MYSQL GROUP BY用法详解
背景介绍
最近在设计数据库的时候因为开始考虑不周,所以产生了大量的重复数据。现在需要把这些重复的数据删除掉,使用到的语句就是Group By来完成。为了进一步了解这条语句的作用,我打算先从简单入手。
建一个测试表
create table test_group(id int auto_increment primary key, name varchar(32), class varchar(32), score int);
查看表结构
desc test_group
插入数据

测试开始
我想知道当前每一个班级里面最高分数的同学是谁。
select name, class , max(score) from test_group group by class;

好现在可以插入几条重复的数据。
insert into test_group(name, class, score)values('repeat','B',89);

现在要过滤掉重复的数据,保留最新的那条记录。一般我们假设最新的记录是最后插入的那条,所以它的ID应该是最大的那条。
select name, class, max(id) from test_group group by name;
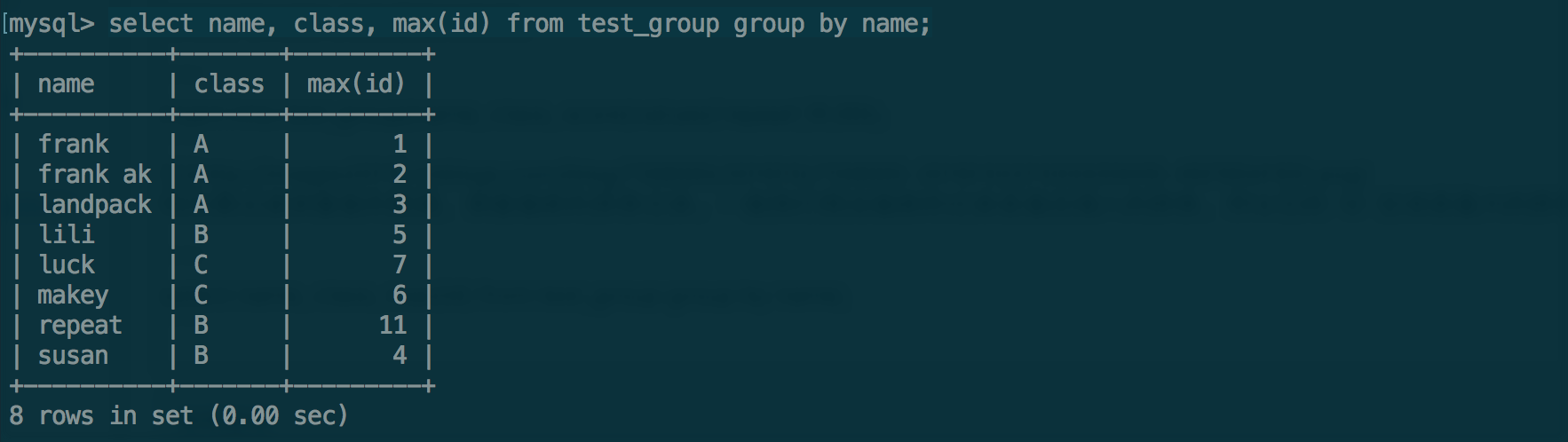
可以发现,我们关注那个项的重复性就把它放到gourp by后面。这样我们就可以过滤掉那些与这个项重复的记录啦。现在我们得到了我们需要的数据,我们下一步就是把那些重复的数据删除。为了区分我们过滤出来的数据记录与原有的记录,我们可以给id取一个别名。
select name, class, max(id) as max_id from test_group group by name;

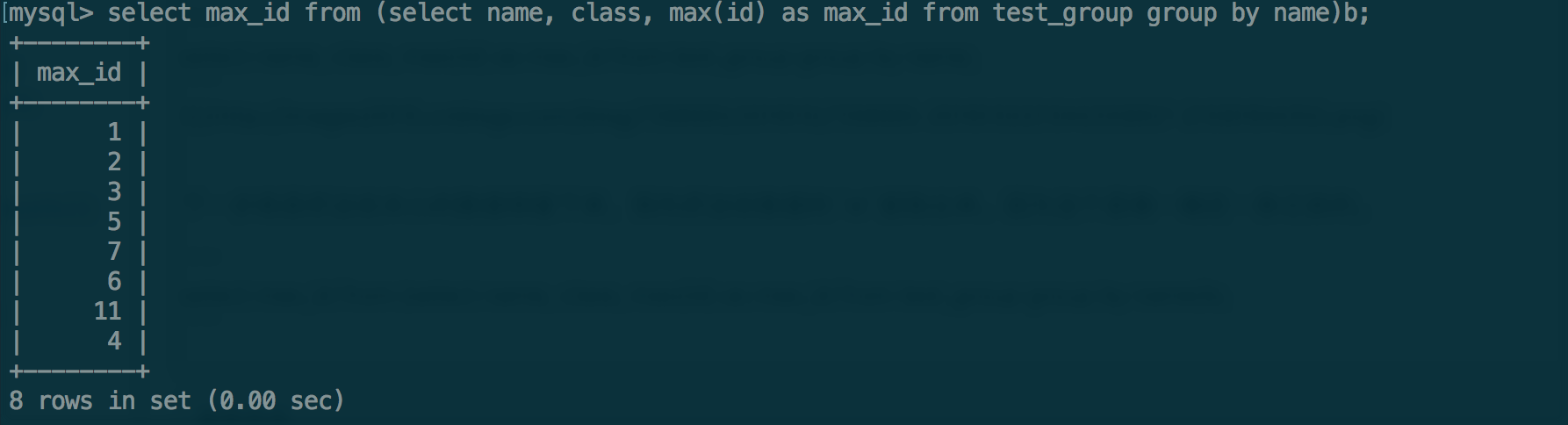
下一步就是把这些关心的数据保留下来,我先把这些数据的id提取出来。因为这个是唯一确定一条记录的。
select max_id from (select name, class, max(id) as max_id from test_group group by name)b;
下面就是删除操作了。思路就是删除那些数据ID不在我们查询结果里面的记录。为了方便操作后对数据的对比,我先进行一次全部查询。
select * from test_group;

