在pytorch中如何查看模型model参数parameters
目录
- pytorch查看模型model参数parameters
- pytorch查看模型参数总结
- 1:DNN_printer
- 2:parameters
- 3:get_model_complexity_info()
- 4:torchstat
pytorch查看模型model参数parameters
示例1:pytorch自带的faster r-cnn模型
import torch
import torchvision
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
for name, p in model.named_parameters():
print(name)
print(p.requires_grad)
print(...)
#或者
for p in model.parameters():
print(p)
print(...)
示例2:自定义网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512]
self.features = self._vgg_layers(cfg)
def _vgg_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x ,kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)
]
in_channels = x
return nn.Sequential(*layers)
def forward(self, data):
out_map = self.features(data)
return out_map
Model = Net()
for name, p in model.named_parameters():
print(name)
print(p.requires_grad)
print(...)
#或者
for p in model.parameters():
print(p)
print(...)
在自定义网络中,model.parameters()方法继承自nn.Module
pytorch查看模型参数总结
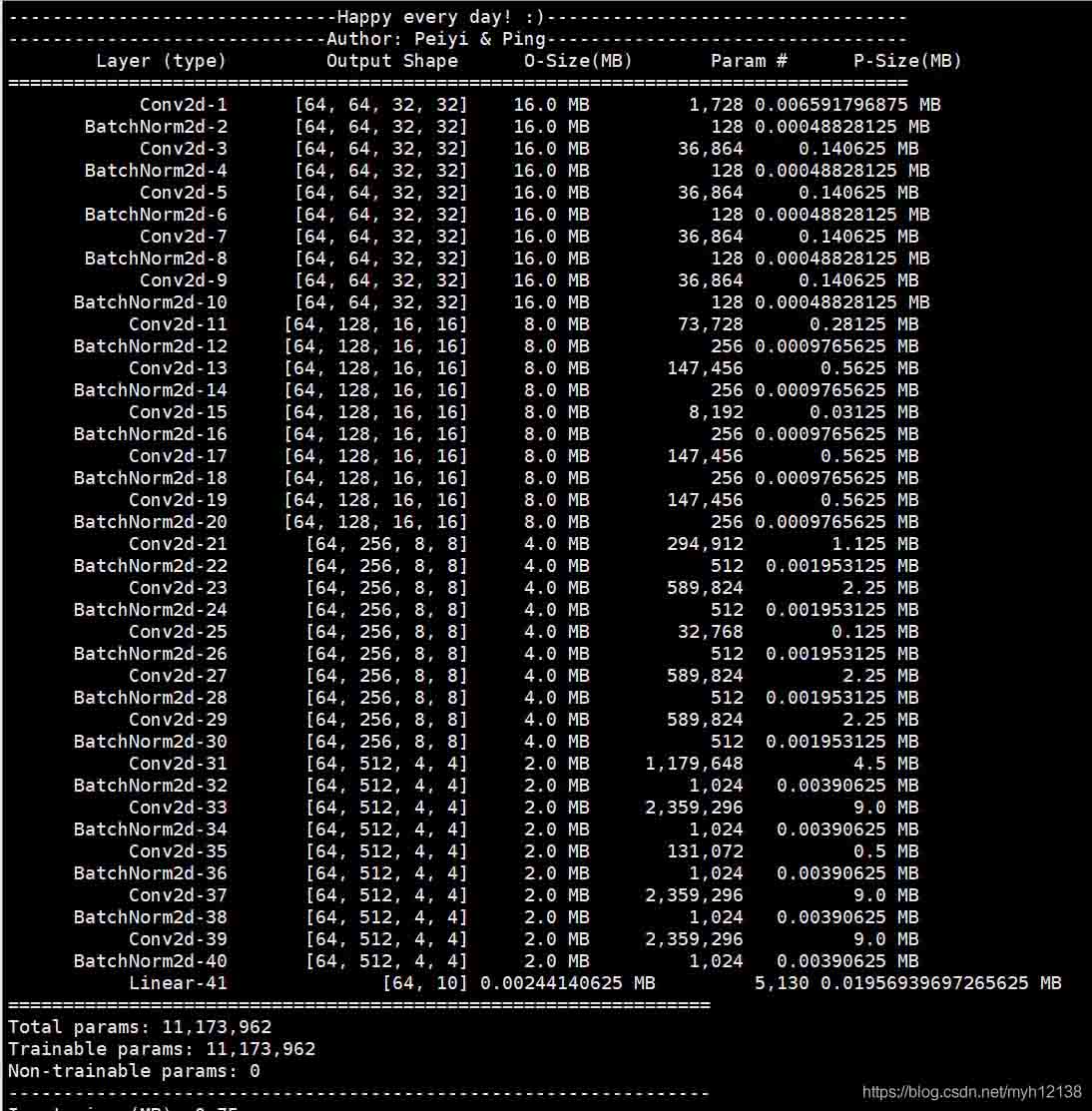
1:DNN_printer
其中(3, 32, 32)是输入的大小,其他方法中的参数同理
from DNN_printer import DNN_printer
batch_size = 512
def train(epoch):
print('\nEpoch: %d' % epoch)
net.train()
train_loss = 0
correct = 0
total = 0
// put the code here and you can get the result
DNN_printer(net, (3, 32, 32),batch_size)
结果
2:parameters
def cnn_paras_count(net):
"""cnn参数量统计, 使用方式cnn_paras_count(net)"""
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in net.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(p.numel() for p in net.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
return total_params, total_trainable_params
cnn_paras_count(net)
直接输出参数量,然后自己计算
需要注意的是,一般模型中参数是以float32保存的,也就是一个参数由4个bytes表示,那么就可以将参数量转化为存储大小。
例如:
- 44426个参数*4 / 1024 ≈ 174KB
3:get_model_complexity_info()
