JS实现单个或多个文件批量下载的方法详解
目录
- 前言
- 单个文件Download
- 方案一:location.href or window.open
- 方案二:通过a标签的download属性
- 方案三:API请求
- 多个文件批量Download
- 方案一:按单个文件download方式,循环依次下载
- 方案二:前端打包成zip download
- 方案三:后端压缩成zip,然后以文件流url形式,前端调用download
- 总结
前言
在前端Web开发中,下载文件是一个很常见的需求,也有一些比较特殊的Case,比如下载文件请求是一个POST、url不是同源的、批量下载文件等。本文就介绍下几种download解决方案,以及特殊Case的最佳方案选择。
单个文件Download
方案一:location.href or window.open
<a href={url} target="_blank">download</a>
window.location.href = url; // 当前tab window.open(url); // 新tab
缺点:
1.只支持get请求,不支持post请求。
2.浏览器会根据header的content-type来判断是下载文件还是预览文件。
比如 txt png 等格式文件,会在当前tab或新tab中预览,而不是下载下来。
3.由于只支持get,会有url参数过长问题。
4.不能加request header,无法做权限验证等逻辑。
5.不支持自定义file name。
方案二:通过a标签的download属性
通过HTML a标签的原生属性,使用浏览器下载。
https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/a#attr-download
<a href={url} download={fileName}>download</a>
function downloadFile(url, fileName) {
const a = document.createElement('a');
a.style.display = 'none';
a.href = url;
a.download = fileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
}
优点:
- 都是走的浏览器下载文件逻辑,不会预览文件。
- 当前tab打开方式下载。
- 支持设置file name。
缺点:
- 只支持get请求,不支持post请求。
- 不能加
request header,无法做权限验证等逻辑。 - 不支持跨域地址。
方案三:API请求
API发送请求的方式,获取文件blog对象,然后通过URL.createObjectURL方法获取download url,然后用方案二的<a download />方式下载。
// 封装一个fetch download方法
async function fetchDownload(fetchUrl, method = "POST", body = null) {
const response = await window.fetch(fetchUrl, {
method,
body: body ? JSON.stringify(body) : null,
headers: {
"Accept": "application/json",
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
},
});
const fileName = getFileName(response);
const blob = await response.blob();
const url = URL.createObjectURL(blob);
return { blob, url, fileName }; // 返回blob、download url、fileName
}
// 根据response header获取文件名
function getFileName(response) {
const disposition = response.headers.get('Content-Disposition');
// 本例格式是:"attachment; filename="img.jpg""
let fileName = disposition.split('filename=')[1].replaceAll('"', '');
// 可以根据自己的格式来截取文件名
// 参考https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Disposition
// let fileName = '';
// if (disposition && disposition.indexOf('attachment') !== -1) {
// const matches = /filename[^;=\n]*=((['"]).*?\2|[^;\n]*)/.exec(disposition);
// fileName = matches?.[1]?.replace(/['"]/g, '');
// }
fileName = decodeURIComponent(fileName);
return fileName;
}
// 页面里调用
// get
fetchDownload('/api/get/file?name=img.jpg', 'GET').then(({ blob, url, fileName }) => {
downloadFile(url, fileName); // 调用方案二的download方法
});
// post
fetchDownload('/api/post/file', 'POST', { name: 'img.jpg' }).then(({ blob, url, fileName }) => {
downloadFile(url, fileName);
});
URL.createObjectURL 生成的url如果过多会有效率问题,可以在合适的时机(download后)释放掉。参考:developer.mozilla.org/zh-CN/docs/…
