深度解密Go语言中字符串的使用
目录
- Go 字符串实现原理
- 字符串的截取
- 字符串和切片的转换
- 字符串和切片共享底层数组
- 什么是万能指针
- 字符串和其它数据结构的转化
- 整数和字符串相互转换
- Parse 系列函数
- Format 系列函数
- 小结
Go 字符串实现原理
Go 的字符串有个特性,不管长度是多少,大小都是固定的 16 字节。
package main
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(
unsafe.Sizeof("komeiji satori"),
) // 16
fmt.Println(
unsafe.Sizeof("satori"),
) // 16
}
显然用鼻子也能猜到原因,Go 的字符串底层并没有实际保存这些字符,而是保存了一个指针,该指针指向的内存区域负责存储具体的字符。由于指针的大小是固定的,所以不管字符串多长,大小都是相等的。
另外字符串大小是 16 字节,指针是 8 字节,那么剩下的 8 字节是什么呢?不用想,显然是长度。下面来验证一下我们结论:
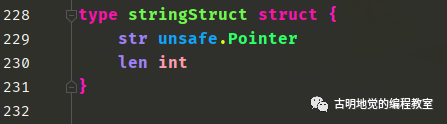
以上是 Go 字符串的底层结构,位于 runtime/string.go 中。字符串在底层是一个结构体,包含两个字段,其中 str 是一个 8 字节的万能指针,指向一个数组,数组里面存储的就是实际的字符;而 len 则表示长度,也是 8 字节。
因此结构很清晰了:
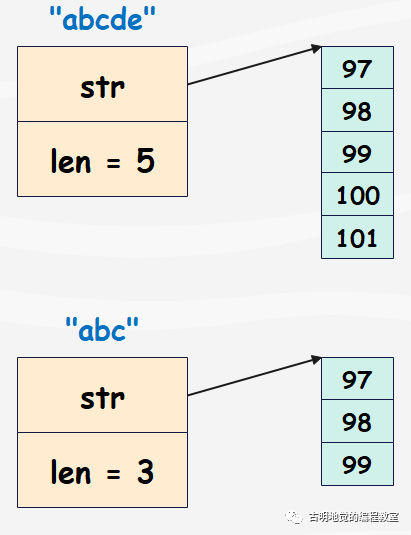
str 指向的数组里面存储的就是所有的字符,并且类型是 uint8,因为 Go 的字符串默认采用 utf-8 编码。所以一个汉字在 Go 里面占 3 字节,我们先用 Python 举个例子:
>>> name = "琪露诺"
>>> [c for c in name.encode("utf-8")]
[231, 144, 170, 233, 156, 178, 232, 175, 186]
>>>
那么对于 Go 而言,底层就是这么存储的:
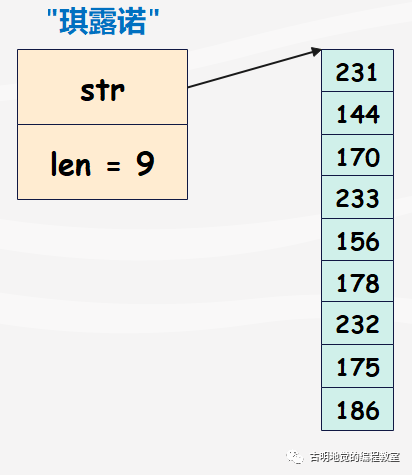
我们验证一下:
package main
import "fmt"
func main() {
name := "琪露诺"
// 长度是 9,不是 3
fmt.Println(len(name)) // 9
// 查看底层数组存储的值
// 可以转成切片查看
fmt.Println(
[]byte(name),
) // [231 144 170 233 156 178 232 175 186]
}
结果和我们想的一样,并且内置函数 len 在统计字符串长度时,计算的是底层数组的长度。
字符串的截取
如果要截取字符串的某个子串,要怎么做呢?如果是 Python 的话很简单:
>>> name = "琪露诺" >>> name[0] '琪' >>> name[: 2] '琪露' >>>
因为 Python 字符串里面的每个字符的大小都是相同的,可能是 1 字节、2字节、4字节。但不管是哪种,一个字符串里面的所有字符都具有相同的大小,因此才能通过索引准确定位。
但在 Go 里面这种做法行不通,Go 的字符串采用 utf-8 编码,不同字符占用的大小不同,ASCII 字符占 1 字节,汉字占 3 字节,所以无法通过索引准确定位。
package main
import "fmt"
func main() {
name := "琪露诺"
fmt.Println(
name[0], name[1], name[2],
) // 231 144 170
fmt.Println(name[: 3]) // 琪
}
如果一个字符串里面既有英文又有中文,那么想通过索引准确定位是不可能的。因此这个时候我们需要进行转换,让它像 Python 一样,每个字符都具有相同的大小。
package main
import "fmt"
func main() {
name := "琪露诺"
// rune 等价于 int32
// 此时每个元素统一占 4 字节
// 并且 []rune(name) 的长度才是字符串的字符个数
fmt.Println(
[]rune(name),
) // [29738 38706 35834]
// 然后再进行截取
fmt.Println(
string([]rune(name)[0]),
