React的diff算法核心复用图文详解
目录
- 引言
- Fiber 架构
- React 的 diff 算法
- 总结
引言
React 是基于 vdom 的前端框架,组件 render 产生 vdom,然后渲染器把 vdom 渲染出来。
state 更新的时候,组件会重新 render,产生新的 vdom,在浏览器平台下,为了减少 dom 的创建,React 会对两次的 render 结果做 diff,尽量复用 dom,提高性能。
diff 算法是前端框架中比较复杂的部分,代码比较多,但今天我们不上代码,只看图来理解它。
首先,我们先过一下 react 的 fiber 架构:
Fiber 架构
React 是通过 jsx 描述页面结构的:
const profile = {
return <div>
<img src="avatar.png" className="profile" />
<h3>{[user.firstName, user.lastName].join(" ")}</h3>
</div>
经过 babel 等的编译会变成 render function:
import { jsx as _jsx } from "react/jsx-runtime";
import { jsxs as _jsxs } from "react/jsx-runtime";
const profile = _jsxs("div", {
children: [
_jsx("img", {
src: "avatar.png",
className: "profile",
}),
_jsx("h3", {
children: [user.firstName, user.lastName].join(" "),
}),
],
});
render function 执行结果就是 vdom,也就是 React Element 的实例:

在 16 之前,React 是直接递归渲染 vdom 的,setState 会触发重新渲染,对比渲染出的新旧 vdom,对差异部分进行 dom 操作。
在 16 之后,为了优化性能,会先把 vdom 转换成 fiber,也就是从树转换成链表,然后再渲染。整体渲染流程分成了两个阶段:
- render 阶段:从 vdom 转换成 fiber,并且对需要 dom 操作的节点打上 effectTag 的标记
- commit 阶段:对有 effectTag 标记的 fiber 节点进行 dom 操作,并执行所有的 effect 副作用函数。
从 vdom 转成 fiber 的过程叫做 reconcile(调和),这个过程是可以打断的,由 scheduler 调度执行。
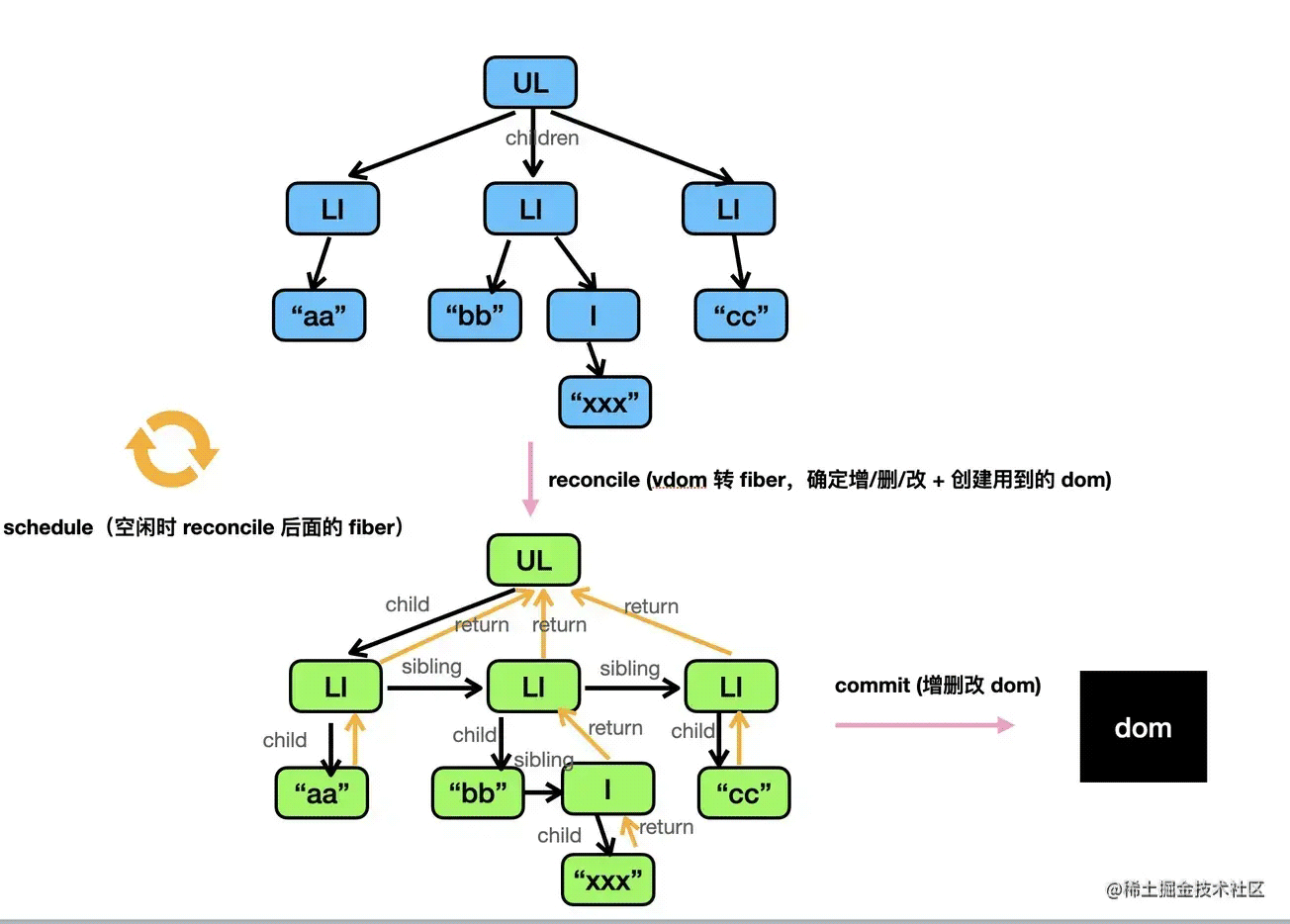
diff 算法作用在 reconcile 阶段:
第一次渲染不需要 diff,直接 vdom 转 fiber。
再次渲染的时候,会产生新的 vdom,这时候要和之前的 fiber 做下对比,决定怎么产生新的 fiber,对可复用的节点打上修改的标记,剩余的旧节点打上删除标记,新节点打上新增标记。
接下来我们就来详细了解下 React 的 diff 算法:
React 的 diff 算法
在讲 diff 算法实现之前,我们要先想明白为什么要做 diff,不做行么?
