Java Set接口及常用实现类总结
目录
- 前言
- 概述
- Set 无序性与不可重复性的理解
- 无序性
- 不可重复性
- Set 接口常用实现类
- HashSet
- LinkedHashSet
- TreeSet
前言
Collection的另一个子接口就是Set,他并没有我们List常用,并且自身也没有一些额外的方法,全是继承自Collection中的,因此我们还是简单总结一下,包括他的常用实现类HashSet、LinkedHashSet、TreeSet的总结!
概述
- Set 接口是 Collection 的子接口, set 接口没有提供额外的方法。
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个
Set 集合中,则添加操作失败。 - Set 判断两个对象是否相同不是使用 == 运算符,而是根据equals()方法。
Set 无序性与不可重复性的理解
无序性
不等于随机性。
public static void main(String[] args) {
Set set = new HashSet();
set.add("aniu");
set.add(666);
set.add("yyds");
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
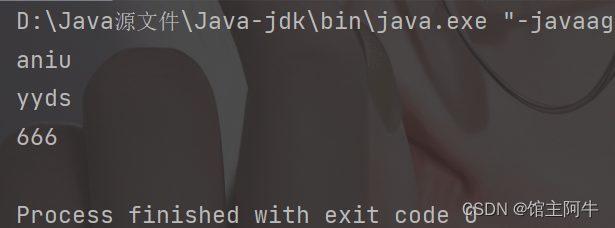
可以看到,他遍历输出的结果不同于元素添加顺序。但千万不要认为这就是无序性,这一点你可以对比LinkedHashSet,他也是无序的,但他区别于HashSet,他可以按照添加顺讯遍历Set。因此,这里无序性要从底层存储数据的角度理解:Set存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值。
不可重复性
保证添加的元素按照equals()判断时,不能返回True,即相同的元素只能添加一个。
需要注意的是,对于自定义类实现的对象,一定要重写hashcode和equals方法才能保证判断他们是否相等。
可以看下面这段代码:
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* @Author:Aniu
* @Date:2023/1/5 17:24
* @description TODO
*/
public class Demo {
public static void main(String[] args) {
Set set = new HashSet();
set.add("aniu");
set.add(666);
set.add("yyds");
set.add(new Stu("aniu",21));
set.add(new Stu("aniu",21));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
class Stu{
String name;
int age;
public Stu(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Stu{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Stu)) return false;
Stu stu = (Stu) o;
if (age != stu.age) return false;
return name != null ? name.equals(stu.name) : stu.name == null;
}
}
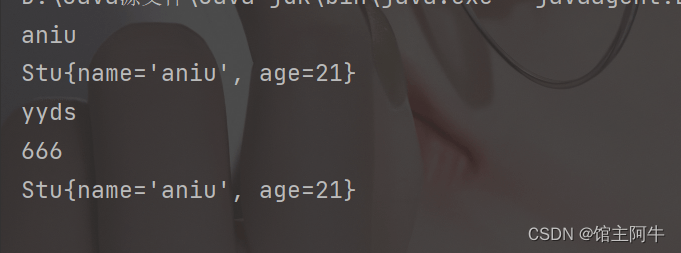
可以发现我们之只重写equals是不行的!
重写hashcode后再看结果:
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
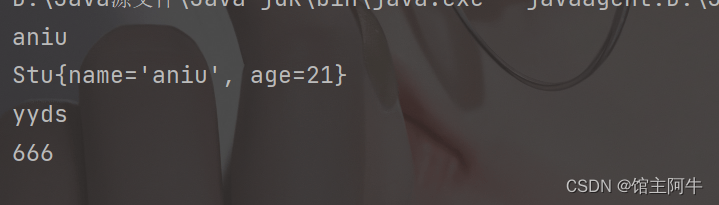
可以看到成功去掉了自定义对象的重复。这个和Set的底层存储原理有关,我们下面会写到!
Set 接口常用实现类
HashSet
作为Set接口的主要实现类,他是线程不安全的,可以存储null值!