string([]rune(name)[: 2]),
) // 琪 琪露
}
所以对于字符串 "憨pi" 而言,如果是 utf-8 存储,那么只需要 5 个字节。但很明显,基于索引查找指定的字符是不可能的,除非事先知道字符串长什么样子。如果是转成 []rune 的话,那么需要 12 字节存储,内存占用变大了,但可以很方便地查找某个字符或者某个子串。
字符串和切片的转换
字符串和切片之间是可以互转的,但切片只能是 uint8 或者 int32 类型,另外 uint8 也可以写成 byte,int32 可以写成 rune。
由于 byte 是 1 字节,那么当字符串包含汉字,转成 []byte 切片时,一个汉字需要 3 个byte 表示。因此字符串 "憨pi" 转成 []byte 之后,长度为 5。
而 rune 是 4 字节,可以容纳所有的字符,那么转成 []rune 切片时,不管什么字符,都只需要一个 rune 表示即可。所以字符串 "憨pi" 转成 []rune 之后,长度为 3。
因此当你想统计字符串的字符个数时,最好转成 []rune 数组之后再统计。如果是字节个数,那么直接使用内置函数 len 即可。
我们举例说明,先来看一段 Python 代码:
>>> s = "憨pi"
# 采用utf-8编码(等价于Go的[]byte数组)
# "憨" 需要 230 134 168 三个整数来表示
# 而 "p" 和 "i" 均只需 1 个字节,分别为112和105
>>> [c for c in s.encode("utf-8")]
[230, 134, 168, 112, 105]
# 采用 unicode 编码(类似于Go的[]rune数组)
# 所有字符都只需要1个整数表示
# 但对于ASCII字符而言,不管什么编码,对应的数值不变
>>> [ord(c) for c in s]
[25000, 112, 105]
我们用 Go 再演示一下:
package main
import "fmt"
func main() {
s := "憨pi"
fmt.Println(
[]byte(s),
) // [230 134 168 112 105]
fmt.Println(
[]rune(s),
) // [25000 112 105]
}
结果是一样的,当然这个过程我们也可以反向进行:
package main
import "fmt"
func main() {
s1 := []byte{230, 134, 168, 112, 105}
fmt.Println(string(s1)) // 憨pi
s2 := []rune{25000, 112, 105}
fmt.Println(string(s2)) // 憨pi
}
结果没有任何问题。
字符串和切片共享底层数组
我们知道字符串和切片内部都有一个指针,指针指向一个数组,该数组存放具体的元素。
// runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
// runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
假设有一个字符串 "abc",然后基于该字符串创建一个切片,那么两者的结构如下:
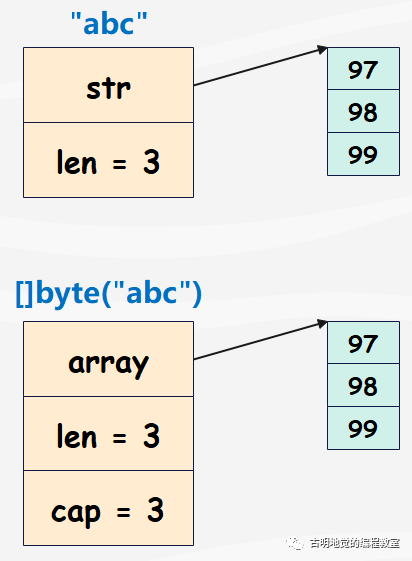
字符串在转成切片的时候,会将底层数组也拷贝一份。那么问题来了,在基于字符串创建切片的时候,能不能不拷贝数组呢?也就是下面这个样子:
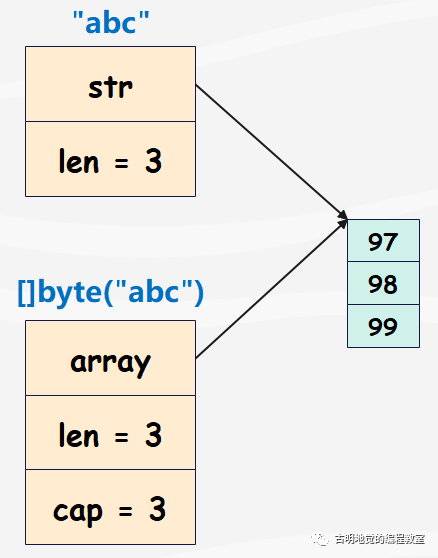
如果字符串比较大,或者说需要和切片之间来回转换的话,这种方式无疑会减少大量开销。Go 提供了万能指针帮我们实现这一点,所以先来了解一下什么是万能指针。
什么是万能指针
我们知道 C 的指针不仅可以相互转换,而且还可以参与运算,但 Go 不行,因为 Go 的指针是类型安全的。Go 编译器对类型的检测非常严格,让你在享受指针带来的便利时,又给指针施加了很多制约来保证安全。因此 Go 的指针不可以相互转换,也不可以参与运算。
但保证安全是需要以牺牲效率为代价的,如果你能保证写出的程序就是安全的,那么可以使用 Go 中的万能指针,从而绕过类型系统的检测,让程序运行的更快。
万能指针在 Go 里面叫做 unsafe.Pointer,它位于 unsafe 包下面。当然这个包名看起来有点怪怪的,因为这个包可以让我们绕过 Go 类型系统的检测,直接访问内存,从而提升效率。所以它有点危险,而 Go 官方也不推荐开发者使用,于是起了这个名字。
