Python安装Bs4的多种方法
安装方法一:
①进入python文件夹执行指令(前提是支持pip指令):
pip3 install Beautifulsoup4
②回车待安装完成,如果出现以下红框中内容,即代表安装成功

③验证是否可以运行成功,运行cmd执行,引用模块import bs4回车未报错,则证明安装完成,可以正常使用了:
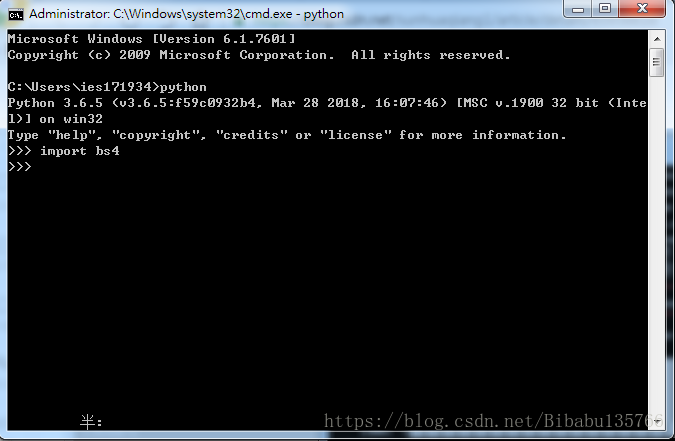
安装方法二(像我们公司这种各种网络限制,使用pip就会出现无法安装,一直循环在retry):
①进入官网下载压缩包:Beautiful Soup官网下载链接
②将压缩包解压至python文件中,进入解压文件后输入指令(前面的python不可缺少):
python setup.py install
③待运行完成后输入python,再输入help('modules')可以查看你当前python拥有的所有模块,如下:

④如上安装完成,同样检查是否可以正常引入bs4,输入:import bs4 回车
安装方法三(如果是python3伙伴会发现,上面两种方法还是不行,运行help('modules')也找不到bs4模块,此时就需要使用以下方法了):
①同样进行上面第二种方法后,将BeautifulSoup4文件夹中的bs4文件夹拷贝到python安装目录下的lib中
②将python安装目录下的Tools/scripts/2to3.py文件也剪切到python安装目录下的lib中
③cmd中cd到lib目录,然后运行python 2to3.py bs4 -w即可
到此这篇关于Python安装Bs4几种方法的文章就介绍到这了,更多相关Python安装Bs4内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中bs4.BeautifulSoup的基本用法
导入模块 from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,"html.parser") 下面看下常见的用法 print(soup.a) # 拿到soup中的第一个a标签 print(soup.a.name) # 获取a标签的名称 print(soup.a.string) # 获取a标签的文本内容 print(soup.a.text) # 获取a标签的文本内容 print(soup.a["href"
-
Python爬虫使用bs4方法实现数据解析
聚焦爬虫: 爬取页面中指定的页面内容. 编码流程: 1.指定url 2.发起请求 3.获取响应数据 4.数据解析 5.持久化存储 数据解析分类: 1.bs4 2.正则 3.xpath (***) 数据解析原理概述: 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储 1.进行指定标签的定位 2.标签或者标签对应的属性中存储的数据值进行提取(解析) bs4进行数据解析数据解析的原理: 1.标签定位 2.提取标签.标签属性中存储的数据值 bs4数据解析的原理: 1.实例化一个Beauti
-
python2使用bs4爬取腾讯社招过程解析
目的:获取腾讯社招这个页面的职位名称及超链接 职位类别 人数 地点和发布时间 要求:使用bs4进行解析,并把结果以json文件形式存储 注意:如果直接把python列表没有序列化为json数组,写入到json文件,会产生中文写不进去到文件,所以要序列化并进行utf-8编码后写入文件. # -*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup as bs import json url = 'https://hr.te
-
Python使用bs4获取58同城城市分类的方法
本文实例讲述了Python使用bs4获取58同城城市分类的方法.分享给大家供大家参考.具体如下: # -*- coding:utf-8 -*- #! /usr/bin/python import urllib import os, datetime, sys from bs4 import BeautifulSoup reload(sys) sys.setdefaultencoding( "utf-8" ) __BASEURL__ = "http://bj.58.com/&q
-
浅谈Python中的bs4基础
安装 在命令提示符框中直接输入pip install beautifulsoup4 介绍 beautifulsoup是python的一个第三方库,和xpath一样,都是用来解析html数据的. 引入 from bs4 import BeautifulSoup 使用 将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象. bs = BeautifulSoup(open('index.html',encoding='utf-8'),'lxml') print(bs) 注意:这样
-
Python BS4库的安装与使用详解
Beautiful Soup 库一般被称为bs4库,支持Python3,是我们写爬虫非常好的第三方库.因用起来十分的简便流畅.所以也被人叫做"美味汤".目前bs4库的最新版本是4.60.下文会介绍该库的最基本的使用,具体详细的细节还是要看:[官方文档](Beautiful Soup Documentation) bs4库的安装 Python的强大之处就在于他作为一个开源的语言,有着许多的开发者为之开发第三方库,这样我们开发者在想要实现某一个功能的时候,只要专心实现特定的功能,其他细节与
-

