基于JQuery的抓取博客园首页RSS的代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>无标题文档</title>
</head>
<body>
<table id='tbl1' cellpadding="1" cellspacing="1" bgcolor="#333333" width="800px" style="line-height:30px;">
<tr bgcolor="#FFFFFF"><td align="center" width="70%">标题</td><td align="center" width="30%">时间</td></tr>
</table>
<div id="loading" style="display:none"><font color='red'>正在加载数据。。。</font></div>
</body>
</html>
<script language="javascript" type="text/javascript" src="https://ajax.googleapis.com/ajax/libs/jquery/1.4.2/jquery.min.js"></script>
<script language="javascript" type="text/javascript" >
$(function(){
var html="";
var bgcolor="";
$.ajax({
url:"http://www.cnblogs.com/rss",
type:"get",
//dataType:($.browser.msie) ? "text" : "xml",
success:function(data){
$("item",data).each(function(index,element){
bgcolor=index%2==0 ?" bgcolor='#F1F1F1' ":" bgcolor='#FFFFFF' ";
html+="<tr "+bgcolor+"><td><a href='"+$(this).find("link").text()+"'>"+FormatContent($(this).find("title").text(),40)+"</td><td>"+ new Date($(this).find("pubDate").text()).format("yyyy-MM-dd hh:mm:ss");+"</td></tr>";
});
$("#tbl1 tr:not(':first')").remove();//移除非第一行
$("#tbl1").append(html);//绑定数据到table
},
complete:function(){
$("#loading").hide();
},
beforeSend:function(x){
//x.setRequestHeader("Content-Type", "charset=utf-8");
$("#loading").show();
},
error:function(){
alert("error");
}
});
});
</script>
<script language="javascript">
/**
* 时间对象的格式化;
*/
Date.prototype.format = function(format) {
/*
* eg:format="YYYY-MM-dd hh:mm:ss";
*/
var o = {
"M+" :this.getMonth() + 1, // month
"d+" :this.getDate(), // day
"h+" :this.getHours(), // hour
"m+" :this.getMinutes(), // minute
"s+" :this.getSeconds(), // second
"q+" :Math.floor((this.getMonth() + 3) / 3), // quarter
"S" :this.getMilliseconds()
// millisecond
}
if (/(y+)/.test(format)) {
format = format.replace(RegExp.$1, (this.getFullYear() + "")
.substr(4 - RegExp.$1.length));
}
for ( var k in o) {
if (new RegExp("(" + k + ")").test(format)) {
format = format.replace(RegExp.$1, RegExp.$1.length == 1 ? o[k]
: ("00" + o[k]).substr(("" + o[k]).length));
}
}
return format;
}
//格式化标题信息
function FormatContent(word,length){
return word.length>length?word.substring(0,length)+"...":word;
}
</script>
相关推荐
-

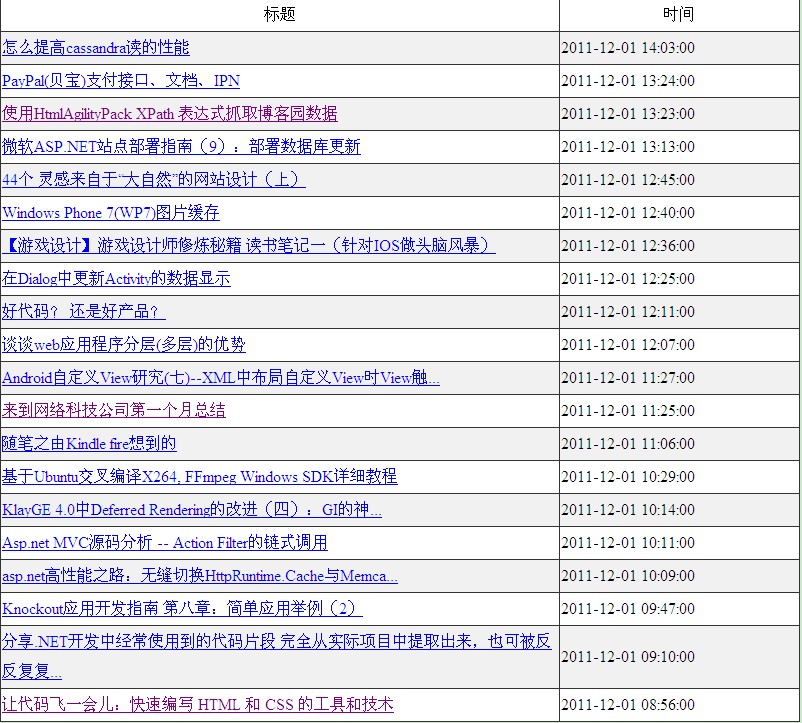
基于JQuery的抓取博客园首页RSS的代码
效果图:实现代码: 复制代码 代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http
-
使用HtmlAgilityPack XPath 表达式抓取博客园数据的实现代码
Web 前端代码 复制代码 代码如下: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx.cs" Inherits="_Default" %> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.
