正则应用之 逆序环视探索 .
1 问题引出
前几天在CSDN论坛遇到这样一个问题。
我要通过正则分别取出下面 <font color="#008000"> 与 </font> 之间的字符串
1、在 <font color="#008000"> 与 </font> 之间的字符串是没法固定的,是随机自动生成的
2、其中 <font color="#008000"> 与 </font>的数量也是没法固定的,也是随机自动生成的
<font color="#008000"> ** 这里是不固定的字符串1 ** </font>
<font color="#008000"> ** 这里是不固定的字符串2 ** </font>
<font color="#008000"> ** 这里是不固定的字符串3 ** </font>
有朋友给出这样的正则“(?<=<font[\s\S]*?>)([\s\S]*?)(?=</font>)”,看下匹配结果。
代码如下:
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=<font[\s\S]*?>)([\s\S]*?)(?=</font>)");
foreach (Match m in mc)
{
richTextBox2.Text += m.Value + "\n---------------\n";
}
/*--------输出--------
** 这里是不固定的字符串1 **
---------------
<font color="#008000"> ** 这里是不固定的字符串2 **
---------------
<font color="#008000"> ** 这里是不固定的字符串3 **
---------------
*/
为什么会是这样的结果,而不是我们期望的如下的结果呢?
/*--------输出--------
** 这里是不固定的字符串1 **
---------------
** 这里是不固定的字符串2 **
---------------
** 这里是不固定的字符串3 **
---------------
*/
这涉及到逆序环视的匹配原理,以及贪婪与非贪婪模式应用的一些细节,下面先针对逆序环视的匹配细节展开讨论,然后再回过头来看下这个问题。
2 逆序环视匹配原理
关于环视的一些基础讲解和基本匹配原理,在正则基础之——环视这篇博客里已有所介绍,只不过当时整理得比较匆忙,没有涉及更详细的匹配细节。这里仅针对逆序环视展开讨论。
逆序环视的基础知识在上面博文中已介绍过,这里简单引用一下。
表达式 |
说明 |
|
(?<=Expression) |
逆序肯定环视,表示所在位置左侧能够匹配Expression |
|
(?<!Expression) |
逆序否定环视,表示所在位置左侧不能匹配Expression |
对于逆序肯定环视(?<=Expression)来说,当子表达式Expression匹配成功时,(?<=Expression)匹配成功,并报告(?<=Expression)匹配当前位置成功。
对于逆序否定环视(?<!Expression)来说,当子表达式Expression匹配成功时,(?<!Expression)匹配失败;当子表达式Expression匹配失败时,(?<!Expression)匹配成功,并报告(?<!Expression)匹配当前位置成功。
2.1 逆序环视匹配行为分析
2.1.1 逆序环视支持现状
目前支持逆序环视的语言还比较少,比如当前比较流行的脚本语言JavaScript中就是不支持逆序环视的。个人认为不支持逆序环视已成为目前JavaScript中使用正则的最大限制,一些使用逆序环视很轻松搞定的输入验证,却要通过各种变通的方式来实现。
需求:验证输入由字母、数字和下划线组成,下划线不能出现在开始或结束位置。
对于这样的需求,如果支持逆序环视,直接“^(?!_)[a-zA-Z0-9_]+(?<!_)$”就可以了搞定了,但是在JavaScript中,却需要用类似于“^[a-zA-Z0-9]([a-zA-Z0-9_]*[a-zA-Z0-9])?$”这种变通方式来实现。这只是一个简单的例子,实际的应用中,会比这复杂得多,而为了避免量词的嵌套带来的效率陷阱,正则实现起来很困难,甚至有些情况不得不拆分成多个正则来实现。
而另一些流行的语言,比如Java中,虽然支持逆序环视,但只支持固定长度的子表达式,量词也只支持“?”,其它不定长度的量词如“*”、“+” 、“{m,n}”等是不支持的。
源字符串:<div>a test</div>
需求:取得div标签的内容,不包括div标签本身
Java代码实现:
代码如下:
import java.util.regex.*;
String test = "<div>a test</div>";
