Python机器学习应用之朴素贝叶斯篇
朴素贝叶斯(Naive Bayes,NB):朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一。朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等。
1、鸢尾花案例
#%%库函数导入
import warnings
warnings.filterwarnings('ignore')
import numpy as np
# 加载莺尾花数据集
from sklearn import datasets
# 导入高斯朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
#%%数据导入&分析
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#%%查看数据集
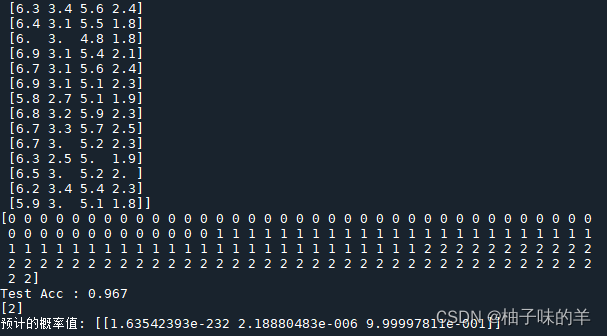
print(X)#特征集
print(y)#现象
#%%模型训练
# 假设每个特征都服正态分布,使用高斯朴素贝叶斯进行计算
clf = GaussianNB(var_smoothing=1e-8)
clf.fit(X_train, y_train)
#%%模型预测
# 评估
y_pred = clf.predict(X_test)
acc = np.sum(y_test == y_pred) / X_test.shape[0]
print("Test Acc : %.3f" % acc)
# 预测
#对第一行数据预测
y_proba = clf.predict_proba(X_test[:1])
#使用predict()函数得到预测结果
print(clf.predict(X_test[:1]))
#输出预测每个标签的概率,预测标签为0,1,2的概率分别为数组的三个值
print("预计的概率值:", y_proba)
运行结果
2、小结
predict()函数和predict_proba()函数的区别: predict()函数用于预测标签,直接得到预测标签。predict_proba()函数得到的是测试集预测得到的每个标签的概率。如果测试集一共有30个数据集,数据原本有3个标签,那么使用predict()函数将会得到30个具体预测得到的标签值,是一个【130】的数组,使用predict_proba()函数得到的是30个数据集分别取得3个标签的概率,是一个【303】的数组。
我又回来了,继续更新~ 欢迎交流
到此这篇关于Python机器学习应用之朴素贝叶斯篇的文章就介绍到这了,更多相关Python朴素贝叶斯内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 机器学习之实现朴素贝叶斯算法的示例
特点 这是分类算法贝叶斯算法的较为简单的一种,整个贝叶斯分类算法的核心就是在求解贝叶斯方程P(y|x)=[P(x|y)P(y)]/P(x) 而朴素贝叶斯算法就是在牺牲一定准确率的情况下强制特征x满足独立条件,求解P(x|y)就更为方便了 但基本上现实生活中,没有任何关系的两个特征几乎是不存在的,故朴素贝叶斯不适合那些关系密切的特征 from collections import defaultdict import numpy as np from sklearn.datasets import
-

Python通过朴素贝叶斯和LSTM分别实现新闻文本分类
目录 一.项目背景 二.数据处理与分析 三.基于机器学习的文本分类–朴素贝叶斯 1. 模型介绍 2. 代码结构 3. 结果分析 四.基于深度学习的文本分类–LSTM 1. 模型介绍 2. 代码结构 3. 结果分析 五.小结 一.项目背景 本项目来源于天池⼤赛,利⽤机器学习和深度学习等知识,对新闻⽂本进⾏分类.⼀共有14个分类类别:财经.彩票.房产.股票.家居.教育.科技.社会.时尚.时政.体育.星座.游戏.娱乐. 最终将测试集的预测结果上传⾄⼤赛官⽹,可查看排名.评价标准为类别f1_score的
-
朴素贝叶斯Python实例及解析
本文实例为大家分享了Python朴素贝叶斯实例代码,供大家参考,具体内容如下 #-*- coding: utf-8 -*- #添加中文注释 from numpy import * #过滤网站的恶意留言 #样本数据 def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park'
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
Python实现朴素贝叶斯分类器的方法详解
本文实例讲述了Python实现朴素贝叶斯分类器的方法.分享给大家供大家参考,具体如下: 贝叶斯定理 贝叶斯定理是通过对观测值概率分布的主观判断(即先验概率)进行修正的定理,在概率论中具有重要地位. 先验概率分布(边缘概率)是指基于主观判断而非样本分布的概率分布,后验概率(条件概率)是根据样本分布和未知参数的先验概率分布求得的条件概率分布. 贝叶斯公式: P(A∩B) = P(A)*P(B|A) = P(B)*P(A|B) 变形得: P(A|B)=P(B|A)*P(A)/P(B) 其中 P(A)是
-
python实现基于朴素贝叶斯的垃圾分类算法