当然可以,每一次渲染都直接把 vdom 转成 fiber 就行,不用和之前的做对比,这样是可行的。
其实 SSR 的时候就不用做 diff,因为会把组件渲染成字符串,第二次渲染也是产生字符串,难道这时候还要和之前的字符串对比下,有哪些字符串可以复用么?
不需要,SSR 的时候就没有 diff,每次都是 vdom 渲染出新的字符串。
那为什么浏览器里要做 diff 呢?
因为 dom 创建的性能成本很高,如果不做 dom 的复用,那前端框架的性能就太差了。
diff 算法的目的就是对比两次渲染结果,找到可复用的部分,然后剩下的该删除删除,该新增新增。
那具体怎么实现 React 的 diff 算法呢?
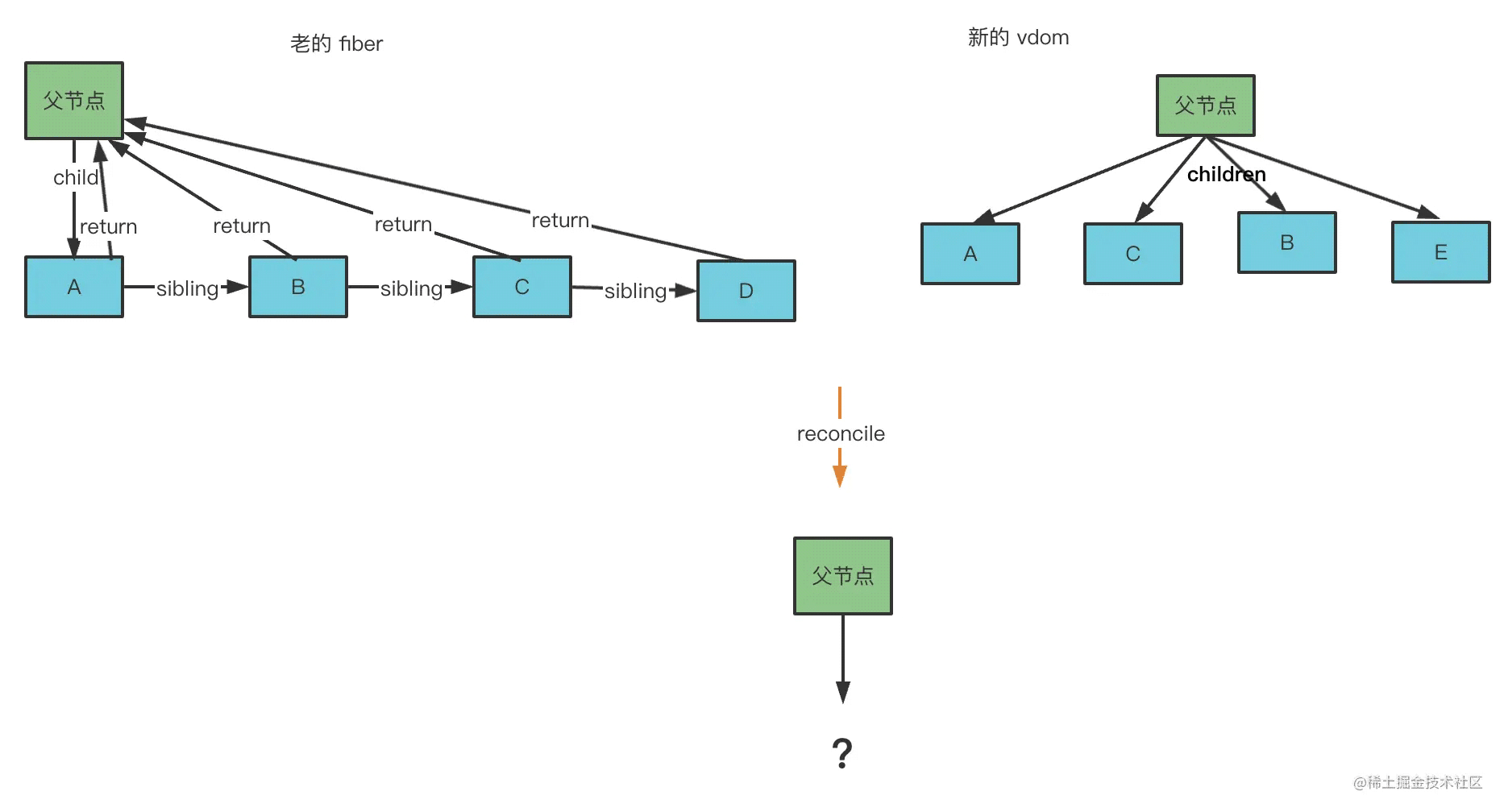
比如父节点下有 A、B、C、D 四个子节点,那渲染出的 vdom 就是这样的:

经过 reconcile 之后,会变成这样的 fiber 结构:

那如果再次渲染的时候,渲染出了 A、C、B、E 的 vdom,这时候怎么处理呢?
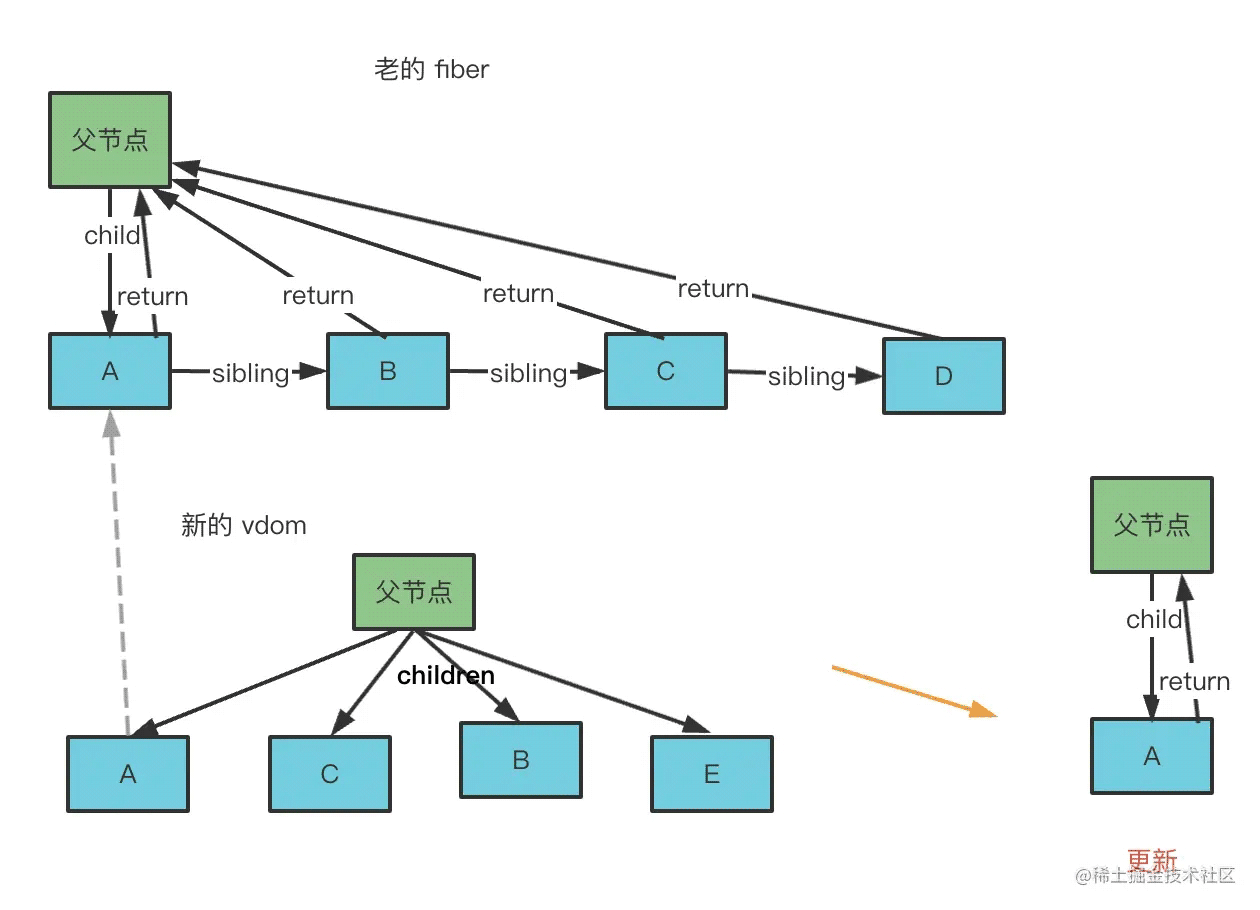
再次渲染出 vdom 的时候,也要进行 vdom 转 fiber 的 reconcile 阶段,但是要尽量能复用之前的节点。
那怎么复用呢?
一一对比下不就行了?
先把之前的 fiber 节点放到一个 map 里,key 就是节点的 key:

然后每个新的 vdom 都去这个 map 里查找下有没有可以复用的,找到了的话就移动过来,打上更新的 effectTag:

这样遍历完 vdom 节点之后,map 里剩下一些,这些是不可复用的,那就删掉,打上删除的 effectTag;如果 vdom 中还有一些没找到复用节点的,就直接创建,打上新增的 effectTag。