但实际上 unsafe 包在底层被大量使用,所以不要被名字误导了,这个包是一定要掌握的。
回到万能指针上面来,Go 的指针不可以相互转换,但是它们都可以和万能指针转换。举个例子:
package main
import (
"fmt"
"unsafe"
)
func main() {
// 一个 []int8 类型的切片
s1 := []int8{1, 2, 3, 4}
// 如果直接转成 []int16 是会报错的
// 因为 Go 的类型系统不允许这么做
// 但是有万能指针,任何指针都可以和它转换
// 我们可以先将 s1 的指针转成万能指针
// 然后再将万能指针转成 *[]int16,最后再解引用
s2 := *(*[]int16)(unsafe.Pointer(&s1))
// 那么问题来了,指针虽然转换了
// 但是内存地址没变,内存里的值也没变
// 由于 s2 是 []int16 类型,s1 是 []int8 类型
// 所以它会把 s1[0] 和 s1[1] 整体作为 s2[0]
// 会把 s1[2] 和 s1[3] 整体作为 s2[1]
fmt.Println(s2) // [513 1027 0 0]
// int8 类型的 1 和 2 组合成 int16
// int8 类型的 3 和 4 组合成 int16
fmt.Println(2 << 8 + 1) // 513
fmt.Println(4 << 8 + 3) // 1027
}
因此把 Go 的万能指针想象成 C 的空指针 void * 即可。
那么让字符串和切片共享数组,我们就可以这么做:
package main
import (
"fmt"
"unsafe"
)
func main() {
str := "abc"
slice := *(*[]byte)(unsafe.Pointer(&str))
fmt.Println(slice) // [97 98 99]
fmt.Println(cap(slice)) // 10036576
}
虽然转换成功了,但是还有点问题,容量不太对劲。至于原因也很简单,字符串和切片在底层都是结构体,并且它们的前两个字段相同,所以转换之后打印没有问题。但字符串没有容量的概念,它是定长的,所以转成切片的时候 cap 就丢失了,打印的就是乱七八糟的值。
所以我们需要再完善一下:
package main
import (
"fmt"
"unsafe"
)
func StringToBytes(s string) []byte {
// 既然字符串转切片,会丢失容量
// 那么加上去就好了,做法也很简单
// 新建一个结构体,将容量(等于长度)加进去
return *(*[]byte)(unsafe.Pointer(
&struct {
string
Cap int
}{s, len(s)},
))
}
func BytesToString(b []byte) string {
// 切片转字符串就简单了,直接转即可
// 转的过程中,切片的 Cap 字段会丢弃
return *(*string)(unsafe.Pointer(&b))
}
func main() {
fmt.Println(
StringToBytes("abc"),
) // [97 98 99]
fmt.Println(
BytesToString([]byte{97, 98, 99}),
) // abc
}
结果没有问题,但我们怎么证明它们是共享数组的呢?很简单:
package main
import (
"fmt"
"unsafe"
)
func main() {
slice := []byte{97, 98, 99}
str := *(*string)(unsafe.Pointer(&slice))
fmt.Println(str) // abc
slice[0] = 'A'
fmt.Println(str) // Abc
}
操作切片等于操作底层数组,而 str 前后的打印结果不一致,所以确实是共享同一个数组。但需要注意的是,这里是先创建的切片,因此底层数组是可以修改的,没有问题。
但如果创建的是字符串,然后基于字符串得到切片,那么切片就不可以修改了。因为字符串是不可修改的,所以底层数组也不可修改,也意味着切片不可以修改。
字符串和其它数据结构的转化
以上我们就介绍完了字符串的原理,再来看看工作中一些常见的字符串操作。
