go操作Kafka使用示例详解
目录
- 1. Kafka介绍
- 1.1 Kafka是什么
- 1.2 Kafka的特点
- 1.3 常用的场景
- 1.4 Kafka中包含以下基础概念
- 1.5 消息
- 1.6 消息格式
- 2. Kafka深层介绍
- 2.1 架构介绍
- 2.2 ⼯作流程
- 2.3 选择partition的原则
- 2.4 ACK应答机制
- 2.5 Topic和数据⽇志
- 2.6 Partition结构
- 2.7 消费数据
- 3. 操作Kafka
- 3.1 sarama
- 3.2 下载及安装
- 3.3 连接kafka发送消息
- 3.4 连接kafka消费消息
1. Kafka介绍
1.1 Kafka是什么
kafka使用scala开发,支持多语言客户端(c++、java、python、go等)
Kafka最先由LinkedIn公司开发,之后成为Apache的顶级项目。
Kafka是一个分布式的、分区化、可复制提交的日志服务
LinkedIn使用Kafka实现了公司不同应用程序之间的松耦和,那么作为一个可扩展、高可靠的消息系统 支持高Throughput的应用
scale out:无需停机即可扩展机器
持久化:通过将数据持久化到硬盘以及replication防止数据丢失
支持online和offline的场景
1.2 Kafka的特点
Kafka是分布式的,其所有的构件borker(服务端集群)、producer(消息生产)、consumer(消息消费者)都可以是分布式的。
在消息的生产时可以使用一个标识topic来区分,且可以进行分区;每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。
同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡
1.3 常用的场景
监控:主机通过Kafka发送与系统和应用程序健康相关的指标,然后这些信息会被收集和处理从而创建监控仪表盘并发送警告。
消息队列: 应用程度使用Kafka作为传统的消息系统实现标准的队列和消息的发布—订阅,例如搜索和内容提要(Content Feed)。比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统 一般吞吐量相对较低,但是需要更小的端到端延时,并尝尝依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMR或RabbitMQ
站点的用户活动追踪: 为了更好地理解用户行为,改善用户体验,将用户查看了哪个页面、点击了哪些内容等信息发送到每个数据中心的Kafka集群上,并通过Hadoop进行分析、生成日常报告。
流处理:保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始topic来的数据进行 阶段性处理,汇总,扩充或者以其他的方式转换到新的topic下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内 容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返 还给用户。这就在一个独立的topic之外,产生了一系列的实时数据处理的流程。
日志聚合:使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉 文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的 系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟
持久性日志:Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于Apache BookKeeper项目。
1.4 Kafka中包含以下基础概念
1.Topic(话题):Kafka中用于区分不同类别信息的类别名称。由producer指定
2.Producer(生产者):将消息发布到Kafka特定的Topic的对象(过程)
3.Consumers(消费者):订阅并处理特定的Topic中的消息的对象(过程)
4.Broker(Kafka服务集群):已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
5.Partition(分区):Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)
Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
1.5 消息
消息由一个固定大小的报头和可变长度但不透明的字节阵列负载。报头包含格式版本和CRC32效验和以检测损坏或截断
1.6 消息格式
1. 4 byte CRC32 of the message
2. 1 byte "magic" identifier to allow format changes, value is 0 or 1
3. 1 byte "attributes" identifier to allow annotations on the message independent of the version
bit 0 ~ 2 : Compression codec
0 : no compression
1 : gzip
2 : snappy
3 : lz4
bit 3 : Timestamp type
0 : create time
1 : log append time
bit 4 ~ 7 : reserved
4. (可选) 8 byte timestamp only if "magic" identifier is greater than 0
5. 4 byte key length, containing length K
6. K byte key
7. 4 byte payload length, containing length V
8. V byte payload
2. Kafka深层介绍
2.1 架构介绍

Producer:Producer即生产者,消息的产生者,是消息的⼊口。
kafka cluster:kafka集群,一台或多台服务器组成
- Broker:Broker是指部署了Kafka实例的服务器节点。每个服务器上有一个或多个kafka的实 例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的 编号,如图中的broker-0、broker-1等……
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上 都可以创建多个topic。实际应用中通常是一个业务线建一个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞 吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的⽂件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的 时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10 个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机 器对同一个分区也只可能存放一个副本(包括自己)。
Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分 区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个 topic的不同分区的数据,这也是为了提高kafka的吞吐量!