String reg = "(?<=<div>)[^<]+(?=</div>)";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
}
/*--------输出--------
a test
*/
但是如果源字符串变一下,加个属性变成“<div id=”test1”>a test</div>”,那么除非标签中属性内容是固定的,否则就无法在Java中用逆序环视来实现了。
为什么在很多流行语言中,要么不支持逆序环视,要么只支持固定长度的子表式呢?先来分析一下逆序环视的匹配原理吧。
2.1.2 Java中逆序环视匹配原理分析
不支持逆序环视的自不必说,只支持固定长度子表达式的逆序环视如何呢。
源字符串:<div>a test</div>
正则表达式:(?<=<div>)[^<]+(?=</div>) 
需要明确的一点,无论是什么样的正则表达式,都是要从字符串的位置0处开始尝试匹配的。
首先由“(?<=<div>)”取得控制权,由位置0开始尝匹配,由于“<div>”的长度固定为5,所以会从当前位置向左查找5个字符,但是由于此时位于位置0处,前面没有任何字符,所以尝试匹配失败。
正则引擎传动装置向右传动,由位置1处开始尝试匹配,同样匹配失败,直到位置5处,向左查找5个字符,满足条件,此时把控制权交给“(?<=<div>)”中的子表达式“<div>”。“<div>”取得控制权后,由位置0处开始向右尝试匹配,由于正则都是逐字符进行匹配的,所以这时会把控制权交给“<div>”中的“<”,由“<”尝试字符串中的“<”,匹配成功,接下来由“d”尝试字符串中的“d”,匹配成功,同样的过程,由“<div>”匹配位置0到位置5之间的“<div>”成功,此时“(?<=<div>)”匹配成功,匹配成功的位置是位置5。
后续的匹配过程请参考 正则基础之——环视 和 正则基础之——NFA引擎匹配原理。
那么对于量词“?”又是怎么样一种情况呢,看一下下面的例子。
源字符串:cba
正则表达式:(?<=(c?b))a
代码如下:
String test = "cba";
String reg = "(?<=(c?b))a";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
System.out.println(m.group(1));
}
/*--------输出--------
a
*/
可以看到,“c?”并没有参与匹配,在这里,“?”并不具备贪婪模式的作用,“?”只提供了一个分支的作用,共记录了两个分支,一个分支需要从当前位置向前查找一个字符,另一个分支需要从当前位置向前查找两个字符。正则引擎从当前位置,尝试这两种情况,优先尝试的是需要向前查找较少字符的分支,匹配成功,则不再尝试另一个分支,只有这一分支匹配失败时,才会去尝试另一个分支。
代码如下:
String test = "dcba";
String reg = "(?<=(dc?b))a";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
System.out.println(m.group(1));
}
/*--------输出--------
a
dcb
*/
虽然有两个分支,但向前查找的字符数可预知的,所以只支持“?”时并不复杂,但如果再支持其它不定长度量词,情况又如何呢?
2.1.3 .NET中逆序环视匹配原理
.NET的逆序环视中,是支持不定长度量词的,在这个时候,匹配过程就变得复杂了。先看一下定长的是如何匹配的。
代码如下:
string test = "<div>a test</div>";
Regex reg = new Regex(@"(?<=<div>)[^<]+(?=</div>)");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
}
/*--------输出--------
a test
*/
从结果可以看到,.NET中的逆序环视在子表达式长度固定时,匹配行为与Java中应该是一样的。那么不定长量词又如何呢?
代码如下:
string test = "cba";
Regex reg = new Regex(@"(?<=(c?b))a");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
richTextBox2.Text += m.Groups[1].Value + "\n";
}
/*--------输出--------
a
cb
*/
可以看到,这里的“?”具备了贪婪模式的特性。那么这个时候是否会有这样的疑问,它的匹配过程仍然是从当前位置向左尝试,还是从字符串开始位置向右尝试匹配呢?