整数和字符串相互转换
如果想把一个整数转成字符串,那么该怎做呢?比如将 97 转成字符串。有过 Python 经验的,应该下意识会想到 string(97),但这是不行的,它返回的是字符串 "a",因为 97 对应的字符是 'a'。
如果将整数转成字符串,应该使用 strconv 包下的 Itoa 函数,这个和 C 语言类似。
package main
import (
"fmt"
"strconv"
)
func main() {
fmt.Println(strconv.Itoa(97))
fmt.Println(strconv.Itoa(97) == "97")
/*
97
true
*/
// 同理,将字符串转成整数则是 Atoi
s := "97"
if num, err := strconv.Atoi(s); err != nil {
fmt.Println(err)
} else {
fmt.Println(num == 97) // true
}
s = "97xx"
if num, err := strconv.Atoi(s); err != nil {
fmt.Println(
err,
) // strconv.Atoi: parsing "97xx": invalid syntax
} else {
fmt.Println(num)
}
}
Atoi 和 Itoa 专门用于整数和字符串之间的转换,strconv 这个包还提供了 Format 系列和 Parse 系列的函数,用于其它数据结构和字符串之间的转换,当然里面也包括整数。
Parse 系列函数
Parse 一类函数用于转换字符串为给定类型的值。
ParseBool
将指定字符串转换为对应的bool类型,只接受 1、0、t、f、T、F、true、false、True、False、TRUE、FALSE,否则返回错误;
package main
import (
"fmt"
"strconv"
)
func main() {
//因为字符串转换时可能发生失败,因此都会带一个error
//而这里解析成功了,所以 error 是 nil
fmt.Println(strconv.ParseBool("1")) // true <nil>
fmt.Println(strconv.ParseBool("F")) // false <nil>
}
ParseInt
函数原型:func ParseInt(s string, base int, bitSize int) (i int64, err error)
- s:转成 int 的字符串;
- base:指定进制(2 到 36),如果 base 为 0,那么会从字符串的前缀来判断,如 0x 表示 16 进制等等,如果前缀也没有那么默认是 10 进制;
- bistSize:整数类型,0、8、16、32、64 分别代表 int、int8、int16、int32、int64;
返回的 err 是 *NumErr 类型,如果语法有误,err.Error = ErrSyntax;如果结果超出范围,err.Error = ErrRange。
package main
import (
"fmt"
"strconv"
)
func main() {
fmt.Println(
strconv.ParseInt("0x16", 0, 0),
) // 22 <nil>
fmt.Println(
strconv.ParseInt("16", 16, 0),
) // 22 <nil>
fmt.Println(
strconv.ParseInt("16", 0, 0),
) // 16 <nil>
fmt.Println(
strconv.ParseInt("016", 0, 0),
) // 14 <nil>
//进制为 2,但是字符串出现了 6,无法解析
fmt.Println(
strconv.ParseInt("16", 2, 0),
) // 0 strconv.ParseInt: parsing "16": invalid syntax
//只指定 8 位,显然存不下
fmt.Println(
strconv.ParseInt("257", 0, 8),
) // 127 strconv.ParseInt: parsing "257": value out of range
//还可以指定正负号
fmt.Println(
strconv.ParseInt("-0x16", 0, 0),