2.2 ⼯作流程
我们看上⾯的架构图中,producer就是生产者,是数据的入口。Producer在写入数据的时候会把数据 写入到leader中,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?我 们看下图:
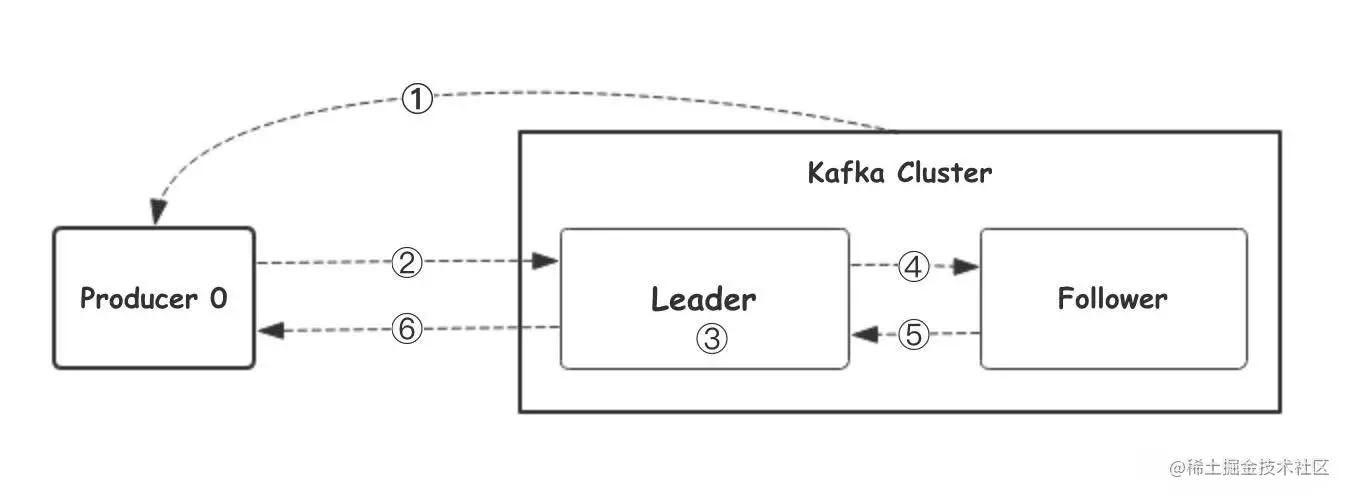
1.⽣产者从Kafka集群获取分区leader信息
2.⽣产者将消息发送给leader
3.leader将消息写入本地磁盘
4.follower从leader拉取消息数据
5.follower将消息写入本地磁盘后向leader发送ACK
6.leader收到所有的follower的ACK之后向生产者发送ACK
2.3 选择partition的原则
那在kafka中,如果某个topic有多个partition,producer⼜怎么知道该将数据发往哪个partition呢? kafka中有几个原则:
1.partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
2.如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
3.如果既没指定partition,又没有设置key,则会采用轮询⽅式,即每次取一小段时间的数据写入某partition,下一小段的时间写入下一个partition
2.4 ACK应答机制
producer在向kafka写入消息的时候,可以设置参数来确定是否确认kafka接收到数据,这个参数可设置 的值为 0,1,all
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效 率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保 leader发送成功和所有的副本都完成备份。安全性最⾼高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,kafka会⾃动创建topic,partition和replication的数量 默认配置都是1。
2.5 Topic和数据⽇志
topic 是同⼀类别的消息记录(record)的集合。在Kafka中,⼀个主题通常有多个订阅者。对于每个 主题,Kafka集群维护了⼀个分区数据⽇志⽂件结构如下:

每个partition都是⼀个有序并且不可变的消息记录集合。当新的数据写⼊时,就被追加到partition的末 尾。在每个partition中,每条消息都会被分配⼀个顺序的唯⼀标识,这个标识被称为offset,即偏移 量。注意,Kafka只保证在同⼀个partition内部消息是有序的,在不同partition之间,并不能保证消息 有序。
Kafka可以配置⼀个保留期限,⽤来标识⽇志会在Kafka集群内保留多⻓时间。Kafka集群会保留在保留 期限内所有被发布的消息,不管这些消息是否被消费过。⽐如保留期限设置为两天,那么数据被发布到 Kafka集群的两天以内,所有的这些数据都可以被消费。当超过两天,这些数据将会被清空,以便为后 续的数据腾出空间。由于Kafka会将数据进⾏持久化存储(即写⼊到硬盘上),所以保留的数据⼤⼩可 以设置为⼀个⽐较⼤的值。
2.6 Partition结构
Partition在服务器上的表现形式就是⼀个⼀个的⽂件夹,每个partition的⽂件夹下⾯会有多组segment ⽂件,每组segment⽂件⼜包含 .index ⽂件、 .log ⽂件、 .timeindex ⽂件三个⽂件,其中 .log ⽂ 件就是实际存储message的地⽅,⽽ .index 和 .timeindex ⽂件为索引⽂件,⽤于检索消息。
2.7 消费数据
多个消费者实例可以组成⼀个消费者组,并⽤⼀个标签来标识这个消费者组。⼀个消费者组中的不同消 费者实例可以运⾏在不同的进程甚⾄不同的服务器上。
如果所有的消费者实例都在同⼀个消费者组中,那么消息记录会被很好的均衡的发送到每个消费者实 例。
如果所有的消费者实例都在不同的消费者组,那么每⼀条消息记录会被⼴播到每⼀个消费者实例。

举个例⼦,如上图所示⼀个两个节点的Kafka集群上拥有⼀个四个partition(P0-P3)的topic。有两个 消费者组都在消费这个topic中的数据,消费者组A有两个消费者实例,消费者组B有四个消费者实例。 从图中我们可以看到,在同⼀个消费者组中,每个消费者实例可以消费多个分区,但是每个分区最多只 能被消费者组中的⼀个实例消费。也就是说,如果有⼀个4个分区的主题,那么消费者组中最多只能有4 个消费者实例去消费,多出来的都不会被分配到分区。其实这也很好理解,如果允许两个消费者实例同 时消费同⼀个分区,那么就⽆法记录这个分区被这个消费者组消费的offset了。如果在消费者组中动态 的上线或下线消费者,那么Kafka集群会⾃动调整分区与消费者实例间的对应关系。
3. 操作Kafka
3.1 sarama
Go语言中连接kafka使用第三方库: github.com/Shopify/sarama。
3.2 下载及安装
go get github.com/Shopify/sarama
注意事项: sarama v1.20之后的版本加入了zstd压缩算法,需要用到cgo,在Windows平台编译时会提示类似如下错误: github.com/DataDog/zstd exec: "gcc":executable file not found in %PATH% 所以在Windows平台请使用v1.19版本的sarama。(如果不会版本控制请查看博客里面的go module章节)