代码如下:
string test = "<ddd<cccba";
Regex reg = new Regex(@"(?<=(<.*?b))a");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
richTextBox2.Text += m.Groups[1].Value + "\n";
}
/*--------输出--------
a
<cccb
*/
从结果可看出,在逆序环视中有不定量词的时候,仍然是从当前位置,向左尝试匹配的,否则Groups[1]的内容就是“<ddd<cccb”,而不是“<cccb”了。
这是非贪婪模式的匹配情况,再看一下贪婪模式匹配的情况。
代码如下:
string test = "e<ddd<cccba";
Regex reg = new Regex(@"(?<=(<.*b))a");
Match m = reg.Match(test);
if (m.Success)
{
richTextBox2.Text += m.Value + "\n";
richTextBox2.Text += m.Groups[1].Value + "\n";
}
/*--------输出--------
a
<ddd<cccb
*/
可以看到,采用贪婪模式以后,虽然尝试到“c”前面的“<”时已经可以匹配成功,但由于是贪婪模式,还是要继续尝试匹配的。直到尝试到开始位置,取最长的成功匹配作为匹配结果。
2.2 匹配过程
再来理一下逆序环视的匹配过程吧。
源字符串:<div id=“test1”>a test</div>
正则表达式:(?<=<div[^>]*>)[^<]+(?=</div>) 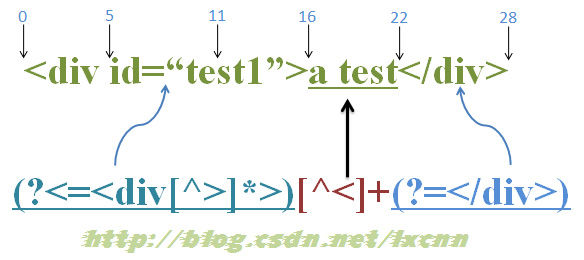
首先由“(?<=<div[^>]*>)”取得控制权,由位置0开始尝匹配,由于“<div[^>]*>”的长度不固定,所以会从当前位置向左逐字符查找,当然,也有可能正则引擎做了优化,先计算一下最小长度后向前查找,在这里“<div[^>]*>”至少需要5个字符,所以由当前位置向左查找5个字符,才开始尝试匹配,这要看各语言的正则引擎如何实现了,我推测是先计算最小长度。但是由于此时位于位置0处,前面没有任何字符,所以尝试匹配失败。
正则引擎传动装置向右传动,由位置1处开始尝试匹配,同样匹配失败,直到位置5处,向左查找5个字符,满足条件,此时把控制权交给“(?<=<div[^>]*>)”中的子表达式“<div[^>]*>”。“<div[^>]*>”取得控制权后,由位置0处开始向右尝试匹配,由于正则都是逐字符进行匹配的,所以这时会把控制权交给“<div[^>]*>”中的“<”,由“<”尝试字符串中的“<”,匹配成功,接下来由“d”尝试字符串中的“d”,匹配成功,同样的过程,由“<div[^>]*”匹配位置0到位置5之间的“<div ”成功,其中“[^>]*”在匹配“<div ”中的空格时是要记录可供回溯的状态的,此时控制权交给“>”,由于已没有任何字符可供匹配,所以“>”匹配失败,此时进行回溯,由“[^>]*”让出已匹配的空格给“>”进行匹配,同样匹配失败,此时已没有可供回溯的状态,所以这一轮匹配尝试失败。
正则引擎传动装置向右传动,由位置6处开始尝试匹配,同样匹配失败,直到位置16处,此时的当前位置指的就是位置16,把控制权交给“(?<=<div[^>]*>)”,向左查找5个字符,满足条件,记录回溯状态,控制权交给“(?<=<div[^>]*>)”中的子表达式“<div[^>]*>”。“<div[^>]*>”取得控制权后,由位置11处开始向右尝试匹配, “<div[^>]*>”中的“<”尝试字符串中的“s”,匹配失败。继续向左尝试,在位置10处由“<”尝试字符串中的“e”,匹配失败。同样的过程,直到尝试到位置0处,由“<div[^>]*”在位置0向右尝试匹配,成功匹配到“<div id=“test1”>”,此时“(?<=<div[^>]*>)”匹配成功,控制权交给“[^>]+”,继续进行下面的匹配,直到整个表达式匹配成功。
总结正则表达式“(?<=SubExp1) SubExp2”的匹配过程:
1、 由位置0处向右尝试匹配,直到找到一个满足“(?<=SubExp1) ”最小长度要求的位置x;
2、 从位置x处向左查找满足“SubExp1”最小长度要求的位置y;
3、 由“SubExp1”从位置y开始向右尝试匹配;
4、 如果“SubExp1”为固定长度或非贪婪模式,则找到一个成功匹配项即停止尝试匹配;