这样就实现了更新时的 reconcile,也就是上面的 diff 算法。其实核心就是找到可复用的节点,剩下的旧节点删掉,新节点新增。
但有的时候可以再简化一下,比如上次渲染是 A、B、C、D,这次渲染也是 A、B、C、D,那直接顺序对比下就行,没必要建立 map 再找。
所以 React 的 diff 算法是分成两次遍历的:
第一轮遍历,一一对比 vdom 和老的 fiber,如果可以复用就处理下一个节点,否则就结束遍历。
如果所有的新的 vdom 处理完了,那就把剩下的老 fiber 节点删掉就行。
如果还有 vdom 没处理,那就进行第二次遍历:
第二轮遍历,把剩下的老 fiber 放到 map 里,遍历剩下的 vdom,从 map 里查找,如果找到了,就移动过来。
第二轮遍历完了之后,把剩余的老 fiber 删掉,剩余的 vdom 新增。
这样就完成了新的 fiber 结构的创建,也就是 reconcile 的过程。
比如上面那个例子,第一轮遍历就是这样的:
一一对比新的 vdom 和 老的 fiber,发现 A 是可以复用的,那就创建新 fiber 节点,打上更新标记。
C 不可复用,所以结束第一轮遍历,进入第二轮遍历。
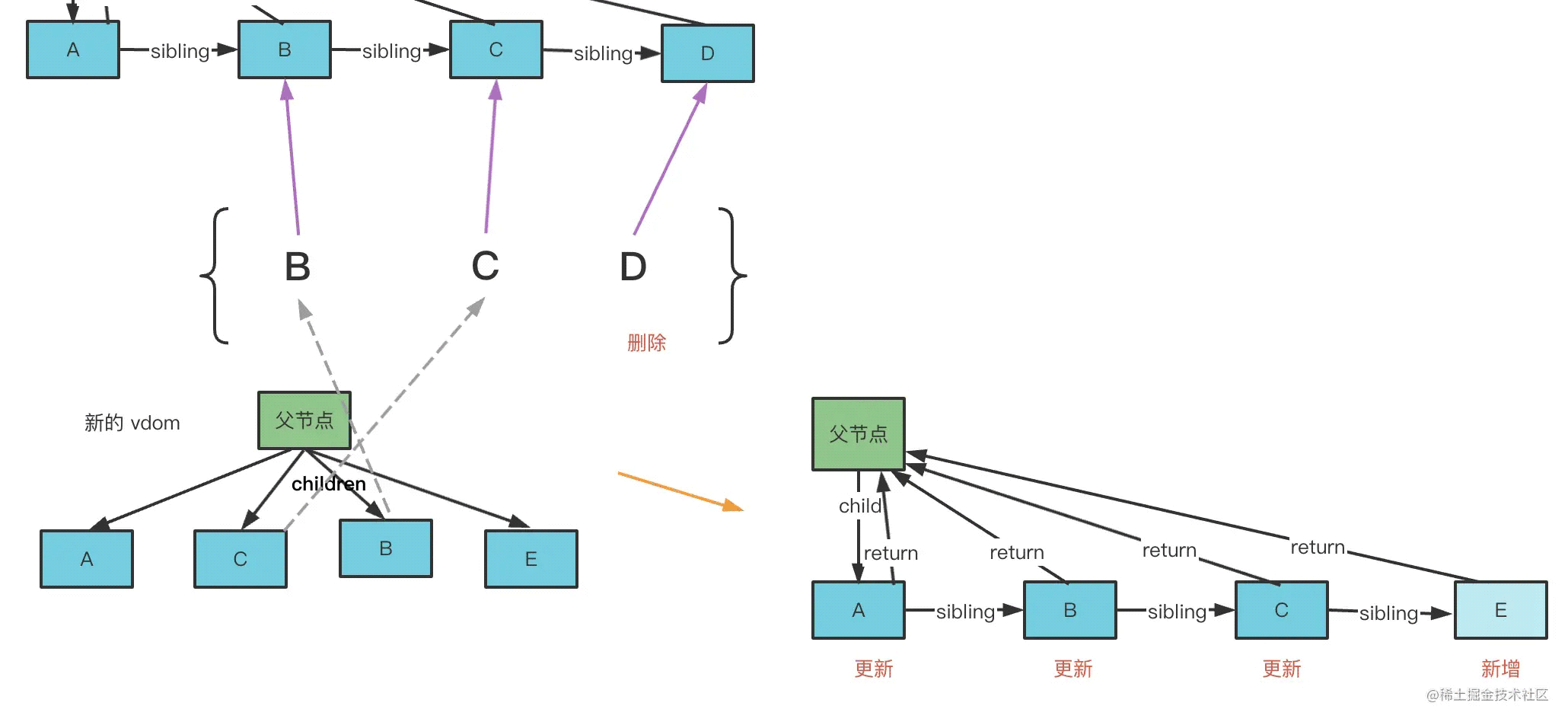
把剩下的 老 fiber 节点放到 map 里,然后遍历新的 vdom 节点,从 map 中能找到的话,就是可复用,移动过来打上更新的标记。
遍历完之后,剩下的老 fiber 节点删掉,剩下的新 vdom 新增。
这样就完成了更新时的 reconcile 的过程。