HashSet中元素的添加过程
我们以HashSet为例,来大概说一下Set元素的添加过程:
我们向 Hashset 中添加元素 a ,首先调用元素 a 所在类的 hashcode ()方法,计算元素 a 的哈希值,此哈希值接着通过某种算法计算出 HashSet 底层数组中的存放位置(即为:索引位置),判断数组此位置上是否已经有元素:
1.如果此位置上没有其他元素,则元素 a 添加成功。
2.如果此位置上有其他元素(或以链表形式存在的多个元素),则比较元素a与元素 b 的 hash 值:
a.如果 hash 值不相同,则元素 a 添加成功。
b.如果 hash 值相同,进而需要调用元素 a 所在类的 equals ()方法:
- equals ()返回 true ,元素 a 添加失败
- equaLs ()返回 false ,则元素 a 添加成功。
对于添加成功的而言,如果通过hash值计算出的数组索引相同,则元素 a 与已经存在指定索引位置上数据以链表的方式存储。
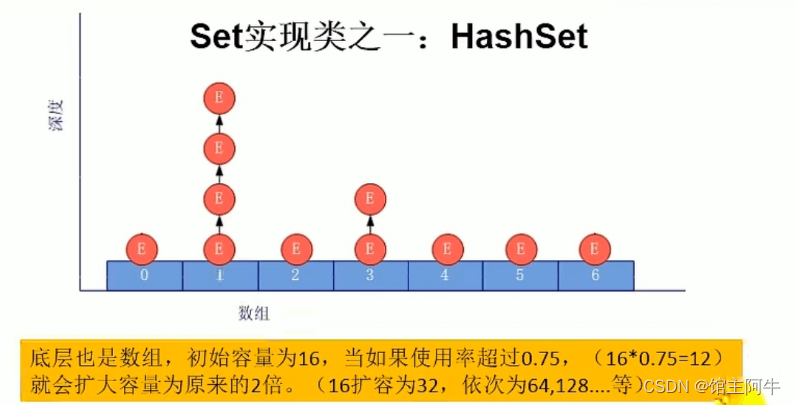
这也就是上面不可重复性里写到的,对于自定义类实现的对象,一定要重写hashcode和equals方法才能保证判断他们是否相等。
这里源码就不分析了,因为 HashSet的底层是HashMap,我们后面会总结HashMap的源码分析!
LinkedHashSet
是HashSet的子类,遍历其内部数据时,可以按照添加的顺序遍历!
public static void main(String[] args) {
Set set = new LinkedHashSet();
set.add("aniu");
set.add(666);
set.add("yyds");
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
LinkedHashSet为什么可以按照添加的元素顺序来遍历呢,看下面这张图就行了:

LinkedHashSet在原有HashSet的基础上提供了双向链表,保证了便历时的顺序输出!
对于频繁的便利操作,LinkedHashSet的效率高于HashSet!
TreeSet
可以按照添加的元素的指定属性进行排序,因此,他要求添加的元素是同一数据类型!
public class Demo {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(3);
set.add(21);
set.add(15);
set.add(6);
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
对于自定义类的对象,就需要我们前面总结的自然排序和定制排序了,这里不再写案例!
那再看看TreeSet的存储结构:
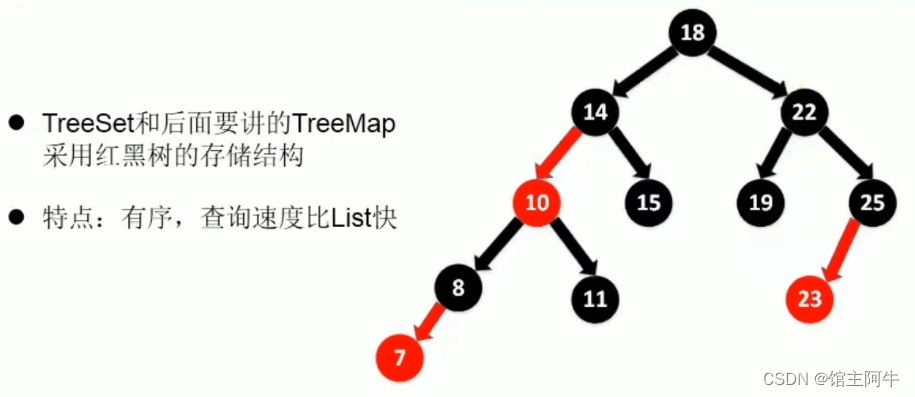
以上就是Java Set接口及常用实现类总结的详细内容,更多关于Java Set接口的资料请关注我们其它相关文章!