执行删除操作。
delete from test_group where id not in (select max_id from (select name, class, max(id) as max_id from test_group group by name)b);
最后查看结果。

总结
MySQL操作还是很灵活的,之前一直喜欢用ORM现在感觉直接使用MYSQL省去了很多事。如果你有更好更高效的方式就请你分享分享吧~~
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
mysql group by having 实例代码
mysql group by having 实例 注意:使用group by的时候,SELECT子句中的列名必须为分组列. 如下实例必须包括name列名,因为name是作为group by分组的条件. 实例: 我的数据库中有一张员工工作记录表,表中的数据库如下: mysql> SELECT * FROM employee_tbl; +------+------+------------+--------------------+ | id | name | work_date | daily_t
-
sql中 order by 和 group by的区别
order by 从英文里理解就是行的排序方式,默认的为升序. order by 后面必须列出排序的字段名,可以是多个字段名. group by 从英文里理解就是分组.必须有"聚合函数"来配合才能使用,使用时至少需要一个分组标志字段. 什么是"聚合函数"? 像sum().count().avg()等都是"聚合函数" 使用group by 的目的就是要将数据分类汇总. 一般如: select 单位名称,count(职工id),sum(职工工资) f
-
SQL GROUP BY 详解及简单实例
GROUP BY 语句用于结合 Aggregate 函数,根据一个或多个列对结果集进行分组. SQL GROUP BY 语法 SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name; 演示数据库 在本教程中,我们将使用众所周知的 Northwind 样本数据库. 下面是选自 "Orders" 表的数据
-
MySQL优化GROUP BY(松散索引扫描与紧凑索引扫描)
满足GROUP BY子句的最一般的方法是扫描整个表并创建一个新的临时表,表中每个组的所有行应为连续的,然后使用该临时表来找到组并应用累积函数(如果有).在某些情况中,MySQL能够做得更好,即通过索引访问而不用创建临时表. 为GROUP BY使用索引的最重要的前提条件是所有GROUP BY列引用同一索引的属性,并且索引按顺序保存其关键字.是否用索引访问来代替临时表的使用还取决于在查询中使用了哪部分索引.为该部分指定的条件,以及选择的累积函数. 由于GROUP BY 实
-