5、 如果“SubExp1”为贪婪模式,则要尝试所有的可能,取最长的成功匹配项作为匹配结果。
6、 “(?<=SubExp1) ”成功匹配后,控制权交给后面的子表达式,继续尝试匹配。
需要说明的一点,逆序环视中的子表达式“SubExp1”,匹配成功时,匹配开始的位置是不可预知的,但匹配结束的位置一定是位置x。
3 问题分析与总结
3.1 问题分析
那么再回过头来看下最初的问题。
代码如下:
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=<font[\s\S]*?>)([\s\S]*?)(?=</font>)");
foreach (Match m in mc)
{
richTextBox2.Text += m.Value + "\n---------------\n";
}
/*--------输出--------
** 这里是不固定的字符串1 **
---------------
<font color="#008000"> ** 这里是不固定的字符串2 **
---------------
<font color="#008000"> ** 这里是不固定的字符串3 **
---------------
*/
其实真正让人费解的是这里的逆序环视的匹配结果,为了更好的说明问题,改下正则。
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
代码如下:
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=(<font[\s\S]*?>))([\s\S]*?)(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "轮成功匹配结果:\n";
richTextBox2.Text += "Group[0]:" + m.Value + "\n";
richTextBox2.Text += "Group[1]:" + m.Groups[1].Value + "\n---------------\n";
}
/*--------输出--------
第1轮成功匹配结果:
Group[0]: ** 这里是不固定的字符串1 **
Group[1]:<font color="#008000">
---------------
第2轮成功匹配结果:
Group[0]:
<font color="#008000"> ** 这里是不固定的字符串2 **
Group[1]:<font color="#008000"> ** 这里是不固定的字符串1 ** </font>
---------------
第3轮成功匹配结果:
Group[0]:
<font color="#008000"> ** 这里是不固定的字符串3 **
Group[1]:<font color="#008000"> ** 这里是不固定的字符串2 ** </font>
---------------
*/
对于第一轮成功匹配结果应该不存在什么疑问,这里不做解释。
第一轮成功匹配结束的位置是第一个“</font>”前的位置,第二轮成功匹配尝试就是从这一位置开始。
首先由“(?<=<font[\s\S]*?>)”取得控制权,向左查找6个字符后开始尝试匹配,由于“<”会匹配失败,所以会一直尝试到位置0处,这时“<font”是可以匹配成功的,但是由于“<font[\s\S]*?>”要匹配成功,匹配的结束位置必须是第一个“</font>”前的位置,所以“>”是匹配失败的,这一位置整个表达式匹配失败。
正则引擎传动装置向右传动,直到第一个“</font>”后的位置,“<font[\s\S]*?>”匹配成功,匹配开始位置是位置0,匹配结束位置是第一个“</font>”后的位置,“<font[\s\S]*?>”匹配到的内容是“<font color="#008000"> ** 这里是不固定的字符串1 ** </font>”,其中“[\s\S]*?”匹配到的内容是“color="#008000"> ** 这里是不固定的字符串1 ** </font”,后面的子表达式继续匹配,直到第二轮匹配成功。
接下来的第三轮成功匹配,匹配过程与第二轮基本相同,只不过由于使用的是非贪婪模式,所以“<font[\s\S]*?>”在匹配到“<font color="#008000"> ** 这里是不固定的字符串2 ** </font>”时匹配成功,就结束匹配,不再向左尝试匹配了。