总结
react 是基于 vdom 的前端框架,组件渲染产生 vdom,渲染器把 vdom 渲染成 dom。
浏览器下使用 react-dom 的渲染器,会先把 vdom 转成 fiber,找到需要更新 dom 的部分,打上增删改的 effectTag 标记,这个过程叫做 reconcile,可以打断,由 scheducler 调度执行。reconcile 结束之后一次性根据 effectTag 更新 dom,叫做 commit。
这就是 react 的基于 fiber 的渲染流程,分成 render(reconcile + schedule)、commit 两个阶段。
当渲染完一次,产生了 fiber 之后,再次渲染的 vdom 要和之前的 fiber 对比下,再决定如何产生新的 fiber,目标是尽可能复用已有的 fiber 节点,这叫做 diff 算法。
react 的 diff 算法分为两个阶段:
第一个阶段一一对比,如果可以复用就下一个,不可以复用就结束。
第二个阶段把剩下的老 fiber 放到 map 里,遍历剩余的 vdom,一一查找 map 中是否有可复用的节点。
最后把剩下的老 fiber 删掉,剩下的新 vdom 新增。
这样就完成了更新时的 reconcile 过程。
其实 diff 算法的核心就是复用节点,通过一一对比也好,通过 map 查找也好,都是为了找到可复用的节点,移动过来。然后剩下的该删删该增增。
理解了如何找到可复用的节点,就理解了 diff 算法的核心。
以上就是 React的diff算法核心复用详解的详细内容,更多关于React diff 算法复用的资料请关注我们其它相关文章!