python利用re,bs4,requests模块获取股票数据
今天闲来无聊无意间看到了百度股票,就想着用python爬一下数据,于是就找到了东方财经网,结合这两个网站,写了一个小爬虫,数据保存在文件中,比较简单的示例,就当做用来练习正则表达式和BeautifulSoupl了. 首先页面分析,打开东方财经网股票列表页, 和百度股票详情页 ,右键查看网页源代码, 网址后面的代码就是股票代码,所以打算先获取股票代码,然后获取详情,废话少说,直接上代码吧: import re import requests from bs4 import BeautifulSou
-
Python安装Bs4的多种方法
安装方法一: ①进入python文件夹执行指令(前提是支持pip指令): pip3 install Beautifulsoup4 ②回车待安装完成,如果出现以下红框中内容,即代表安装成功 ③验证是否可以运行成功,运行cmd执行,引用模块import bs4回车未报错,则证明安装完成,可以正常使用了: 安装方法二(像我们公司这种各种网络限制,使用pip就会出现无法安装,一直循环在retry): ①进入官网下载压缩包:Beautiful Soup官网下载链接 ②将压缩包解压至python文件中,进
-
Python安装Bs4及使用方法
安装方法一: ①进入python文件夹执行指令(前提是支持pip指令): pip3 install Beautifulsoup4 ②回车待安装完成,如果出现以下红框中内容,即代表安装成功 ③验证是否可以运行成功,运行cmd执行,引用模块import bs4回车未报错,则证明安装完成,可以正常使用了: 安装方法二 (像我们公司这种各种网络限制,使用pip就会出现无法安装,一直循环在retry): ①进入官网下载压缩包:Beautiful Soup官网下载链接 ②将压缩包解压至python文件中,进
-
Python模拟登录的多种方法(四种)
正文 方法一:直接使用已知的cookie访问 特点: 简单,但需要先在浏览器登录 原理: 简单地说,cookie保存在发起请求的客户端中,服务器利用cookie来区分不同的客户端.因为http是一种无状态的连接,当服务器一下子收到好几个请求时,是无法判断出哪些请求是同一个客户端发起的.而"访问登录后才能看到的页面"这一行为,恰恰需要客户端向服务器证明:"我是刚才登录过的那个客户端".于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态). 当然,这也
-
windows下Pycharm安装opencv的多种方法
之前在默认环境中用pip安装过一次opencv,当时就是参考比人方法弄,稀里糊涂的,然后今天想在自己别的环境下(tensorflow)下安装终于弄懂了一些,暂时发现了几种安装的方法,特此记录下. 方法1:在Pycharm自带的库中下载(暂且这么叫吧,如下图) 这个方法我也是看别人说的,自己还没试过,描述也没介绍版本啥的,所以个人也不推荐- 方法2: 就是opencv官网介绍的安装方法,但是有些需要改,这里把步骤说明下: 1)先下载win版本的opencv并extract,然后在opencv\bu
-
python 下载文件的多种方法汇总
本文档介绍了 Python 下载文件的各种方式,从下载简单的小文件到用断点续传的方式下载大文件. Requests 使用 Requests 模块的 get 方法从一个 url 上下载文件,在 python 爬虫中经常使用它下载简单的网页内容 import requests # 图片来自bing.com url = 'https://cn.bing.com/th?id=OHR.DerwentIsle_EN-CN8738104578_400x240.jpg' def requests_downloa
-
Python安装依赖(包)模块方法详解
Python模块,简单说就是一个.py文件,其中可以包含我们需要的任意Python代码.迄今为止,我们所编写的所有程序都包含在单独的.py文件中,因此,它们既是程序,同时也是模块.关键的区别在于,程序的设计目标是运行,而模块的设计目标是由其他程序导入并使用. 不是所有程序都有相关联的.py文件-比如说,sys模块就内置于Python中,还有些模块是使用其他语言(最常见的是C语言)实现的.不过,Python的大多数库文件都是使用Python实现的,因此,比如说,我们使用了语句import coll
-
python 安装库几种方法之cmd,anaconda,pycharm详解
python安装库的几种方法 在python项目开发的过程中,需要安装大大小小的库,本文会提供几种安装库的方法,总有一种可以帮到大家. 安装的方法主要有三种: ①利用命令框安装库. ②利用pycharm的环境配置界面安装库. ③利用anaconda直接安装库(几乎无所不能). ①利用命令框安装python库 首先进命令行界面(cmd),利用conda指令打开演示用的anaconda环境(名称为tf1.13) conda activate tf1.13 如下图所示,进入名为tf1.13的环境(最前
-
python安装sklearn模块的方法详解
可直接用这行命令!: pip install -U scikit-learn 其他命令: (1)更新pip python -m pip install --upgrade pip (2)安装 scipy 在网址http://www.lfd.uci.edu/~gohlke/pythonlibs/ 中找到你需要的版本scipy 例如windows 64 位 Python2.7 对应下载:scipy-0.18.0-cp27-cp27m-win_amd64.whl cd 下载scipy 目录下,安装 p
-
MySQL学习笔记1:安装和登录(多种方法)
今天开始学习数据库,由于我对微软不怎么感冒,所以就不用他家的产品了本来想装ORACLE的,不过太大了,看着害怕对于我这种喜欢一切从简的人来说,MySQL是个不错的选择好了,关于数据库的大理论我就懒得写了,那些考试必备的内容我已经受够了我只需要知道一点,人们整理数据和文件的行为在不断进化,以至现在使用数据库来更好的管理 下面我们开始安装 我使用的是Linux Mint,基于Ubuntu的一种发行版,用起来的确不错 由于有现成的包管理工具使用,我就不从官网下载编译安装了 一条命令搞定: 安装过程中会
-
Selenium及python实现滚动操作多种方法
selenium并不是万能的,有时候页面上操作无法实现的,这时候就需要借助JS来完成了. 当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见的. 这时候需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上.滚动条是无法直接用定位工具来定位的. selenium里面也没有直接的方法去控制滚动条,这时候只能借助J了,还好selenium提供了一个操作js的方法:execute_script(),可以直接执行js的脚本. 方法一:使用js脚本直接操作 # 滚动到顶部