一.模型方法 本工程采用的模型方法为朴素贝叶斯分类算法,它的核心算法思想基于概率论.我们称之为"朴素",是因为整个形式化过程只做最原始.最简单的假设.朴素贝叶斯是贝叶斯决策理论的一部分,所以讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论.假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示. 我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中用圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中用三角形表示的类别)的概率,那么对于一个新数
-
Python实现朴素贝叶斯的学习与分类过程解析
概念简介: 朴素贝叶斯基于贝叶斯定理,它假设输入随机变量的特征值是条件独立的,故称之为"朴素".简单介绍贝叶斯定理: 乍看起来似乎是要求一个概率,还要先得到额外三个概率,有用么?其实这个简单的公式非常贴切人类推理的逻辑,即通过可以观测的数据,推测不可观测的数据.举个例子,也许你在办公室内不知道外面天气是晴天雨天,但是你观测到有同事带了雨伞,那么可以推断外面八成在下雨. 若X 是要输入的随机变量,则Y 是要输出的目标类别.对X 进行分类,即使求的使P(Y|X) 最大的Y值.若X 为n 维
-
python实现朴素贝叶斯算法
本代码实现了朴素贝叶斯分类器(假设了条件独立的版本),常用于垃圾邮件分类,进行了拉普拉斯平滑. 关于朴素贝叶斯算法原理可以参考博客中原理部分的博文. #!/usr/bin/python # -*- coding: utf-8 -*- from math import log from numpy import* import operator import matplotlib import matplotlib.pyplot as plt from os import listdir def
-
Python机器学习应用之朴素贝叶斯篇
朴素贝叶斯(Naive Bayes,NB):朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一.朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等. 1.鸢尾花案例 #%%库函数导入 import warnings warnings.filterwarnings('ignore') import numpy as np # 加载莺尾花数据集 from sklearn import datasets # 导入高斯朴素贝叶斯分类器 from sklearn.naive_b
-
python中如何使用朴素贝叶斯算法
这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高. 其次,对于数学不好的人来说,为了实现算法而去研究一堆公式是很痛苦的事情. 再次,除非他人提供的算法满足不了自己的需求,否则没必要"重复造轮子". 下面言归正传,不了解贝叶斯算法的可以去查一下相关资料,这里只是简单介绍一下: 1.贝叶斯公式: P(A|B)=P(AB)/P(B) 2.贝叶斯推断: P(A|B)=P(A)×P(
-
python实现朴素贝叶斯分类器
本文用的是sciki-learn库的iris数据集进行测试.用的模型也是最简单的,就是用贝叶斯定理P(A|B) = P(B|A)*P(A)/P(B),计算每个类别在样本中概率(代码中是pLabel变量) 以及每个类下每个特征的概率(代码中是pNum变量). 写得比较粗糙,对于某个类下没有此特征的情况采用p=1/样本数量. 有什么错误有人发现麻烦提出,谢谢. [python] view plain copy # -*- coding:utf-8 -*- from numpy import * fr
-
Python编程之基于概率论的分类方法:朴素贝叶斯
概率论啊概率论,差不多忘完了. 基于概率论的分类方法:朴素贝叶斯 1. 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础--贝叶斯定理.最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类. 2. 贝叶斯理论 & 条件概率 2.1 贝叶斯理论 我们现在有一个数据集,它由两类数据组成,数据分布如下图所示: 我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(
-
PHP实现机器学习之朴素贝叶斯算法详解
本文实例讲述了PHP实现机器学习之朴素贝叶斯算法.分享给大家供大家参考,具体如下: 机器学习已经在我们的生活中变得随处可见了.比如从你在家的时候温控器开始工作到智能汽车以及我们口袋中的智能手机.机器学习看上去已经无处不在并且是一个非常值得探索的领域.但是什么是机器学习呢?通常来说,机器学习就是让系统不断的学习并且对新的问题进行预测.从简单的预测购物商品到复杂的数字助理预测. 在这篇文章我将会使用朴素贝叶斯算法Clasifier作为一个类来介绍.这是一个简单易于实施的算法,并且可给出满意的结果.但
-
Python实现的朴素贝叶斯算法经典示例【测试可用】
本文实例讲述了Python实现的朴素贝叶斯算法.分享给大家供大家参考,具体如下: 代码主要参考机器学习实战那本书,发现最近老外的书确实比中国人写的好,由浅入深,代码通俗易懂,不多说上代码: #encoding:utf-8 ''''' Created on 2015年9月6日 @author: ZHOUMEIXU204 朴素贝叶斯实现过程 ''' #在该算法中类标签为1和0,如果是多标签稍微改动代码既可 import numpy as np path=u"D:\\Users\\zhoumeixu2