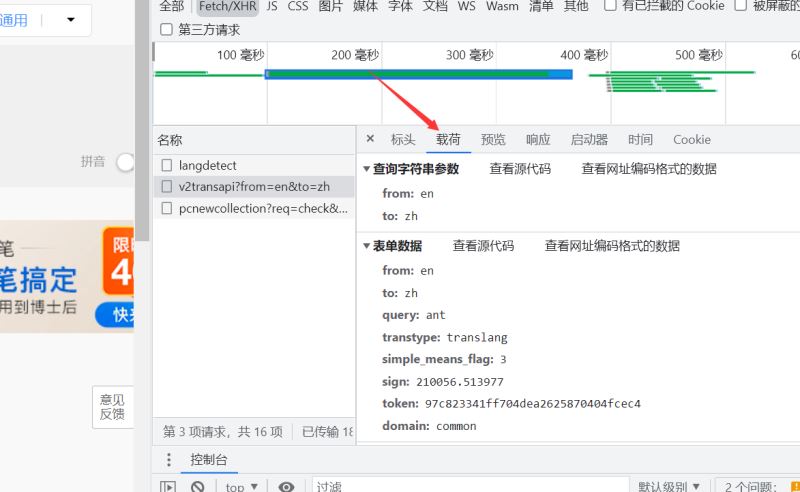
我们可以看到有一个表单数据
from: en to: zh # 从英文转中文 query: ant # 搜索ant单词 transtype: realtime # 可能是实时查询的意思? simple_means_flag: 3 sign: 210056.513977 token: 97c823341ff704dea2625870404fcec4 # 百度翻译用于识别的关键信息sign和token domain: common
这就是我们要提交的数据
但是我们提交表单的是动态的,所以要重新写一下data
也就是
data = {
"from": "en",
"to": "zh",
"query": custom_input,
"transtype": "translang",
"simple_means_flag": "3",
"token": '97c823341ff704dea2625870404fcec4'
}
获取响应并处理结果
我们考虑到提交了数据之后,咱们需要接收网页的反馈
所以继续看看返回来的翻译在哪
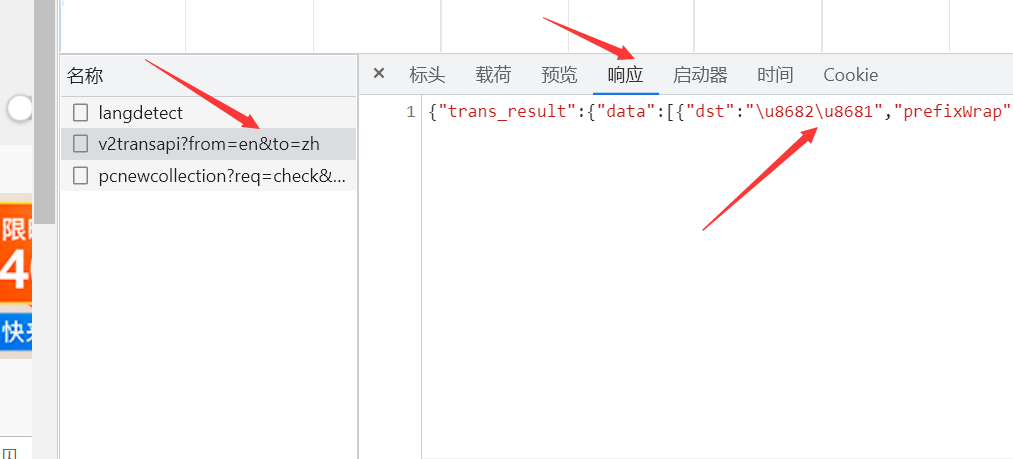
我们会发现,我们想要的和现实的似乎有些差别
结果是有了,但是不是中文,是Unicode
办法总是有的
response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data)
response.encoding = 'utf-8'
print(response.status_code) # 获取状态码
print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0]) # 正则表达式查找汉字
这样打印出来的就是中文了~
挺意外的
差不多就可以提交了!