相关推荐
-
react diff算法源码解析
React中Diff算法又称为调和算法,对应函数名为reconcileChildren,它的主要作用是标记更新过程中那些元素发生了变化,这些变化包括新增.移动.删除.过程发生在beginWork阶段,只有非初次渲染才会Diff. 以前看过一些文章将Diff算法表述为两颗Fiber树的比较,这是不正确的,实际的Diff过程是一组现有的Fiber节点和新的由JSX生成的ReactElement的比较,然后生成新的Fiber节点的过程,这个过程中也会尝试复用现有Fiber节点. 节点Diff又分为两种
-
react中的虚拟dom和diff算法详解
虚拟DOM的作用 首先我们要知道虚拟dom的出现是为了解决什么问题的,他解决我们平时频繁的直接操作DOM效率低下的问题.那么为什么我们直接操作DOM效率会低下呢? 比如我们创建一个div,我们可以在控制台查看一下这个div上自带或者继承了很多属性,尤其是我们使用js操作DOM的时候,我们的DOM本身就很复杂,js的操作也会占用很多时间,但是我们控制不了DOM元素本身,因此虚拟DOM解决的是js操作DOM这一层面,其实解决的是减少了操作dom的次数 简单实现虚拟DOM 虚拟DOM,见名知意,就是假
-

react diff 算法实现思路及原理解析
目录 事例分析 diff 特点 diff 思路 实现 diff 算法 修改入口文件 实现 React.Fragment 我们需要修改 children 对比 前面几节我们学习了解了 react 的渲染机制和生命周期,本节我们正式进入基本面试必考的核心地带 -- diff 算法,了解如何优化和复用 dom 操作的,还有我们常见的 key 的作用. diff 算法使用在子都是数组的情况下,这点和 vue 是一样的.如果元素是其他类型的话直接替换就好. 事例分析 按照之前的 diff 写法,如果元素不
-
深入浅析React中diff算法
React中diff算法的理解 diff算法用来计算出Virtual DOM中改变的部分,然后针对该部分进行DOM操作,而不用重新渲染整个页面,渲染整个DOM结构的过程中开销是很大的,需要浏览器对DOM结构进行重绘与回流,而diff算法能够使得操作过程中只更新修改的那部分DOM结构而不更新整个DOM,这样能够最小化操作DOM结构,能够最大程度上减少浏览器重绘与回流的规模. 虚拟DOM diff算法的基础是Virtual DOM,Virtual DOM是一棵以JavaScript对象作为基础的树,
-
详解react应用中的DOM DIFF算法
前言 对我们搞前端的来说,目前最流行的两大前端框架毫无疑问当属React和Vue,对于这两大框架,想必大家也是再熟悉不过了.然而,这两大框架无一例外的全部放弃使用传统的DOM技术,却采用了以JS为基础的Virtual DOM技术,也可称作虚拟DOM.所以,到底什么是Virtual DOM?两大热门框架全部使用Virtual DOM的原因又是什么?接下来让我这个搞前端的人来好好地为您讲解一下DOM DIFF算法的牛逼之处. 什么是Virtual DOM? 如字面意思所说,Virtual DOM即
-
React的diff算法核心复用图文详解
目录 引言 Fiber 架构 React 的 diff 算法 总结 引言 React 是基于 vdom 的前端框架,组件 render 产生 vdom,然后渲染器把 vdom 渲染出来. state 更新的时候,组件会重新 render,产生新的 vdom,在浏览器平台下,为了减少 dom 的创建,React 会对两次的 render 结果做 diff,尽量复用 dom,提高性能. diff 算法是前端框架中比较复杂的部分,代码比较多,但今天我们不上代码,只看图来理解它. 首先,我们先过一下 r
-
React 之最小堆min heap图文详解
目录 二叉树 完全二叉树 二叉堆 最小堆 React 采用原因 React 函数实现 插入过程(push) >>> 1 删除过程(pop) halfLength peek 二叉树 二叉树(Binary tree),每个节点最多只有两个分支的树结构.通常分支被称作“左子树”或“右子树”.二叉树的分支具有左右次序,不能随意颠倒. 完全二叉树 在一颗二叉树中,若除最后一层外的其余层都是满的,并且最后一层要么是满的,要么在右边缺少连续若干节点,则此二叉树为完全二叉树(Complete Binar
-
vue组件三大核心概念图文详解