if (window.URL) {
window.URL.revokeObjectURL(url);
} else {
window.webkitURL.revokeObjectURL(url);
}
优点:
- 因为最后用的是方案二,所以满足方案二的优点。
- 支持post请求、支持跨域(fetch本身支持)。
- 可以加
request header。
缺点:
- 低版本浏览器不支持,可以通过
'download' in document.createElement('a')判断是否支持。 - 浏览器兼容可能有问题,比如Safari、IOS Safari。
多个文件批量Download
有些需求是,点一个按钮需要把多个文件同时download下来,有以下几个方案可以实现。
方案一:按单个文件download方式,循环依次下载
downloadFile("/files/file1.txt", "file1.txt");
downloadFile("/files/word1.docx", "word1.docx");
downloadFile("/files/img1.jpg", "img1.jpg");
利用上面的方案二的<a download />方式下载,会触发浏览器是Download multiple files提示,如果选了Allow则会正常下载。
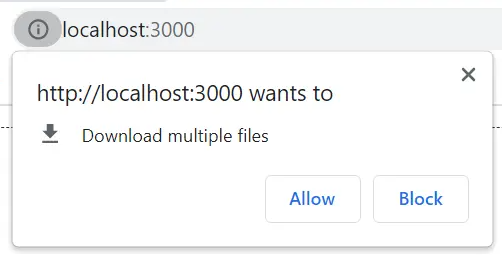
尝试每个download之间加延迟,依然会弹提示。这个应该是浏览器机制问题了,没办法避免了。
方案二:前端打包成zip download
前端可以通过一个第三方库 jszip,可以把多个文件以blob、base64或纯文本等形式,按自定义的文件结构,压缩成一个zip文件,然后通过浏览器download下来。
官网:stuk.github.io/jszip/ 用法不难,直接看code:
// 先封装一个方法,请求返回文件blob
async function fetchBlob(fetchUrl, method = "POST", body = null) {
const response = await window.fetch(fetchUrl, {
method,
body: body ? JSON.stringify(body) : null,
headers: {
"Accept": "application/json",
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
},
});
const blob = await response.blob();
return blob;
}
const zip = new JSZip();
zip.file("Hello.txt", "Hello World\n"); // 支持纯文本等
zip.file("img1.jpg", fetchBlob('/api/get/file?name=img.jpg', 'GET')); // 支持Promise类型,需要返回数据类型是 String, Blob, ArrayBuffer, etc
zip.file("img2.jpg", fetchBlob('/api/post/file', 'POST', { name: 'img.jpg' })); // 同样支持post请求,只要返回类型正确就行
const folder1 = zip.folder("folder01"); // 创建folder
folder1.file("img3.jpg", fetchBlob('/api/get/file?name=img.jpg', 'GET')); // folder里创建文件
zip.generateAsync({ type: "blob" }).then(blob => {
const url = window.URL.createObjectURL(blob);
downloadFile(url, "test.zip");
});
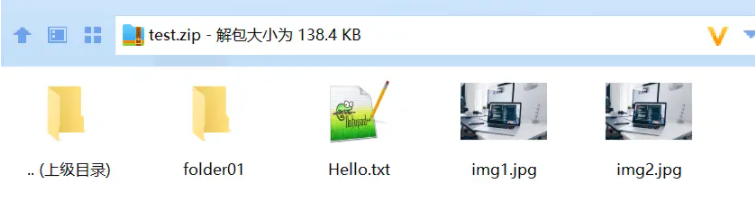
jszip还支持一些别的类型文件压缩,比如纯文本、base64、binary等等,详见:https://stuk.github.io/jszip/documentation/api_jszip/file_data.html
由于走的是纯前端压缩,所以会有延迟问题,走到最后download时才会调起浏览器下载,所以页面可能需要一个效果来更新压缩进度。zip.generateAsync方法就支持第二个参数,支持进度更新:
zip.generateAsync({ type: "blob" }, metadata => {
const progress = metadata.percent.toFixed(2); // 保留2位小数
console.log(metadata.currentFile, "progress: " + progress + " %");
}).then(blob => ... );
方案三:后端压缩成zip,然后以文件流url形式,前端调用download
后台加个api,然后把需要download的文件在后台压缩成zip,然后把文件流输出出来。然后就和单个文件download一样了。
因为后台会先压缩,会有延迟才会把blob返回前台,而且需要传多个文件信息,一般是post请求,所以建议使用单个文件下载的方案三通过API请求实现,在请求前后加上提示语或loading效果。
总结
本文介绍了前端单个文件的下载方案,以及批量多个文件下载的解决方案。最后整理下方案建议:
单个文件下载:
- 如果url是同源的,并且是一个服务器上的静态文件路径、或者是一个get请求,推荐方案二即
<a download />方式下载。 - 反之,方案三即API请求方式。
批量文件下载:
- 如果有zip压缩需求,选方案二或方案三;
- 如果可以接受弹
Download multiple files提示,用方案一;反之方案二或方案三;
以上就是JS实现单个或多个文件批量下载的方法详解的详细内容,更多关于JS文件批量下载的资料请关注我们其它相关文章!