Mysql中错误使用SQL语句Groupby被兼容的情况
首先创建数据库hncu,建立stud表格. 添加数据: create table stud( sno varchar(30) not null primary key, sname varchar(30) not null, age int, saddress varchar(30) ); INSERT INTO stud VALUES('1001','Tom',22,'湖南益阳'); INSERT INTO stud VALUES('1002','Jack',23,'益阳'); INSERT
-
Mysql利用group by分组排序
昨天有个需求对数据库的数据进行去重排名,同一用户去成绩最高,时间最短,参与活动最早的一条数据进行排序.我们可以利用MySQL中的group by的特性. MySQL的group by与Oracle有所不同,查询得字段可以不用写聚合函数,查询结果取得是每一组的第一行记录. 利用上面的特点,可以利用mysql实现一种独特的排序: 首先先按某个字段进行order by,然后把有顺序的表进行分组,这样每组的成员都是有顺序的,而mysql默认取得分组的第一行.从而得到每组的最值. select id, (
-
mysql使用GROUP BY分组实现取前N条记录的方法
本文实例讲述了mysql使用GROUP BY分组实现取前N条记录的方法.分享给大家供大家参考,具体如下: MySQL中GROUP BY分组取前N条记录实现 mysql分组,取记录 GROUP BY之后如何取每组的前两位下面我来讲述mysql中GROUP BY分组取前N条记录实现方法. 这是测试表(也不知道怎么想的,当时表名直接敲了个aa,汗~~~~): 结果: 方法一: 复制代码 代码如下: SELECT a.id,a.SName,a.ClsNo,a.Score FROM aa a LEFT J
-
MySQL分组查询Group By实现原理详解
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作.当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算.所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引. 在MySQL 中,GROUP BY 的实现同样有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成 GROUP BY,另外一种为完全无法使用索引的场景下使用.下面我们分别针对这三种实现方式做一个分
-
MySQL5.7 group by新特性报错1055的解决办法
项目中本来使用的是mysql5.6进行开发,切换到5.7之后,突然发现原来的一些sql运行都报错,错误编码1055,错误信息和sql_mode中的"only_full_group_by"有关,到网上看了原因,说是mysql5.7中only_full_group_by这个模式是默认开启的 解决办法大致有两种: 一:在sql查询语句中不需要group by的字段上使用any_value()函数 当然,这种对于已经开发了不少功能的项目不太合适,毕竟要把原来的sql都给修改一遍 二:修改my.
-
MYSQL GROUP BY用法详解
背景介绍 最近在设计数据库的时候因为开始考虑不周,所以产生了大量的重复数据.现在需要把这些重复的数据删除掉,使用到的语句就是Group By来完成.为了进一步了解这条语句的作用,我打算先从简单入手. 建一个测试表 复制代码 代码如下: create table test_group(id int auto_increment primary key, name varchar(32), class varchar(32), score int); 查看表结构 desc test_group 插入
-
MySQL数据类型DECIMAL用法详解
MySQLDECIMAL数据类型用于在数据库中存储精确的数值.我们经常将DECIMAL数据类型用于保留准确精确度的列,例如会计系统中的货币数据. 要定义数据类型为DECIMAL的列,请使用以下语法: column_name DECIMAL(P,D); 在上面的语法中: P是表示有效数字数的精度.P范围为1〜65. D是表示小数点后的位数.D的范围是0~30.MySQL要求D小于或等于(<=)P. DECIMAL(P,D)表示列可以存储D位小数的P位数.十进制列的实际范围取决于精度和刻度. 与IN
-
MySQL中Truncate用法详解
前言: 当我们想要清空某张表时,往往会使用truncate语句.大多时候我们只关心能否满足需求,而不去想这类语句的使用场景及注意事项.本篇文章主要介绍truncate语句的使用方法及注意事项. 1.truncate使用语法 truncate的作用是清空表或者说是截断表,只能作用于表.truncate的语法很简单,后面直接跟表名即可,例如: truncate table tbl_name 或者 truncate tbl_name . 执行truncate语句需要拥有表的drop权限,从逻辑上讲,t
-
mysql中explain用法详解
如果在select语句前放上关键词explain,mysql将解释它如何处理select,提供有关表如何联接和联接的次序. explain的每个输出行提供一个表的相关信息,并且每个行包括下面的列: 1,id select识别符.这是select的查询序列号.2,select_type 可以为一下任何一种类型simple 简单select(不使用union或子查询)primary 最外面的selectunion union中的第二个或后面的select语句dependent uni
-
php中mysql操作buffer用法详解
本文实例讲述了php中mysql操作buffer用法.分享给大家供大家参考.具体分析如下: php与mysql的连接有三种方式,mysql,mysqli,pdo.不管使用哪种方式进行连接,都有使用buffer和不使用buffer的区别. 什么叫使用buffer和不使用buffer呢? 客户端与mysql服务端进行查询操作,查询操作的时候如果获取的数据量比较大,那个这个查询结果放在哪里呢? 有两个地方可以放:客户端的缓冲区和服务端的缓冲区. 我们这里说的buffer指的是客户端的缓冲区,如果查询结
-
MySQL触发器基本用法详解【创建、查看、删除等】
本文实例讲述了MySQL触发器基本用法.分享给大家供大家参考,具体如下: 一.MySQL触发器创建: 1.MySQL触发器的创建语法: CREATE [DEFINER = { 'user' | CURRENT_USER }] TRIGGER trigger_name trigger_time trigger_event ON table_name FOR EACH ROW [trigger_order] trigger_body 2.MySQL创建语法中的关键词解释: 字段 含义 可能的值 DE
-
mysql prompt的用法详解
prompt命令可以在mysql提示符中显示当前用户.数据库.时间等信息 复制代码 代码如下: mysql -uroot -p --prompt="\\u@\\h:\\d \\r:\\m:\\s>" 设置成功后: 复制代码 代码如下: Welcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 5Server version: 5.1.60-log Source dist
-
group by用法详解
一. 概述 group_by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组. 二. 语法 select 字段 from 表名 where 条件 group by 字段 或者 select 字段 from 表名 group by 字段 having 过滤条件 注意:对于过滤条件,可以先用where,再用group by或者是先用group by,再用having 三. 案例 1
-
group by用法详解
一. 概述 group_by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组. 二. 语法 select 字段 from 表名 where 条件 group by 字段 或者 select 字段 from 表名 group by 字段 having 过滤条件 注意:对于过滤条件,可以先用where,再用group by或者是先用group by,再用having 三. 案例 1
-
mysql之explain使用详解(分析索引)
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了,如: explain select * from statuses_status where id=11; explain列的解释 table:显示这一行的数据是关于哪张表的 type:这是重要的列,显示连接使用了何种类型.从最好到最差的连接类型为const.eq_reg.ref.range.indexhe和all