) // -22 <nil>
fmt.Println(
strconv.ParseInt("-016", 0, 0),
) // -14 <nil>
}
ParseUint
ParseUint 类似 ParseInt,但不接受正负号,用于无符号整型。
ParseFloat
函数原型:func ParseFloat(s string, bitSize int) (f float64, err error),其中 bitSize为:32、64,表示对应精度的 float
package main
import (
"fmt"
"strconv"
)
func main() {
fmt.Println(
strconv.ParseFloat("3.14", 64),
) //3.14 <nil>
}
Format 系列函数
Format 系列函数就比较简单了,就是将指定类型的数据格式化成字符串,Parse 则是将字符串解析成指定数据类型,这两个是相反的。另外转成字符串的话,则不需要担心 error 了。
FormatBool
package main
import (
"fmt"
"strconv"
)
func main() {
// 如果是 Parse 系列的话会返回两个值, 因为可能会出错
// 所以多一个 error, 因此需要两个变量来接收
// 而 Format 系列则无需担心, 因为转成字符串是不会出错的
// 所以只返回一个值, 接收的时候只需要一个变量即可
fmt.Println(
strconv.FormatBool(true),
) //true
fmt.Println(
strconv.FormatBool(false) == "false",
) //true
}
FormatInt
传入字符串和指定的进制。
package main
import (
"fmt"
"strconv"
)
func main() {
// 数值是 24,但它是 16 进制的
// 所以对应成 10 进制是 18
fmt.Println(
strconv.FormatInt(24, 16),
) // 18
}
FormatUint
是 FormatInt 的无符号版本,两者差别不大。
FormatFloat
函数原型:func FormatFloat(f float64, fmt byte, prec, bitSize int) string,作用是将浮点数转成为字符串并返回。
- f:浮点数;
- fmt:表示格式,'f'(-ddd.dddd)、'b'(-ddddp±ddd,指数为二进制)、'e'(-d.dddde±dd,十进制指数)、'E'(-d.ddddE±dd,十进制指数)、'g'(指数很大时用'e'格式,否则'f'格式)、'G'(指数很大时用'E'格式,否则'f'格式);
- prec:prec 控制精度(排除指数部分),当 fmt 为 'f'、'e'、'E',它表示小数点后的数字个数;为 'g'、'G',它表示总的数字个数。如果 prec 为 -1,则代表使用最少数量的、但又必需的数字来表示 f;
- bitSize:f 是哪一种精度的 float,32 或者 64;
package main
import (
"fmt"
"strconv"
)
func main() {
fmt.Println(
strconv.FormatFloat(3.1415, 'f', -1, 64))
fmt.Println(
strconv.FormatFloat(3.1415, 'e', -1, 64))
fmt.Println(
strconv.FormatFloat(3.1415, 'E', -1, 64))
fmt.Println(
strconv.FormatFloat(3.1415, 'g', -1, 64))
/*
3.1415
3.1415e+00
3.1415E+00
3.1415
*/
}
小结
- 字符串底层是一个结构体,内部不存储实际数据,而是只保存一个指针和一个长度;
- 字符串采用 utf-8 编码,这种编码的特点是省内存,但是无法通过索引准确定位字符和截取子串;
- 字符串可以和 []byte、[]rune 类型的切片互相转换,特别是 []rune,如果想计算字符长度或者截取子串,需要转成 []rune;
- 字符串和切片之间可以共享底层数组,其实现的核心就在于万能指针;
以上就是深度解密Go语言中字符串的使用的详细内容,更多关于Go语言 字符串的资料请关注我们其它相关文章!