相关推荐
-
javascript实现生成并下载txt文件方式
目录 js生成并下载txt文件 下表显示了FileSaver.js在不同浏览器中的兼容性 js导出文件为txt并下载 首先HTML结构使用最简单的结构 然后js js生成并下载txt文件 下面的简单函数允许您直接在浏览器中生成文件,而无需接触任何服务器. 它适用于所有HTML5就绪的浏览器,因为它使用了<a>的下载属性: function download(filename, text) { var element = document.createElement('a'); elem
-
JavaScript实现多文件下载方法解析
对于文件的下载,可以说是一个十分常见的话题,前端的很多项目中都会有这样的需求,比如 highChart 统计图的导出,在线图片编辑中的图片保存,在线代码编辑的代码导出等等.而很多时候,我们只给了一个链接,用户需要右键点击链接,然后选择"另存为",这个过程虽说不麻烦,但还是需要两步操作,倘若用户想保存页面中的多个链接文件,就得重复操作很多次,最常见的就是英语听力网站上的音频下载,手都要点麻! 本文的目的是介绍如何利用 javascript 进行多文件的下载,也就是当用户点击某个链接或者按
-
前端 javascript 实现文件下载的示例
在 html5 中,a 标签新增了 download 属性,包含该属性的链接被点击时,浏览器会以下载文件方式下载 href 属性上的链接.示例: <a href="https://www.baidu.com" rel="external nofollow" download="baidu.html">下载</a> 1. 前端 js 下载实现与示例 通过 javascript 动态创建一个包含 download 属性的 a
-
通过JavaScript下载文件到本地的方法(单文件)
最近在做一个文件下载的功能,这里把做的过程中用的技术和坑简要总结下. 1. 单文件下载(a标签) 同源单文件 针对单文件的情况下,同源的文件,可以通过 < a> 标签的 download 属性下载文件 const elt = document.createElement('a'); elt.setAttribute('href', url); elt.setAttribute('download', 'file.png'); elt.style.display = 'none'; docume
-

JavaScript 中如何实现大文件并行下载
目录 一.HTTP 范围请求 1.1 Range 语法 二.如何实现大文件下载 2.1 定义辅助函数 2.2 大文件下载使用示例 三.总结 相信有些小伙伴已经了解大文件上传的解决方案,在上传大文件时,为了提高上传的效率,我们一般会使用 Blob.slice 方法对大文件按照指定的大小进行切割,然后在开启多线程进行分块上传,等所有分块都成功上传后,再通知服务端进行分块合并. 那么对大文件下载来说,我们能否采用类似的思想呢?在服务端支持 Range 请求首部的条件下,我们也是可以实现多线程分块下载的
-
JS实现单个或多个文件批量下载的方法详解
目录 前言 单个文件Download 方案一:location.href or window.open 方案二:通过a标签的download属性 方案三:API请求 多个文件批量Download 方案一:按单个文件download方式,循环依次下载 方案二:前端打包成zip download 方案三:后端压缩成zip,然后以文件流url形式,前端调用download 总结 前言 在前端Web开发中,下载文件是一个很常见的需求,也有一些比较特殊的Case,比如下载文件请求是一个POST.url不是
-
.gitignore文件作用及使用方法详解
目录 正文 Git 忽略规则优先级 Git 忽略规则匹配语法 匹配示例 特殊情况 文件已经提交过 添加一个已经配置忽略的文件 检查文件为什么被忽略 gitignore建议 正文 在本地的代码目录中,有些文件或者目录我们并不想提交到仓库中,比如一些运行日志等文件.这样的话,我们提交代码时,就只能一个一个文件去git add,太麻烦了. 为了解决这个问题,Git里面有一个.gitignore文件.可以指定Git需要忽略哪些文件.配置好之后,Git就会自动忽略满足配置的文件.这样,我们就可以尽情的使用
-
Java Spring MVC 上传下载文件配置及controller方法详解