然后我兴冲冲的去提交数据
百度翻译给了我一个大嘴巴深刻的教训
请输入要选择的翻译模式 [1]英译中 [2]中译英 1 请输入要翻译的英文 apple 200 未知错误 进程已结束,退出代码0
这是咋回事?apple的翻译应该是苹果而不是未知错误啊
然后我发现,前面的data漏了一个sign
sign是不同的单词算出来的不一样的,但是相对于单词是固定的
幸好网上巨佬多,找到了sign的算法
有兴趣可以看看sign算法的获取
最后把sign贴上去,就成功了!
消除警告
但是会出现一个Warning
请输入要选择的翻译模式
[1]英译中
[2]中译英
1
请输入要翻译的英文
apple
200
苹果
F:/Python/New/main.py:40: DeprecationWarning: invalid escape sequence '\/'
print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0])
进程已结束,退出代码0
翻译结果底下出现一个警告,不好看
于是想办法,加入了这个
import warnings
warnings.filterwarnings("ignore", category=Warning) # 关闭弃用报错
就没有错误了~
至此,英译中功能就做的差不多了
中译英是基本一样的,但是返回的东西很多,可以通过这个语句来筛选
print(re.findall(pattern='[a-zA-Z]+', string=response.content.decode('unicode_escape'), flags=re.S)[4])
差不多就是这样咯~
全部代码:
main.py
import requests
from sign import sign
import re
import warnings
warnings.filterwarnings("ignore", category=Warning) # 关闭弃用报错
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/66.0.3359.139 Safari/537.36",
"Cookie": 'BIDUPSID=248487DDE4F4874C768DD664800AFB01; '
'PSTM=1624632627; '
'__yjs_duid'
'=1_9e9a49b48ccf294be969148528d703281624677345512; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; '
'REALTIME_TRANS_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; APPGUIDE_10_0_2=1; '
'BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=39C416629357EBAB497629178C0541C1:FG=1; '
'BDUSS'
'=m9DMm1RUFZTTFBCNmdZUUFhY3lpeUR4Y3NNRW5SdThvb3FpTnZDNWdXNWRyeEJpSVFBQUFBJCQAAAAAAAAAAAEAAACSX1uneHp5MjAwMzIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAF0i6WFdIulhZ; BDUSS_BFESS=m9DMm1RUFZTTFBCNmdZUUFhY3lpeUR4Y3NNRW5SdThvb3FpTnZDNWdXNWRyeEJpSVFBQUFBJCQAAAAAAAAAAAEAAACSX1uneHp5MjAwMzIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAF0i6WFdIulhZ; H_PS_PSSID=35410_35105_31254_35774_34584_35490_35693_35796_35324_26350_35744; BAIDUID_BFESS=39C416629357EBAB497629178C0541C1:FG=1; BCLID=11903837222192425398; BDSFRCVID=meFOJeC627p69AjHgenlU9pUEeQF9_oTH6aoc1Pmnv6SwQ5bF3wEEG0PEM8g0Kub1VDqogKKQgOTHRCF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=tbFqoKI5JK03J-Fk-R6BMtCbMfQyetJyaR0tXJvvWJ5TMCoJ0-c25-InbPvwblL8-NT42-ovyJ6_ShPC-tnc3M4nKxC82Mb8Qa743qbX3l02Vhvae-t2ynLIQMFLQ-RMW23I0h7mWUoTsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJIjjC5DTOXjH8OtTnfb5kXWnbEatD_Hn7zeUDWeM4pbt-qJqTzLNQLWqnjBpRBSDTx3fo1j4tUXxTnBT5KaKTvaCTw5l7KHq32yqKKQlKkQN3TWxuO5bRi5Roy-q3FDn3oypQJXp0n04bly5jtMgOBBJ0yQ4b4OR5JjxonDh83bG7MJPKtfJut_I05JID-bnPk5PQ_b-40Mq0X5-RLfKj-Kq7F5l8-hC3xj6rNMxksbfTQL6cjQmT-blLXXb7xOKQphP-a0-uH5Gjg-h_tKeFeLh5N3KJmsqC9bT3v5tjL34OD2-biWa6M2MbdLqOP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhbLGe4bK-TrLjHKftxK; BCLID_BFESS=11903837222192425398; BDSFRCVID_BFESS=meFOJeC627p69AjHgenlU9pUEeQF9_oTH6aoc1Pmnv6SwQ5bF3wEEG0PEM8g0Kub1VDqogKKQgOTHRCF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbFqoKI5JK03J-Fk-R6BMtCbMfQyetJyaR0tXJvvWJ5TMCoJ0-c25-InbPvwblL8-NT42-ovyJ6_ShPC-tnc3M4nKxC82Mb8Qa743qbX3l02Vhvae-t2ynLIQMFLQ-RMW23I0h7mWUoTsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJIjjC5DTOXjH8OtTnfb5kXWnbEatD_Hn7zeUDWeM4pbt-qJqTzLNQLWqnjBpRBSDTx3fo1j4tUXxTnBT5KaKTvaCTw5l7KHq32yqKKQlKkQN3TWxuO5bRi5Roy-q3FDn3oypQJXp0n04bly5jtMgOBBJ0yQ4b4OR5JjxonDh83bG7MJPKtfJut_I05JID-bnPk5PQ_b-40Mq0X5-RLfKj-Kq7F5l8-hC3xj6rNMxksbfTQL6cjQmT-blLXXb7xOKQphP-a0-uH5Gjg-h_tKeFeLh5N3KJmsqC9bT3v5tjL34OD2-biWa6M2MbdLqOP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhbLGe4bK-TrLjHKftxK; delPer=0; PSINO=3; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1641456854,1642661186,1642662678,1642687449; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1642688201; BA_HECTOR=248g858580ak84a0u91guirq80q; ab_sr=1.0.1_MjM4OGFjMTZiZjUyMmYxMmU5NDhjY2FkZDkzNzRkMzZkZGUxN2RmMmY1NzEwYzg5ZDlmYTk2YTIzZmM0ODBlMzJlYzAwNDMxNjllNjk3OGMxZDJmMzI1NjNiNjlhNjExNTEzYmNkZTFlZWNjYzI4ZGVmZTA4NDk3ODBjYThlYzM='}
if __name__ == '__main__':
print("请输入要选择的翻译模式")
choose = int(input("[1]英译中\n[2]中译英\n"))
while choose != 1 and choose != 2:
print("错误!请重新输入")
choose = int(input("[1]英译中\n[2]中译英\n"))
data = {}
if choose == 1:
custom_input = input('请输入要翻译的英文\n')
data = {
"from": "en",
"to": "zh",
"query": custom_input,
"transtype": "translang",
"simple_means_flag": "3",
"token": '97c823341ff704dea2625870404fcec4',
"sign": sign(custom_input)
}
response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data)
response.encoding = 'utf-8'print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0])
elif choose == 2:
custom_input = input('请输入要翻译成英文的中文\n')
data = {
"from": "zh",
"to": "en",
"query": custom_input,
"transtype": "translang",
"simple_means_flag": "3",
"token": '97c823341ff704dea2625870404fcec4',
"sign": sign(custom_input)
}
response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data)
response.encoding = 'utf-8'
print(re.findall(pattern='[a-zA-Z]+', string=response.content.decode('unicode_escape'), flags=re.S)[4])
sign.py
import js2py
import requests
import re
def sign(word):
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
session.headers = headers
response = session.get("http://fanyi.baidu.com/")
gtk = re.findall(";window.gtk = ('.*?');", response.content.decode())[0]
word = word
context = js2py.EvalJs()
js = r'''
function a(r) {
if (Array.isArray(r)) {