前言 本文主要介绍属性.事件和插槽这三个vue基础概念.使用方法及其容易被忽略的一些重要细节.如果你阅读别人写的组件,也可以从这三个部分展开,它们可以帮助你快速了解一个组件的所有功能. 本文的代码请猛戳 github博客 ,纸上得来终觉浅,大家动手多敲敲代码! 一.属性 1.自定义属性props prop 定义了这个组件有哪些可配置的属性,组件的核心功能也都是它来确定的.写通用组件时,props 最好用对象的写法,这样可以针对每个属性设置类型.默认值或自定义校验属性的值,这点在组件开发中很重要,
-
react底层的四大核心内容架构详解
目录 react react-dom react-reconciler scheduler 总结 react 提供定义 react 组件(ReactElement)的必要函数, 一般来说需要和渲染器(react-dom,react-native)一同使用. 在编写react应用的代码时, 大部分都是调用此包的 api.如React.Component 开发时使用的绝大部分api class 组件中使用setState() function 组件里面使用 hook,并发起dispatchActio
-
MapReduce核心思想图文详解
MapReduce核心编程思想,如图1-1所示. 图1-1 MapReduce核心编程思想 1)分布式的运算程序往往需要分成至少2个阶段. 2)第一个阶段的MapTask并发实例,完全并行运行,互不相干. 3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出. 4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行. 小结:分析WordC
-
vue2从数据变化到视图变化之diff算法图文详解
目录 引言 1.isUndef(oldStartVnode) 2.isUndef(oldEndVnode) 3.sameVnode(oldStartVnode, newStartVnode) 4.sameVnode(oldEndVnode, newEndVnode) 5.sameVnode(oldStartVnode, newEndVnode) 6.sameVnode(oldEndVnode, newStartVnode) 7.如果以上都不满足 小结 引言 vue数据的渲染会引入视图的重新渲染.
-
通俗易懂的C++前缀和与差分算法图文详解
目录 1.前缀和 2.前缀和算法有什么好处? 3.二维前缀和 4.差分 5.一维差分 6.二维差分 1.前缀和 前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和,而差分可以看成前缀和的逆运算.合理的使用前缀和与差分,可以将某些复杂的问题简单化. 2.前缀和算法有什么好处? 先来了解这样一个问题: 输入一个长度为n的整数序列.接下来再输入m个询问,每个询问输入一对l, r.对于每个询问,输出原序列中从第l个数到第r个数的和. 我们很容易想出暴力解法,遍历区间求和. 代码如下: in
-
图文详解感知机算法原理及Python实现
目录 写在前面 1.什么是线性模型 2.感知机概述 3.手推感知机原理 4.Python实现 4.1 创建感知机类 4.2 更新权重与偏置 4.3 判断误分类点 4.4 训练感知机 4.5 动图可视化 5.总结 写在前面 机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用.“深”在详细推导算法模型背后的数学原理:“广”在分析多个机器学习模型:决策树.支持向量机.贝叶斯与马尔科夫决策.强化学习等. 本期目标:实现这样一个效果 1.什么是线性模型 线性模型的假设形式是属性权重.偏置与属性
-
图文详解牛顿迭代算法原理及Python实现
目录 1.引例 2.牛顿迭代算法求根 3.牛顿迭代优化 4 代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何计算函数零点x0 在数学上我们如何处理这个问题? 最简单的办法是解方程f(x)=0,在代数学上还有著名的零点判定定理 如果函数y=f(x)在区间[a,b]上的图象是连续不断的一条曲线,并且有f(a)⋅f(b)<0,那么函数y=f(x)在区间(a,b)内有零点,即至少存在一个c∈(a,b),使得f(c)=0,这个c也就是方程f(x)=0的根. 然而,数学上的方法并不一定