相关推荐
-
java中List接口与实现类介绍
目录 List接口介绍-ArrayList ArrayList源码结论 ArrayList源码分析 总结 List接口介绍-ArrayList 有序.可重复 线程不安全,因为没有synchronized修饰 ArrayList源码结论 ArrayList中维护了一个Object类型的数组elementData. transient Object[] elementData; // transient 表示该属性不会被序列化 当创建ArrayList对象时,如果使用的是无参构造器,则初始eleme
-
Java SpringBoot 获取接口实现类汇总
目录 前言 一.获取接口的所有实现类 1.枚举 2.业务接口 2.1 实现类 3.ApplicationContextAware接口实现类 4.获取到所有实现类使用 前言 有时候,根据业务逻辑的需求,需要获取到某个接口的所有实现类,然后根据业务类型来执行不同的实现类方法.有点类似策略模式. 如果没有用到 Spring的话,可以使用 ServiceLoaderl类JDK自带的一个类加载器(其他框架的SPI机制也是可以实现). ServiceLoader<MyInterface> loader =
-
Java中的List接口实现类解析
目录 Java的List接口实现类 实现类ArrayList 实现类LinkedList 实现类Vector List三个实现类 Java的List接口实现类 实现类ArrayList ArrayList类相当于一个容量可变的动态数组,当超过了他的大小时,类集自动增加,当对象被删除后,数组就可以缩小. import java.util.*; public class ListDemo { public static void main(String args[]){ Collection c1
-
Java集合之Map接口与实现类详解
目录 初识Map Map中常用方法 HashMap LinkedHashMap TreeMap HashMap和TreeMap的比较 Hashtable 集合中元素的遍历 iterator接口中的方法 Enumeration接口中的方法 初识Map Map接口没有从Collection接口继承,Map接口用于维护“键-值”对数据,这个“键-值”对就是Map中的元素,Map提供“键(Key)”到“值(value)”的映射,一个Map中键值必须是唯一的,不能有重复的键,因为Map中的“键-值”对元素
-

java集合collection接口与子接口及实现类
目录 概要 1 Collection接口的实现子类特性 2 通过实现子类ArrayList体现Collection接口方法 2.1 代码演示示例 3 集合的遍历:①使用Iterator(迭代器)②增强for循环遍历 3.1 代码示例 4 List相关解读 5 Set接口分析 Map接口及实现子类 结语 概要 集合概念:像数组一样是java的一个容器:和数组不同的是数组只能存同类型的数据,且长度定义之后就不可变,集合不仅,可以存多种类型的数据,而且还提供了增.删.改.查的方法: 集合分类:可以分为
-
Java如何获取接口所有的实现类
目录 Java获取接口所有的实现类 反射获取接口的所有实现类 总结 Java获取接口所有的实现类 最近因业务需求,要实现NodeRed服务后端化,为使各个节点的解析进行插件化(NodeRed各个节点也是插件化,安装插件即可使用) ,后端不得不动态加载解析NodeRed节点json,用一个接口来统一管理. import cn.hutool.core.util.ClassUtil; import java.util.*; /** * 此类用来解析NodeRed服务器的json串 */ public
-
浅谈java的接口和C++虚类的相同和不同之处
C++虚类相当于java中的抽象类,与接口的不同之处是: 1.一个子类只能继承一个抽象类(虚类),但能实现多个接口 2.一个抽象类可以有构造方法,接口没有构造方法 3.一个抽象类中的方法不一定是抽象方法,即其中的方法可以有实现(有方法体),接口中的方法都是抽象方法,不能有方法体,只有声明 4.一个抽象类可以是public.private.protected.default,接口只有public 5.一个抽象类中的方法可以是public.private.protected.default,接口中的
-
java自定义封装StringUtils常用工具类
自定义封装StringUtils常用工具类,供大家参考,具体内容如下 package com.demo.utils; import java.util.ArrayList; import java.util.List; import java.util.Map; /** * 字符串操作工具类 * @author dongyangyang * @Date 2016/12/28 23:12 * @Version 1.0 * */ public class StringUtils { /** * 首字