下载: 1.在spring-mvc中配置(用于100M以下的文件下载) <bean class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter"> <property name="messageConverters"> <list> <!--配置下载返回类型--> <bean class="or
-
Python实现批量下载音效素材详解
目录 序言 环境/模块/目标 1.目标 2.开发环境 3.模块 流程讲解 全部代码 序言 作为当代新青年,应该多少会点短视频制作吧? 哈哈,那当代自媒体创作者好了~ 制作视频的时候,多少需要一些搞怪的声音?或者奇怪的声音?音乐等等~ 一个个下载多慢,我们今天就用python实现批量下载~ 环境/模块/目标 1.目标 2.开发环境 兄弟们,刚学Python的话,不要安装一些其它的软件,就装这两个就可以了~ Python 环境 Pycharm 编辑器 3.模块 本次使用的模块主要是这两个 reque
-
js基础之DOM中document对象的常用属性方法详解
-----引入 每个载入浏览器的 HTML 文档都会成为 Document 对象. Document 对象使我们可以从脚本中对 HTML 页面中的所有元素进行访问. 属性 1 document.anchors 返回对文档中所有 Anchor 对象的引用.还有document.links/document.forms/document.images等 2 document.URL 返回当前文档的url 3 document.title 返回当前文档的标题 4 do
-
对Python 多线程统计所有csv文件的行数方法详解
如下所示: #统计某文件夹下的所有csv文件的行数(多线程) import threading import csv import os class MyThreadLine(threading.Thread): #用于统计csv文件的行数的线程类 def __init__(self,path): threading.Thread.__init__(self) #父类初始化 self.path=path #路径 self.line=-1 #统计行数 def run(self): reader =
-
对python修改xml文件的节点值方法详解
这是我的xml文件结构 <?xml version='1.0' encoding='utf-8'?> <annotation> <folder>JPEGImages</folder> <filename>train_2018-05-08_1000.jpg</filename> <path>D:\all_data\2018-05-08\JPEGImages\train_2018-05-08_1000.jpg</path
-
对python同一个文件夹里面不同.py文件的交叉引用方法详解
比如有两个模块,一个aa.py,一个bb.py 代码如下: aa.py: #encoding:utf-8 import bb a=1 bb.py: #encoding:utf-8 import aa print aa.a 执行bb.py时,不能执行,打印错误 AttributeError: 'module' object has no attribute 'a' 原因: 如果执行bb的话,这时候bb是__main__,不是module,所以会执行到bb的from aa,这个时候python会执行
-
python文件处理fileinput使用方法详解
这篇文章主要介绍了python文件处理fileinput使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.介绍 fileinput模块可以对一个或多个文件中的内容进行迭代.遍历等操作,我们常用的open函数是对一个文件进行读写操作. fileinput模块的input()函数比open函数更高效和好用,体现在: input()函数生成一个迭代器,保证了在遇到大文件的读取时不会占用太大的内存. 用fileinput对文件进行循环遍历
-
java 使用idea将工程打成jar并创建成exe文件类型执行的方法详解
第一部分: 使用idea 打包工程jar 1.准备好一份 开发好的 可执行的 含有main方法的 工程. 例如:我随便写的main方法 public static void main(String[] args) throws IOException { Properties properties = System.getProperties(); String osName = properties.getProperty("os.name"); System.out.println