相关推荐
-
浅谈Go语言中字符串和数组
go语言里边的字符串处理和PHP还有java 的处理是不一样的,首先申明字符串和修改字符串 复制代码 代码如下: package main import "fmt" var name string //申明一个字符串 var emptyname string = "" //申明一个空字符串 func main() { //申明多个字符串并且赋值 a, b, v := "hello", "word", &
-

Go语言字符串常见操作的使用汇总
目录 1. 字节数组 2. 头尾处理 3. 位置索引 4. 替换 5. 统计次数 6. 重复 7. 大小写 8. 去除字符 9. 字符串切片处理 10. 数值处理 1. 字节数组 字节与字符的区别 字节(Byte) 是计量单位,表示数据量多少,是计算机信息技术用于计量存储容量的一种计量单位,通常情况下一字节等于八位 字符(Character) 是计算机中使用的字母.数字.字和符号,比如'A'.'B'.'$'.'&'等 一般在英文状态下一个字母或字符占用一个字节,一个汉字用两个字节表示 通俗点来说
-
深入理解 Go 中的字符串
目录 字符串的本质 字符串的底层原理 字符串的本质 在编程语言中,字符串发挥着重要的角色.字符串背后的数据结构一般有两种类型: 一种在编译时指定长度,不能修改 一种具有动态的长度,可以修改. 比如:与Python 中的字符串一样,Go 语言中的字符串不能被修改,只能被访问.在 Python 中,如果改变一个字符串的值会得到如下结果: >>> hi = "Hello" >>> hi 'Hello' >>> hi[0] = 'h' Tr
-
Go语言常用字符串处理方法实例汇总
本文实例汇总了Go语言常用字符串处理方法.分享给大家供大家参考.具体如下: 复制代码 代码如下: package main import ( "fmt" "strings" //"unicode/utf8" ) func main() { fmt.Println("查找子串是否在指定的字符串中") fmt.Println(" Contains 函数的用法")
-
Golang字符串常用函数的使用
目录 1)Golang字符串包含功能[区分大小写] 2)Golang ContainsAny()[区分大小写] 3)Golang Count() [区分大小写] 4)Golang EqualFold() [不区分大小写] 5) Golang Fields() 6)Golang FieldsFunc() 7)Golang HasPrefix() 8)Golang HasSuffix() 9)Golang Index() 10)Golang IndexAny() 11)Golang IndexByt
-
深度解密Go语言中字符串的使用
目录 Go 字符串实现原理 字符串的截取 字符串和切片的转换 字符串和切片共享底层数组 什么是万能指针 字符串和其它数据结构的转化 整数和字符串相互转换 Parse 系列函数 Format 系列函数 小结 Go 字符串实现原理 Go 的字符串有个特性,不管长度是多少,大小都是固定的 16 字节. package main import ( "fmt" "unsafe" ) func main() { fmt.Println(
-
深度解密 Go 语言中的 sync.map
工作中,经常会碰到并发读写 map 而造成 panic 的情况,为什么在并发读写的时候,会 panic 呢?因为在并发读写的情况下,map 里的数据会被写乱,之后就是 Garbage in, garbage out,还不如直接 panic 了. 是什么 Go 语言原生 map 并不是线程安全的,对它进行并发读写操作的时候,需要加锁.而 sync.map 则是一种并发安全的 map,在 Go 1.9 引入. sync.map 是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度. sync.