for (var o = 0, t = Array(r.length); o < r.length; o++)
t[o] = r[o];
return t
}
return Array.from(r)
}
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),
a = "+" === o.charAt(t + 1) ? r >>> a : r << a,
r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)
"" !== e[C] && f.push.apply(f, a(e[C].split(""))),
C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0
, l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = 'null !== i ? i : (i = window[l] || "") || ""';
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)),
S[c++] = A >> 18 | 240,
S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224,
S[c++] = A >> 6 & 63 | 128),
S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++)
p += S[b],
p = n(p, F);
return p = n(p, D),
p ^= s,
0 > p && (p = (2147483647 & p) + 2147483648),
p %= 1e6,
p.toString() + "." + (p ^ m)
}
'''
js = js.replace('\'null !== i ? i : (i = window[l] || "") || ""\'', gtk)
# 执行js
context.execute(js)
# 调用函数得到sign
sign = context.e(word)
return sign
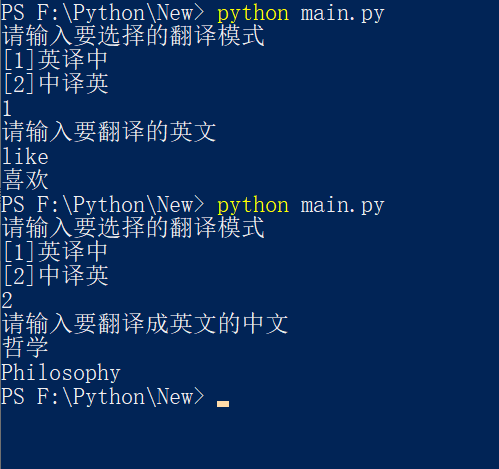
运行示例:
到此这篇关于Python爬取百度翻译实现中英互译功能的文章就介绍到这了,更多相关Python爬取百度翻译内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫之爬取百度翻译
破解百度翻译 翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢? 爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的.百度做到这一点是用 AJAX 实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新. 了解了这一点,那么我们要怎么得到 AJAX 工作时请求的URL呢?老规矩,使用抓包工具. 爬虫步骤 在 "百度
-
python 爬虫如何实现百度翻译
环境 python版本号 系统 游览器 python 3.7.2 win7 google chrome 关于本文 本文将会通过爬虫的方式实现简单的百度翻译.本文中的代码只供学习,不允许作为于商务作用.商务作用请前往api.fanyi.baidu.com购买付费的api.若有侵犯,立即删文! 实现思路 在网站文件中找到隐藏的免费api.传入api所需要的参数并对其发出请求.在返回的json结果里找到相应的翻译结果. 百度翻译的反爬机制 由js算法生成的sign cookie检测 token暗号 在
-
用python实现百度翻译的示例代码
用python实现百度翻译,分享给大家,具体如下: 首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序 打开浏览器 F12 打开百度翻译网页源代码: 我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug 然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容) 下面是代码部分: from urllib import req
-
Python爬虫实现百度翻译功能过程详解
首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序 打开浏览器 F12 打开百度翻译网页源代码: 我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug 然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容) 下面是代码部分: from urllib import request,parse import json def
-
python使用百度翻译进行中翻英示例
利用百度词典进行中翻英 复制代码 代码如下: import urllib2import reimport sys reload(sys)sys.setdefaultencoding('utf-8')def tran(word): url='http://dict.baidu.com/s?wd={0}&tn=dict'.format(word) print url req=urllib2.Request(url) resp=urllib2.urlopen(req) r
-
基于python实现百度翻译功能