3.3 连接kafka发送消息
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
// 基于sarama第三方库开发的kafka client
func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner // 新选出一个partition
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = "web_log"
msg.Value = sarama.StringEncoder("this is a test log")
// 连接kafka
client, err := sarama.NewSyncProducer([]string{"127.0.0.1:9092"}, config)
if err != nil {
fmt.Println("producer closed, err:", err)
return
}
defer client.Close()
// 发送消息
pid, offset, err := client.SendMessage(msg)
if err != nil {
fmt.Println("send msg failed, err:", err)
return
}
fmt.Printf("pid:%v offset:%v\n", pid, offset)
}
3.4 连接kafka消费消息
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
// kafka consumer
func main() {
consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
partitionList, err := consumer.Partitions("web_log") // 根据topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println(partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := consumer.ConsumePartition("web_log", int32(partition), sarama.OffsetNewest)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
go func(sarama.PartitionConsumer) {
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%v Value:%v", msg.Partition, msg.Offset, msg.Key, msg.Value)
}
}(pc)
}
}
以上就是go操作Kfaka使用示例详解的详细内容,更多关于go操作Kfaka的资料请关注我们其它相关文章!
相关推荐
-
mongoose之bulkWrite操作使用实例
目录 前言 一: bulkWrite小小解释 二:具体操作 insertOne updateOne updateMany deleteOne deleteMany replaceOne 三:优点 四:以下需要注意 五:错误返回 有序执行错误 无序执行错误 六:思考 引用 前言 在执行mongo操作时,有时候大家会觉得力不从心,比如:要给大量的数据更新,但是各个数据更新的内容不一样:需要批量创建大量数据: 以上操作,如果单纯使用findIOneAndUpdate或者save,首先是非常耗时.其次使
-

Go语言文件读写操作案例详解
目录 基本介绍 文件基本操作 读操作 写操作 写操作案例 查看文件或目录是否存在 拷贝文件 基本介绍 文件,对我们并不陌生,文件是数据源(保存数据的地方)的 一种 输入流和输出流 文件在程序中是以流的形式来操作的 流:数据在数据源(文件)和程序(内存)之间经历的路径 输入流:数据从文件到内存的路径 输出流:数据从内存到文件的路径 os.File封装所有文件相关操作,File是一个结构体 文件基本操作 读操作 package main import ( "bufio" "fmt
-
Go操作Kafka和Etcd方法详解
目录 操作Kafka sarama 下载及安装 注意事项 连接 kafka 发送消息 连接 kafka 消费消息 操作Etcd 安装 put和get操作 watch操作 安装报错: 操作Kafka Kafka 是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能.持久化.多副本备份.横向扩展等特点.本文介绍了如何使用 Go 语言发送和接收 kafka 消息. sarama Go 语言中连接 kafka 使用第三方库:github.com/Shopify
-
GO语言基本类型String和Slice,Map操作详解
目录 本文大纲 1.字符串String String常用操作:获取长度和遍历 字符串的strings包 字符串的strconv包: 2.切片Slice 3.集合Map 本文大纲 本文继续学习GO语言基础知识点. 1.字符串String String是Go语言的基本类型,在初始化后不能修改,Go字符串是一串固定长度的字符连接起来的字符序列,当然它也是一个字节的切片(Slice). import ("fmt") func main() { name := "Hello World