-
Java程序连接数据库的常用的类和接口介绍
编写访问数据库的Java程序还需要几个重要的类和接口. DriverManager类 DriverManager类处理驱动程序的加载和建立新数据库连接.DriverManager是java.sql包中用于管理数据库驱动程序的类.通常,应用程序只使用类DriverManager的getConnection()静态方法,用来建立与数据库的连接,返回Connection对象: static Connection getConnection(String url,String username,Stri
-
java处理字节的常用工具类
处理字节的常用工具类方法,供大家参考,具体内容如下 package com.demo.utils; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.IOException; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; import java.nio.charset.Char
-
Java线程安全的常用类_动力节点Java学院整理
线程安全类 在集合框架中,有些类是线程安全的,这些都是jdk1.1中的出现的.在jdk1.2之后,就出现许许多多非线程安全的类. 下面是这些线程安全的同步的类: vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用.在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的. statck:堆栈类,先进后出 hashtable:就比hashmap多了个线程安全 除了这些之外,其他的集合大都是非线程安全的类和接口. 线程安全的类其方法是同步
-
详解Java常用工具类—泛型
一.泛型概述 1.背景 在Java中增加泛型之前,泛型程序设计使用继承来实现的. 坏处: 需要进行强制类型转换 可向集合中添加任意类型的对象,存在风险 2.泛型的使用 List<String> list=new ArrayList<String>(); 3.多态与泛型 class Animal{} class Cat extends Animal{} List<Animal> list=new ArrayList<Cat>(); //这是不允许的,变量声明的
-
Java常用工具类总结
一.线程协作.控制并发流程的工具类 什么是控制并发流程? 控制并发流程的工具类,作用就是帮助我们程序员更容易得让线程之间合作让线程之间相互配合,来满足业务逻辑比如让线程A等待线程B执行完毕后再执行等合作策略 二.CountDownLatch倒计时门闩 倒数门: 例子:购物拼团:大巴,人满才会发车 流程:倒数结束之前,一直处于等待状态,直到倒计时结束,此线程才继续工作. 开始 -> 进入等待 -> 倒数结束 -> 继续工作 类的主要方法介绍: CountDownLatch(int cou
-
Java常用API类之Math System tostring用法详解
1.注意(类名不能与math重名,否则可能报错误) 1.math:可以直接拿来用的接口类 Math.abs(-90);返回参数的绝对值 Math.max(60,98)返回参数的最大值 Math.random()*100随机函数:随机输出一个数 等等 public static void main(String[] args){ int a = 1300, b = 1000; System.out.println(Math.abs(-90)); System.out.println(Math.ma
-
Java JDK内置常用接口和深浅拷贝
目录 前言 一.comparable接口 二.Cloneable接口 三.深浅拷贝 1.浅拷贝 2.深拷贝 前言 在Java中,我们使用接口优先原则,当一个场景可以使用抽象类也可以使用接口定义时,优先考虑使用接口,因为接口更灵活,使用抽象类必须满足is a 的继承树关系,而且是单继承,接口相比于抽象类更加的灵活,本篇我们就一起看看JDK中的常用内置接口. 一.comparable接口 java.lang.Comperable: 当一个类实现了Comperable接口,就表示该类具备了可比较的能力
-
Java调用第三方http接口的常用方式总结
目录 1.概述 在Java项目中调用第三方接口的常用方式有 2.Java调用第三方http接口的方式 2.1 通过JDK网络类Java.net.HttpURLConnection 2.2 通过apache common封装好的HttpClient 2.3 通过Apache封装好的CloseableHttpClient 2.4 通过OkHttp 2.5 通过Spring的RestTemplate 2.6通过hutool的HttpUtil 3.总结 1.概述 在实际开发过程中,我们经常需要调用对方提