Python数据分析处理(三)--运动员信息的分组与聚合
目录
- 3.1 数据的爬取
- 3.2统计男篮、女篮运动员的平均年龄、身高、体重
- 3.3统计男篮运动员年龄、身高、体重的极差值
- 3.4 统计男篮运动员的体质指数
- 3.4.1添加体重指数
- 3.4.2计算bmi值并添加数据
3.1 数据的爬取
代码:
import pandas as pd
f = open('运动员信息表.csv')
data=pd.read_csv(f,skiprows=0,header=0)
print(data)
运行结果:
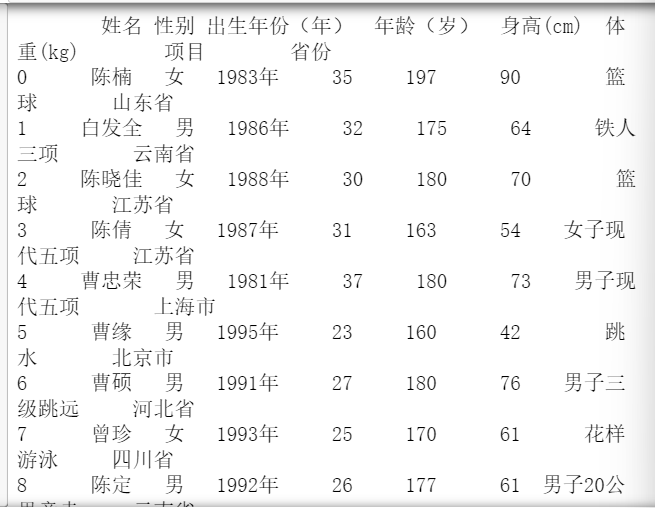
首先使用pd.read_csv(f,skiprows=0,header=0)进行数据的读取,并且将数据转换成为dataframe的格式给对象,做初始化,方便后面进行数据的分析。
3.2统计男篮、女篮运动员的平均年龄、身高、体重
代码:
sex=data[["年龄(岁)","身高(cm)","体重(kg)"]].groupby(data["性别"]) print(sex.mean())
运行结果:

首先我们先把数据提取出来做个分组,先把"年龄(岁)",“身高(cm)”,"体重(kg)"这三行数据提取出来再根据性别进行分组。
sex=data[["年龄(岁)","身高(cm)","体重(kg)"]].groupby(data["性别"])
然后再调用mean()求平均值,求出男篮、女篮运动员的平均年龄、身高、体重。
3.3统计男篮运动员年龄、身高、体重的极差值
代码:
sex=data[["年龄(岁)","身高(cm)","体重(kg)"]].groupby(data["性别"])
basketball_male=dict([x for x in sex])['男']
basketball_male
#求极差
def range_data_group(arr):
return arr.max()-arr.min()
#进行每列不同的聚合
basketball_male.agg({
"年龄(岁)":range_data_group,"身高(cm)":range_data_group,"体重(kg)":range_data_group
})
运行结果:


首先提取数据:
单行循环提取数据,dict([x for x in sex])在循环体内的语句只有一行的情况的下,可以简化for循环的书写。定义一个函数def range_data_group(arr):求极差;
极差的求法:使用最大值减去最小值。就得到极差。
agg()函数:DataFrame.agg(*func*,*axis = 0*,* args*,*** kwargs* )*
func : 函数,函数名称,函数列表,字典{‘行名/列名',‘函数名'}
使用指定轴上的一个或多个操作进行聚合。
需要注意聚合函数操作始终是在轴(默认是列轴,也可设置行轴)上执行,不同于 numpy聚合函数
最后我们可以得到三列数据:分别对应"年龄(岁)",“身高(cm)”,“体重(kg)”。
3.4 统计男篮运动员的体质指数
3.4.1添加体重指数
代码:
data["体质指数"]=0 data
运行结果:
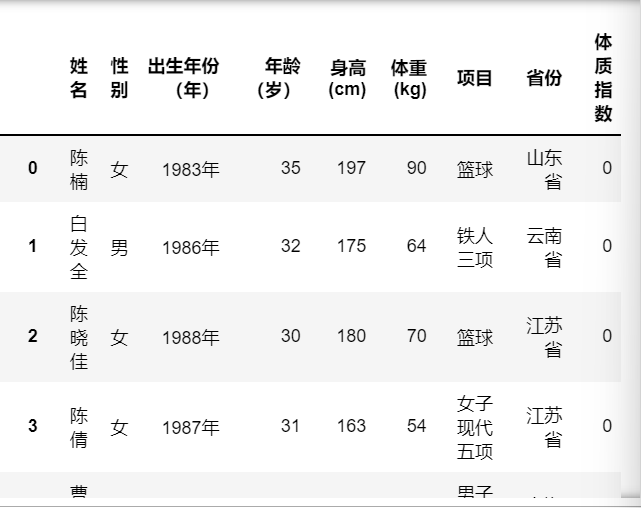
添加一行体重指数:data[“体质指数”]=0
3.4.2计算bmi值并添加数据
代码:
# 计算bmi数值
def outer(num):
def bminum(sumbim):
weight=data["身高(cm)"]
height=data["体重(kg)"]
sumbim=weight/(height/100)**2
return num+sumbim
return bminum
将该行数据添加上去:
代码:
# 调用函数 bimdata=data["体质指数"] data["体质指数"]=data[["体质指数"]].apply(outer(bimdata)) data
运行结果:

编写函数计算bmi数值 outer(num);然后再使用apply的方法将自定义的函数应用到"体质指数"这一列。然后计算出该列的值之后进行赋值。
data[“体质指数”]=data[[“体质指数”]].apply(outer(bimdata))
97622)]
编写函数计算bmi数值 outer(num) ;然后再使用apply的方法将自定义的函数应用到"体质指数"这一列。然后计算出该列的值之后进行赋值。
data[“体质指数”]=data[[“体质指数”]].apply(outer(bimdata))
到此这篇关于Python数据分析处理 运动员信息的分组与聚合的文章就介绍到这了,更多相关Python数据分析处理 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析之缺失值检测与处理详解