from ptflops import get_model_complexity_info from torchvision import models net = models.mobilenet_v2() ops, params = get_model_complexity_info(net, (3, 224, 224), as_strings=True, print_per_layer_stat=True, verbose=True)

4:torchstat
from torchstat import stat import torchvision.models as models model = models.resnet152() stat(model, (3, 224, 224))
输出

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch 实现打印模型的参数值
对于简单的网络 例如全连接层Linear 可以使用以下方法打印linear层: fc = nn.Linear(3, 5) params = list(fc.named_parameters()) print(params.__len__()) print(params[0]) print(params[1]) 输出如下: 由于Linear默认是偏置bias的,所有参数列表的长度是2.第一个存的是全连接矩阵,第二个存的是偏置. 对于稍微复杂的网络 例如MLP mlp = nn.Sequential
-
pytorch 实现查看网络中的参数
可以通过model.state_dict()或者model.named_parameters()函数查看现在的全部可训练参数(包括通过继承得到的父类中的参数) 可示例代码如下: params = list(model.named_parameters()) (name, param) = params[28] print(name) print(param.grad) print('-------------------------------------------------') (name
-
在pytorch中查看可训练参数的例子
pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的. pytorch中model.parameters()函数定义如下: def parameters(self): r"""Returns an iterator over module parameters. This is typically passed to an optimizer. Yields: Parameter: module paramete
-

pytorch如何获得模型的计算量和参数量
方法1 自带 pytorch自带方法,计算模型参数总量 total = sum([param.nelement() for param in model.parameters()]) print("Number of parameter: %.2fM" % (total/1e6)) 或者 total = sum(p.numel() for p in model.parameters()) print("Total params: %.2fM" % (total/1e
-
在pytorch中如何查看模型model参数parameters
目录 pytorch查看模型model参数parameters pytorch查看模型参数总结 1:DNN_printer 2:parameters 3:get_model_complexity_info() 4:torchstat pytorch查看模型model参数parameters 示例1:pytorch自带的faster r-cnn模型 import torch import torchvision model = torchvision.models.detection.faster
-
关于pytorch中网络loss传播和参数更新的理解
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇. TensorFlow: 228--->266 Keras: 42--->56 Pytorch: 87--->252 在使用pytorch中,自己有一些思考,如下: 1. loss计算和反向传播 import torch.nn as nn
-
在Pytorch中计算自己模型的FLOPs方式