接下来看下贪婪模式的匹配结果。
代码如下:
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=(<font[\s\S]*>))([\s\S]*?)(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "轮成功匹配结果:\n";
richTextBox2.Text += "Group[0]:" + m.Value + "\n";
richTextBox2.Text += "Group[1]:" + m.Groups[1].Value + "\n---------------\n";
}
/*--------输出--------
第1轮匹配结果:
Group[0]: ** 这里是不固定的字符串1 **
Group[1]:<font color="#008000">
---------------
第2轮匹配结果:
Group[0]:
<font color="#008000"> ** 这里是不固定的字符串2 **
Group[1]:<font color="#008000"> ** 这里是不固定的字符串1 ** </font>
---------------
第3轮匹配结果:
Group[0]:
<font color="#008000"> ** 这里是不固定的字符串3 **
Group[1]:<font color="#008000"> ** 这里是不固定的字符串1 ** </font>
<font color="#008000"> ** 这里是不固定的字符串2 ** </font>
---------------
*/
仅仅是一个字符的差别,整个表达式的匹配结果没有变化,但匹配过程差别却是很大的。
那么如果想得到下面这种结果要如何做呢?
/*--------输出--------
** 这里是不固定的字符串1 **
---------------
** 这里是不固定的字符串2 **
---------------
** 这里是不固定的字符串3 **
---------------
*/
string test = @"<font color=""#008000""> ** 这里是不固定的字符串1 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串2 ** </font>
<font color=""#008000""> ** 这里是不固定的字符串3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?is)(?<=(<font[^>]*>))(?:(?!</?font\b).)*(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "轮匹配结果:\n";
richTextBox2.Text += "Group[0]:" + mc[i].Value + "\n";
richTextBox2.Text += "Group[1]:" + mc[i].Groups[1].Value + "\n---------------\n";
}
/*--------输出--------
第1轮匹配结果:
Group[0]: ** 这里是不固定的字符串1 **
Group[1]:<font color="#008000">
---------------
第2轮匹配结果:
Group[0]: ** 这里是不固定的字符串2 **
Group[1]:<font color="#008000">
---------------
第3轮匹配结果:
Group[0]: ** 这里是不固定的字符串3 **
Group[1]:<font color="#008000">
---------------
*/
3.2 逆序环视应用总结
通过对逆序环视的分析,可以看出,逆序环视中使用不定长度的量词,匹配过程很复杂,代价也是很大的,这也许也是目前绝大多数语言不支持逆序环视,或是不支持在逆序环视中使用不定长度量词的原因吧。
在正则应用中需要注意的几点:
1、 不要轻易在逆序环视中使用不定长度的量词,除非确实需要;
2、 在任何场景下,不只是逆序环视中,不要轻易使用量词修饰匹配范围非常大的子表达式,小数点“.”和“[\s\S]”之类的,使用时尤其要注意。
相关推荐
-

正则匹配原理之 逆序环视深入 .