-
深度解密 Go 语言中的 sync.Pool
最近在工作中碰到了 GC 的问题:项目中大量重复地创建许多对象,造成 GC 的工作量巨大,CPU 频繁掉底.准备使用 sync.Pool 来缓存对象,减轻 GC 的消耗.为了用起来更顺畅,我特地研究了一番,形成此文.本文从使用到源码解析,循序渐进,一一道来. 是什么 sync.Pool 是 sync 包下的一个组件,可以作为保存临时取还对象的一个"池子".个人觉得它的名字有一定的误导性,因为 Pool 里装的对象可以被无通知地被回收,可能 sync.Cache 是一个更合适的名字. 有
-
c语言中字符串分割函数及实现方法
1.问题引入 自己在写一个linux下的模拟执行指令的时候,遇到了输入"cat a.c",要将该字符串分解成cat和a.c两个单独的字符串,虽然知道有strtok的存在,但是想自己尝试写一下,于是就自己写了一个,不过总是遇到这样或那样的问题,虽然最后调通了,不过确浪费了不少时间:后来作业交上去以后又仔细阅读了strtok函数,发现原来linux下已经改成strsep,所有在这里就写一下自己所走的过程. 2.自己写的字符串分割函数:用于分割指令,比如cat a.c最后会被分割成cat和a
-
C语言中字符串实现正序与逆序实例详解
C语言中字符串实现逆序实例详解 字符串逆序和正序的实现代码: #include <stdio.h> #include <stdlib.h> #include <conio.h> #include <malloc.h> #include <string.h> /*定义*/ typedef struct node { char c; struct node *llink,*rlink; }stud; /*建立链表*/ stud * creat(voi
-
R语言中字符串的拼接操作实例讲解
在R语言中 paste 是一个很有用的字符串处理函数,可以连接不同类型的变量及常量. 函数paste的一般使用格式为: paste(..., sep = " ", collapse = NULL) 其 中-表示一个或多个R可以被转化为字符型的对象:参数sep表示分隔符,默认为空格:参数collapse可选,如果不指定值,那么函数paste的返回值是自变量之间通过sep指定的分隔符连接后得到的一个字符型向量:如果为其指定了特定的值,那么自变量连接后的字符型向量会再被连接成一个字符串,之间
-
C语言中字符串与各数值类型之间的转换方法
C语言的算法设计中,经常会需要用到字符串,而由于c语言中字符串并不是一个默认类型,其标准库stdlib设计了很多函数方便我们处理字符串与其他数值类型之间的转换. 首先放上一段展示各函数使用的代码,大家也可以copy到自己的机器上运行观察 #include <stdio.h> #include <stdlib.h> int main(int argc, char *argv[]) { int num=183; char str[3]; //itoa函数将整型转换为字符串数值类型 it
-
深度解析C语言中的变量作用域、链接和存储期的含义
在c中变量有三种性质: 1.存储期限:变量的存储期限决定了变量占用的内存空间什么时候会被释放,具有动态存储期限的变量会在所属的程序块被执行时获得内存空间,在结束时释放内存空间.具有静态存储期限的变量在程序运行的整个期间都会占用内存空间. 2.作用域:变量有块作用域也有文件作用域,结合序章第一张图可以明白块作用域是在某些程序块内起作用,文件作用域是在整个c文件之内起作用. 3.链接:链接是各个文件之间的关系,具有内部链接的变量只在本文件内起作用,具有外部链接的变量可以在不同文件内起作用.具有无链接
-
c语言中字符串与字符串数组详解
目录 字符串 字符串输出 输入字符串 字符串常用方法 字符串数组 总结 字符串 用双引号引起来的就是字符串,字符串由字符组成 字符串使用%s格式化输出 字符串以\0结尾,没有\0就不是字符串 只要是用双引号括起来的都是字符串 字符串的本质就是数组 注意: 字符串变量和普通的字符数组有一定的区别,C语言规定,字符串必须以\0结尾(作为字符串的结束符号),所以字符串变量的元素个数比字符数组的元素多一个\0 #include <stdio.h> int main(int argc, const ch
-
深度解析C语言中数据的存储
目录 前言 数据类型介绍 类型的基本归类 整型家族 浮点数家族 构造类型 指针类型 空类型 前言 在VS编译器里有release和debug两种形式,debug包含调试信息,release不包含调试信息,并会对程序进行优化 int main() { int i = 0; int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; for (i = 0; i <= 12; i++) { arr[i] = 0; printf("hehe\n"); } return