https://github.com/Lyken17/pytorch-OpCounter 安装方法很简单: pip install thop 基本用法: from torchvision.models import resnet50from thop import profile model = resnet50() flops, params = profile(model, input_size=(1, 3, 224,224)) 对自己的module进行特别的计算: class YourMo
-
解决Pytorch中的神坑:关于model.eval的问题
有时候使用Pytorch训练完模型,在测试数据上面得到的结果令人大跌眼镜. 这个时候需要检查一下定义的Model类中有没有 BN 或 Dropout 层,如果有任何一个存在 那么在测试之前需要加入一行代码: #model是实例化的模型对象 model = model.eval() 表示将模型转变为evaluation(测试)模式,这样就可以排除BN和Dropout对测试的干扰. 因为BN和Dropout在训练和测试时是不同的: 对于BN,训练时通常采用mini-batch,所以每一批中的mean
-
Pytorch中的modle.train,model.eval,with torch.no_grad解读
目录 modle.train,model.eval,with torch.no_grad解读 model.eval()与torch.no_grad()的作用 model.eval() torch.no_grad() 异同 总结 modle.train,model.eval,with torch.no_grad解读 1. 最近在学习pytorch过程中遇到了几个问题 不理解为什么在训练和测试函数中model.eval(),和model.train()的区别,经查阅后做如下整理 一般情况下,我们训练
-
关于Pytorch中模型的保存与迁移问题
目录 1 引言 2 模型的保存与复用 2.1 查看网络模型参数 2.2 载入模型进行推断 2.3 载入模型进行训练 2.4 载入模型进行迁移 3 总结 1 引言 各位朋友大家好,欢迎来到月来客栈.今天要和大家介绍的内容是如何在Pytorch框架中对模型进行保存和载入.以及模型的迁移和再训练.一般来说,最常见的场景就是模型完成训练后的推断过程.一个网络模型在完成训练后通常都需要对新样本进行预测,此时就只需要构建模型的前向传播过程,然后载入已训练好的参数初始化网络即可. 第2个场景就是模型的再训练过
-
浅谈pytorch中的BN层的注意事项
最近修改一个代码的时候,当使用网络进行推理的时候,发现每次更改测试集的batch size大小竟然会导致推理结果不同,甚至产生错误结果,后来发现在网络中定义了BN层,BN层在训练过程中,会将一个Batch的中的数据转变成正太分布,在推理过程中使用训练过程中的参数对数据进行处理,然而网络并不知道你是在训练还是测试阶段,因此,需要手动的加上,需要在测试和训练阶段使用如下函数. model.train() or model.eval() BN类的定义见pytorch中文参考文档 补充知识:关于pyto
-
pytorch 中forward 的用法与解释说明
前言 最近在使用pytorch的时候,模型训练时,不需要使用forward,只要在实例化一个对象中传入对应的参数就可以自动调用 forward 函数 即: forward 的使用 class Module(nn.Module): def __init__(self): super(Module, self).__init__() # ...... def forward(self, x): # ...... return x data = ..... #输入数据 # 实例化一个对象 module
-
pytorch 使用半精度模型部署的操作
背景 pytorch作为深度学习的计算框架正得到越来越多的应用. 我们除了在模型训练阶段应用外,最近也把pytorch应用在了部署上. 在部署时,为了减少计算量,可以考虑使用16位浮点模型,而训练时涉及到梯度计算,需要使用32位浮点,这种精度的不一致经过测试,模型性能下降有限,可以接受. 但是推断时计算量可以降低一半,同等计算资源下,并发度可提升近一倍 具体方法 在pytorch中,一般模型定义都继承torch.nn.Moudle,torch.nn.Module基类的half()方法会把所有参数