说明:部分内容有待进一步研究和修正,因为最近工作太忙,暂时抽不出时间来,未研究过的可以跳过这一篇,想研究的不要被我的思路所左右了,有研究清楚的还请指正1 问题引出 前几天在CSDN论坛遇到这样一个问题: var str="8912341253789"; 需要将这个字符串中的重复的数字给去掉,也就是结果89123457. 首先需要说明的是,这种需求并不适合用正则来实现,至少,正则不是最好的实现方式. 这个问题本身不是本文讨论的重点,本文所要讨论的,主要是由这一问题的解决方案而引出的另一个
-
正则表达式零宽断言详解
正则表达式零宽断言: 零宽断言是正则表达式中的难点,所以本章节重点从匹配原理方面进行一下分析.零宽断言还有其他的名称,例如"环视"或者"预搜索"等等,不过这些都不是我们关注的重点. 一.基本概念: 零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已. 作用是给指定位置添加一个限定条件,用来规定此位置之前或者之后的字符必须满足限定条件才能使正则中的字表达式匹配成功. 注意:这里所说的子表达式并非只有用小括号
-
正则表达式之零宽断言实例详解【基于PHP】
本文实例讲述了正则表达式之零宽断言.分享给大家供大家参考,具体如下: 前言 之前我曾写了一篇关于正则表达式的文章(http://www.jb51.net/article/111359.htm) 在该文章中详细介绍了正则,但是关于零宽断言介绍却是很少提及到.现在将该内容补充一下.在本文中,主要解决如下问题: ① 什么是零宽断言,为什么要使用零宽断言 ② 怎样使用零宽断言 概念 零宽断言,大多地方这样定义它,用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像 \b ^ $ \<
-
正则表达式断言、巡视(Assertions)、正向断言、反向断言介绍
断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置.详细可以看看,正则表达式匹配解析过程探讨分析(正则表达式匹配原理),里面提到"零宽度"很多元字符,只是对特殊位置进行匹配,它们可以理解为断言. 断言元字符 常见断言元字符有: \b, \B, \A, \Z, \z, ^ ,$ 它们只是表示特殊位置,各自作用如有字符串AB,带位置表示为:0A1B2 元字符
-
正则基础之 环视 Lookaround
1 环视基础 环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的.环视匹配的最终结果就是一个位置. 环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功. 环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视.顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件. 表达式 说明 (?<=Expression) 逆序肯定环视,表示所在位置左侧能够匹配Exp
-
javascript 正则表达式分组、断言详解
javascript 正则表达式分组.断言详解 提示:阅读本文需要有一定的正则表达式基础. 正则表达式中的断言,作为高级应用出现,倒不是因为它有多难,而是概念比较抽象,不容易理解而已,今天就让小菜通俗的讲解一下. 如果不用断言,以往用过的那些表达式,仅仅能获取到有规律的字符串,而不能获取无规律的字符串. 举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的.因
-
正则表达式中环视的简单应用示例【基于java】
本文实例讲述了正则表达式中环视的简单应用.分享给大家供大家参考,具体如下: 由于开发工作需要对文本中内容进行过滤,删除或替换掉一些无用的或不符合要求的信息.于是发现一个问题,某一类工程性文本中,用到很多英文写法相同.但含义不同的单位,需要将其分别转为真实含义对应的汉字.比如:"粘度为17s,移动距离为350厘米,要求混凝土必须内实外光.振捣时间为30s.",很明显第一个s是粘度的单位,第二s是时间单位,现在需要将文本中所有表示时间的s替换为"秒",在朋友指引下,发现
-
正则表达式环视概念与用法分析
本文实例讲述了正则表达式环视概念与用法.分享给大家供大家参考,具体如下: 1.环视又叫预搜索和零宽断言 2.环视又划分为 (?=exp)肯定顺序环视 (?<=exp)肯定逆序环视 (?!exp)否定顺序环视 (?<exp)否定逆序环视 3.环视只占用逻辑位置 不占用物理位置 如:匹配后缀名字为txt的文件 字符:file.txt.file2.exe 正则 \w(?=.exe) 匹配字符串file2 4.环视的用法 (?=exp)肯定顺序环视的2种用法 ① 查找电话号码是132开头的电话 字符:
-
正则应用之 逆序环视探索 .