目录 检测缺失值 缺失值处理 删除缺失值 填补缺失值 检测缺失值 我们先创建一个带有缺失值的数据框(DataFrame). import pandas as pd df = pd.DataFrame( {'A': [None, 2, None, 4], 'B': [10, None, None, 40], 'C': [100, 200, None, 400], 'D': [None, 2000, 3000, None]}) df 数值类缺失值在 Pandas 中被显示为 NaN (Not A N
-
Python数据分析的八种处理缺失值方法详解
目录 1. 删除有缺失值的行或列 2. 删除只有缺失值的行或列 3. 根据阈值删除行或列 4. 基于特定的列子集删除 5. 填充一个常数值 6. 填充聚合值 7. 替换为上一个或下一个值 8. 使用另一个数据框填充 总结 技术交流 在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务.欢迎收藏学习,喜欢点赞支持,技术交流可以文末加群,尽情畅聊. 让我们首先创建一个示例数据框并向其中添加一些缺失值. 我们有一个 10 行 6 列的数据框. 下一步是添加缺失
-
Python数据分析与处理(一)--北京高考分数线统计分析
目录 1.1 数据爬取 1.2 最高分最低分统计 1.3 一本二本理科差值统计 1.4 2006-2019年近14年每科分数线的平均值统计 前言: 为了帮助广大考生和家长了解高考历年的录取情况,很多网站都汇总了各省市的录取控制分数线,为广大考生填报志愿提供参考.因受多种因素影响,每年的分数线或多或少会有一些变动.采集北京2006-2019年的信息.使用Python的Pandas库完成以下数据分析. 1.1 数据爬取 包含三部分内容:从哪里爬取,如何爬取,爬取的结果 代码: import pand
-
Python数据分析与处理(二)——处理中国地区信息
目录 2.1数据的爬取 2.2检查重复数据 2.3检查缺失值 2.4 检查异常值 2.1数据的爬取 代码: import pandas as pd data=pd.read_csv("example_data.csv",header=1) print(data) data1=pd.read_csv("北京地区信息.csv",header=1,encoding='gbk') data2=pd.read_csv("天津地区信息.csv",encodi
-
python使用dabl几行代码实现数据处理分析及ML自动化
目录 dabl 1.数据预处理 2.探索性数据分析 3.建模 结论 数据科学模型开发涉及各种组件,包括数据收集.数据处理.探索性数据分析.建模和部署.在训练机器学习或深度学习模型之前,必须清洗数据集并使其适合训练.通常这些过程是重复的,且占用了大部时间. 为了克服这个问题,今天我分享一个名为 dabl 的开源 Python 工具包,它可以自动化机器学习模型开发,包括数据预处理.特征可视化和分析.建模.欢迎收藏学习,喜欢点赞支持. dabl dabl 是一个数据分析基线库,可以让机器学习建模更容易
-
30 个 Python 函数,加速数据分析处理速度
目录 1.删除列 2.选择特定列 3.nrows 4.样品 5.检查缺失值 6.使用 loc 和 iloc 添加缺失值 7.填充缺失值 8.删除缺失值 9.根据条件选择行 10.用查询描述条件 11.用 isin 描述条件 12.Groupby 函数 13.Groupby与聚合函数结合 14.对不同的群体应用不同的聚合函数 15.重置索引 16.重置并删除原索引 17.将特定列设置为索引 18.插入新列 19.where 函数 20.等级函数 21.列中的唯一值数 22.内存使用情况 23.数据
-
Python数据分析处理(三)--运动员信息的分组与聚合
目录 3.1 数据的爬取 3.2统计男篮.女篮运动员的平均年龄.身高.体重 3.3统计男篮运动员年龄.身高.体重的极差值 3.4 统计男篮运动员的体质指数 3.4.1添加体重指数 3.4.2计算bmi值并添加数据 3.1 数据的爬取 代码: import pandas as pd f = open('运动员信息表.csv') data=pd.read_csv(f,skiprows=0,header=0) print(data) 运行结果: 首先使用pd.read_csv(f,skiprows=0
-
python数据分析之员工个人信息可视化