运行环境: python 3.6.0 今天处于练习的目的,就用 python 写了一个百度翻译,是如何做到的呢,其实呢就是拿到接口,通过这个接口去访问,不过中间确实是出现了点问题,不过都解决掉了 先晾图后晾代码 运行结果: 代码: # -*- coding: utf-8 -*- """ 功能:百度翻译 注意事项:中英文自动切换 """ import requests import re class Baidu_Translate(object):
-
Python爬取百度翻译实现中英互译功能
目录 基础步骤 提交表单 获取响应并处理结果 消除警告 main.py sign.py 由于下学期报了一个Python的入门课程 所以寒假一直在自己摸索,毕竟到时候不能挂科,也是水水学分 最近心血来潮打算试试爬一下百度翻译 肝了一天终于搞出来了 话不多说,直接开搞(环境是Python 3.8 PyCharm Community Edition 2021.3.1) 基础步骤 百度翻译会识别到爬虫,所以得用headers隐藏一下 以chorme浏览器为例 在百度翻译页面点击鼠标右键,选择“检查”(或
-
Python使用requests模块爬取百度翻译
requests模块: python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高. 作用:模拟浏览器发请求. 提示:老版使用 urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可! requests模块编码流程 指定url 1.1 UA伪装 1.2 请求参数的处理 2.发起请求 3.获取响应数据 4.持久化存储 环境安装: pip install requests 案例一:破解百度翻译(post请求) 1.代码如下: #爬取百度翻
-
Python爬取百度春节祝福语并生成心形词云
目录 前言 环境 思路 源代码 前言 最近刚好在看爬虫,就爬取一下春节祝福语,生成个词云玩一玩,大家有兴趣可以试试,会奉上源代码,很简单.效果图如下: 环境 环境:windows, 语言:python,python版本是3.7 所依赖的第三方包: selenium----爬取网站,收集祝福语,这个库做UI自动化测试的估计会比较常见,我这里没采用使用requests库去爬取,用这个库的好处是爬取的过程中页面是实时可见的 wordcloud---用来生成词云 PIL---使词云生成想要的轮廓, 这里
-
python 爬取百度文库并下载(免费文章限定)
import requests import re import json import os session = requests.session() def fetch_url(url): return session.get(url).content.decode('gbk') def get_doc_id(url): return re.findall('view/(.*).html', url)[0] def parse_type(content): return re.findall
-
python爬取百度贴吧前1000页内容(requests库面向对象思想实现)
此程序以李毅吧为例子,以面向对象的设计思想实现爬取保存网页数据,暂时并未用到并发处理,以后有机会的话会加以改善 首先去百度贴吧分析贴吧地址栏中url后的参数,找到分页对应的参数pn,贴吧名字对应的参数kw 首先创建类,写好__init__方法,run方法,__init__方法里先可以直接写pass run方法里大概整理一下整体的思路 构造 url 列表,因为要爬取1000页,每页需对应一个url 遍历发送请求,获取响应 保存 将可封装的步骤封装到单独的方法,所以这里又增加了三个方法 get_ur
-
用Python实现爬取百度热搜信息
目录 前言 库函数准备 数据爬取 网页爬取 数据解析 数据保存 总结 前言 何为爬虫,其实就是利用计算机模拟人对网页的操作 例如 模拟人类浏览购物网站 使用爬虫前一定要看目标网站可刑不可刑 :-) 可以在目标网站添加/robots.txt 查看网页具体信息 例如对天猫 可输入 https://brita.tmall.com/robots.txt 进行查看 User-agent 代表发送请求的对象 星号*代表任何搜索引擎 Disallow 代表不允许访问的部分 /代表从根目录开始 Allow代
-
python爬取热搜制作词云
环境:win10,64位,mysql5.7数据库,python3.9.7,ancod 逻辑流程: 1.首先爬取百度热搜,至少间隔1小时 2.存入文件,避免重复请求,如果本1小时有了不再请求 3.存入数据库,供词云包使用 1.爬取热搜,首先拿到url,使用的包urllib,有教程说urllib2是python2的. '''读取页面''' def readhtml(self,catchUrl): catchUrl=self.catchUrl if not catchUrl else catchUrl
-
python爬虫之爬取百度音乐的实现方法
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法.对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同.在上次爬虫中,每一类数据都要从其父类(包括其父节点的父节点)上往下寻找ROI数据所在的子节点,这样就会使爬虫很臃肿,因为很多数据有相同的父节点,每次都要重复的找到这个父节点.这样的爬虫效率很低. 因此,笔者在上次的基础上,改进了一下爬取的策略,笔者以
-
Python爬虫实现爬取百度百科词条功能实例
本文实例讲述了Python爬虫实现爬取百度百科词条功能.分享给大家供大家参考,具体如下: 爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件.爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列.然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页