1 问题引出 前几天在CSDN论坛遇到这样一个问题. 我要通过正则分别取出下面 <font color="#008000"> 与 </font> 之间的字符串 1.在 <font color="#008000"> 与 </font> 之间的字符串是没法固定的,是随机自动生成的 2.其中 <font color="#008000"> 与 </font>的数量也是没法固定的,也是
-
PHP字符串逆序排列实现方法小结【strrev函数,二分法,循环法,递归法】
本文实例总结了PHP字符串逆序排列实现方法.分享给大家供大家参考,具体如下: 关于字符串的逆序排列,最简单的使用PHP函数strrev()的测试代码如下: header('Content-type: text/html; charset=utf-8'); $str = implode('', range(9, 0)); print '< p><strong>Before reversed: </strong>'.$str.'< /p>'; print '&l
-
java使用listIterator逆序arraylist示例分享
思路分析:要逆序遍历某个列表,首先要获得一个ListIterator对象,利用for()循环,以ListIterator类的hasNext()方法作为判断条件,通过循环执行ListIterator类的next()方法将游标定位到列表结尾,然后在另一个for循环中,以ListIterator类的hasPrevious()方法作为判断条件,通过ListIterator类的previous()方法逆序输出列表中的元素. 代码如下: 复制代码 代码如下: import java.util.ArrayLi
-
java递归法求字符串逆序
本文实例讲述了java递归法求字符串逆序的方法.分享给大家供大家参考.具体实现方法如下: public static String reverseString(String x) { if(x==null || x.length()<2) return x; return reverseString(x.substring(1,x.length()))+ x.charAt(0); } 希望本文所述对大家的java程序设计有所帮助.
-
Java控制台输入数组并逆序输出的方法实例 原创
输入一个数组,然后颠倒次序进行输出,这种算法在程序开发中经常用到,下面我们通过一个小实例来看看怎么实现在控制台输入一个数组,并让其逆序输出的. 源码: import java.util.Scanner; public class Test01 { public static void main(String[] args){ System.out.println("请输入五个数"); int[]l=new int [5]; for(int i=0;i<5;i++) l[i]=ne
-
Python实现字符串逆序输出功能示例
本文实例讲述了Python实现字符串逆序输出功能.分享给大家供大家参考,具体如下: 1.有时候我们可能想让字符串倒序输出,下面给出几种方法 方法一:通过索引的方法 >>> strA = "abcdegfgijlk" >>> strA[::-1] 'kljigfgedcba' 方法二:借组列表进行翻转 #coding=utf-8 strA = raw_input("请输入需要翻转的字符串:") order = [] for i in
-
C语言实现单链表逆序与逆序输出实例
单链表的逆序输出分为两种情况,一种是只逆序输出,实际上不逆序:另一种是把链表逆序.本文就分别实例讲述一下两种方法.具体如下: 1.逆序输出 实例代码如下: #include<iostream> #include<stack> #include<assert.h> using namespace std; typedef struct node{ int data; node * next; }node; //尾部添加 node * add(int n, node * h
-
JS逆序遍历实现代码
最常用的遍历方式为for语句(也有递归.while方式).当我们遍历一个数组的时候,我们一般会这么做: 复制代码 代码如下: var arr = [1,2,3,4,5,6,7,8,9,10]; for(var i=0,total=arr.length;i<total;i++){ console.log(i,arr[i]); } 这就是最常用的遍历方式:正序遍历.它从数组的第一项依次走到最后一项. 那为什么今天小剧还会提到逆序遍历呢? 这里不得不提下小剧写的组件里最常用的一个模块:events
-
C/C++ 实现递归和栈逆序字符串的实例
C/C++ 实现递归和栈逆序字符串的实例 递归函数调用模型 逆序方法 void revers(char *buf){ char *p = buf; if (p == NULL) { return; } //递归结束条件 if (*p == '\0') { return; } //递归调用 revers(p + 1); //在字符串的结尾追加n个字符 strncat(buf_g, p, 1); } 调用 int main(int argc, const char * argv[]) { char