一.实验目的 (1)熟练使用Counter类进行统计 (2)掌握pandas中的cut方法进行分类 (3)掌握matplotlib第三方库,能熟练使用该三方库库绘制图形 二.实验内容 采集到的数据集如下表格所示: 三.实验要求 1.按照性别进行分类,然后分别汇总男生和女生总的收入,并用直方图进行展示. 2.男生和女生各占公司总人数的比例,并用扇形图进行展示. 3.按照年龄进行分类(20-29岁,30-39岁,40-49岁),然后统计出各个年龄段有多少人,并用直方图进行展示. import pan
-
python Pandas中数据的合并与分组聚合
目录 一.字符串离散化示例 二.数据合并 2.1 join 2.2 merge 三.数据的分组和聚合 四.索引 总结 一.字符串离散化示例 对于一组电影数据,我们希望统计电影分类情况,应该如何处理数据?(每一个电影都有很多个分类) 思路:首先构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1 代码: # coding=utf-8 import pandas as pd from matplotlib import pyplot as plt import numpy as
-
Python数据分析中Groupby用法之通过字典或Series进行分组的实例
在数据分析中有时候需要自己定义分组规则 这里简单介绍一下用一个字典实现分组 people=DataFrame( np.random.randn(5,5), columns=['a','b','c','d','e'], index=['Joe','Steve','Wes','Jim','Travis'] ) mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'} by_column=people.grou
-
Python 数据分析之Beautiful Soup 提取页面信息
概述 数据分析 (Data Analyze) 可以在工作中的各个方面帮助我们. 本专栏为量化交易专栏下的子专栏, 主要讲解一些数据分析的基础知识. Beautiful Soup Beautiful 是一个可以从 HTML 或 XML 文件中提取数据的 Pyhton 库. 简单来说, 它能将 HTML 的标签文件解析成树形结构, 然后方便的获取到指定标签的对应属性. 安装: pip install beautifulsoup4 例子: from bs4 import BeautifulSoup #
-
详解Python数据分析--Pandas知识点
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. import pandas as pd df = pd.DataFrame({"ID": ["A1000","A1001","A1002", "A1002"], "departmentId":
-
python数据分析:关键字提取方式
TF-IDF TF-IDF(Term Frequencey-Inverse Document Frequency)指词频-逆文档频率,它属于数值统计的范畴.使用TF-IDF,我们能够学习一个词对于数据集中的一个文档的重要性. TF-IDF的概念 TF-IDF有两部分,词频和逆文档频率.首先介绍词频,这个词很直观,词频表示每个词在文档或数据集中出现的频率.等式如下: TF(t)=词t在一篇文档中出现的次数/这篇文档的总词数 第二部分--逆文档频率实际上告诉了我们一个单词对文档的重要性.这是因为当计
-
python数据分析之公交IC卡刷卡分析
一.背景 交通大数据是由交通运行管理直接产生的数据(包括各类道路交通.公共交通.对外交通的刷卡.线圈.卡口.GPS.视频.图片等数据).交通相关行业和领域导入的数据(气象.环境.人口.规划.移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博.微信.论坛.广播电台等提供的文字.图片.音视频等数据)构成的. 现在给出了一个公交刷卡样例数据集,包含有交易类型.交易时间.交易卡号.刷卡类型.线路号.车辆编号.上车站点.下车站点.驾驶员编号.运营公司编号等.试导入该数据集并做分析. 二
-
Python数据分析之Python和Selenium爬取BOSS直聘岗位
一.数据爬取的代码 #encoding='utf-8' from selenium import webdriver import time import re import pandas as pd import os def close_windows(): #如果有登录弹窗,就关闭 try: time.sleep(0.5) if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("c