-
利用正则表达式抓取博客园列表数据
鉴于我在要完成的asp.net MVC 3 仿照博客园企业系统要用到测试数据,我自己输入太累,所以我就抓取了博客园的部分列表数据,还请dudu不要见怪. 在抓取博客园数据的时候采用了正则表达式,所以有不熟悉正则表达式的朋友可以参考相关资料,其实很容易掌握,就是在具体的实例中会花些时间. 现在我就来把我抓取博客园数据的过程叙述一下,如果有朋友有更好的意见,欢迎提出来. 要使用正则表达式抓取数据,首先就要创建一个正则表达式进行匹配,我推荐使用regulator,这个正则表达式工具,我们可以先使用这个
-
Python如何基于selenium实现自动登录博客园
这篇文章主要介绍了Python如何基于selenium实现自动登录博客园,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 需要做的准备: 本文章是使用Chrome,所以需要Chormedriver.exe,具体的下载过程可以百度查到 Selenium是一种自动化测试工具,能模拟浏览器的行为,所以今天我就模拟一下浏览器登陆博客园的行为. 首先,分析问题,登陆博客园需要做些什么: 1.打开浏览器 2.输入博客园主页的网址 3.点击登陆按钮,等待页面跳
-
Node.js+jade抓取博客所有文章生成静态html文件的实例
这篇文章,我们就把上文中采集到的所有文章列表的信息整理一下,开始采集文章并且生成静态html文件了.先看下我的采集效果,我的博客目前77篇文章,1分钟不到就全部采集生成完毕了,这里我截了部分的图片,文件名用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是根据这个模板生成的. 项目结构: 好了,接下来,我们就来讲解下,这篇文章主要实现的功能: 1,抓取文章,主要抓取文章的标题,内容,超链接,文章id(用于生成静态html文件) 2,根据jade模板生成html文件 一.抓取文
-
详解Python爬虫爬取博客园问题列表所有的问题
一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下. 我们的需求是将博客园问题列表中的所有问题的题目爬取下来. 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找问题所对应的属性或标签 可以发现在div class ="one_entity"中存在页面中分别对应每一个问题 接着div class ="news_item"中h2标签下是我们想要拿到的数据 三.代码实现 首先导入requests和
-
用ajax自动加载blogjava和博客园的rss
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>this is test</title> <sc
-
asp.net利用存储过程和div+css实现分页(类似于博客园首页分页)
首先声明以下几点: 1.也许讲解有点初级,希望高手不要"喷"我,因为我知道并不是每一个人都是高手,我也怕高手们说我装13,小生不才: 2.如有什么不对的地方,还希望大家指出,一定虚心学习: 3.本文属于作者原创,尊重他人劳动成果,转载请注明作者,谢谢. 下面开讲: 首先说下思路,写一个存储过程,我也找了一个存储过程,不过不是我写的,出处:http://www.cnblogs.com/zhongweiv/archive/2011/10/31/JqueryPagination.html 这
-
jQuery实现可用于博客的动态滑动菜单完整实例
本文实例讲述了jQuery实现可用于博客的动态滑动菜单代码.分享给大家供大家参考.具体如下: 这是一款基于jQuery1.3.2的动态滑动菜单特效代码,常用于博客,鼠标滑过菜单,菜单会不断伸出,貌似很漂亮,我比较喜欢,发上来供大家使用或学习参考. 运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/jquery-blog-move-style-menu-codes/ 具体代码如下: <!DOCTYPE html PUBLIC "-//W3C//
-
PHP仿博客园 个人博客(1) 数据库与界面设计
自学PHP大半年多了,断断续续地,但是最终还是坚定了我的想法,将PHP继续下去,所以写这个PHP的博客是为了找个稳定的 PHP工作,不求工资多高,但求一收留之地.我能看懂大部分英语文档,人不蠢,爱学习,有兴趣地可以联系下!有诚意的来吧!qq:240382473 我会分3-5次发布所有关键代码和文档说明,博客后台所有的样式均套用博客园! 说明: 1. 不完全采用MVC架构,但是理念就是这样的.因为还不能写出很稳定的MVC架构. 2.几乎不采用JQUERY AJAX 因为不是特别熟悉,运用起来还不自