-
golang MySQL实现对数据库表存储获取操作示例
目录 新建数据库 config.go gameblog.go http Simplify server.go comment.go gameblog.go server.go postman test api Axios gamelist.go HTTP gamelist.go server.go Axios 新建数据库 将部分数据存储至Mysql,使用axios通过golang搭建的http服务器获取数据. sql DROP DATABASE VUE; create database if n
-
Go语言文件开关及读写操作示例
目录 ️ 实战场景 打开关闭文件 读取文件 bufio 读取文件 写文件 ️ 实战场景 本篇博客为大家再次带来 Go 语言的基础知识,这次要学习的内容是 Go 中的文件操作. 打开关闭文件 在 Go 中操作文件,首先要做的就是导入 os 模块,该模块中具备相关函数定义. package main import ( "fmt" "os" ) func main() { // 打开文件 file, err := os.Open("./ca.txt")
-
Django静态文件配置request对象方法ORM操作讲解
目录 django框架请求流程 静态文件及相关配置 请求方法 request对象方法 pycharm链接MySQL Django链接MySQL Django ORM ORM语法 ORM外键关联 django框架请求流程 静态文件及相关配置 ORM:对象关系映射 python 映射 数据库类 表 对象 记录对象.属性 字段对应的值'ORM的存在可以使不会MySQL的程序员 使用python的语法操作数据库' 1.先去model.py中编写模型类(相当于是在建表) cl
-
go操作Kafka使用示例详解
目录 1. Kafka介绍 1.1 Kafka是什么 1.2 Kafka的特点 1.3 常用的场景 1.4 Kafka中包含以下基础概念 1.5 消息 1.6 消息格式 2. Kafka深层介绍 2.1 架构介绍 2.2 ⼯作流程 2.3 选择partition的原则 2.4 ACK应答机制 2.5 Topic和数据⽇志 2.6 Partition结构 2.7 消费数据 3. 操作Kafka 3.1 sarama 3.2 下载及安装 3.3 连接kafka发送消息 3.4 连接kafka消费消息
-
支持PyTorch的einops张量操作神器用法示例详解
目录 基础用法 高级用法 今天做visual transformer研究的时候,发现了einops这么个神兵利器,决定大肆安利一波. 先看链接:https://github.com/arogozhnikov/einops 安装: pip install einops 基础用法 einops的强项是把张量的维度操作具象化,让开发者"想出即写出".举个例子: from einops import rearrange # rearrange elements according to the
-
利用Python中xlwt模块操作excel的示例详解
目录 一.安装 二.创建表格并写入 三.设置单元格样式 四.设置单元格宽度 五.设置单元格背景色 六.设置单元格内容对齐方式 七.单元格添加超链接 八.单元格添加公式 九.单元格中输入日期 十.合并行和列 十一.单元格添加边框 一.安装 pip install xlwt 二.创建表格并写入 import xlwt # 创建一个workbook并设置编码 workbook = xlwt.Workbook(encoding = 'utf-8') # 添加sheet worksheet = workb
-
使用jmx exporter采集kafka指标示例详解
目录 预置条件 使用JMX exporter暴露指标 kafka集群启用监控 采集producer/consumer的指标 预置条件 安装kafka.prometheus 使用JMX exporter暴露指标 下载jmx exporter以及配置文件.Jmx exporter中包含了kafka各个组件的指标,如server metrics.producer metrics.consumer metrics等,但这些指标并不是prometheus格式的,因此需要通过重命名方式转变为promethe
-
Java利用Selenium操作浏览器的示例详解
目录 简介 设置元素等待 显式等待 隐式等待 强制等待 总结 简介 本文主要介绍如何使用java代码利用Selenium操作浏览器,某些网页元素加载慢,如何操作元素就会把找不到元素的异常,此时需要设置元素等待,等待元素加载完,再操作. 设置元素等待 很多页面都使用 ajax 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性.webdriver 中的等待分为 显式等待 和 隐式等待. 显式等待 显式等待:设置一个超时时间,每个一段时间就去检
-
使用python-pptx操作PPT的示例详解
目录 1. PPT基本结构在python-pptx下定义 1.1. 演示文档结构定义 1.2. 自定义幻灯片母版 2. python-pptx操作PPT实践 2.1. 安装python-pptx 2.2. 读取PPT演示文档 2.3. 基于模板创建新的演示文档 3. 小结 python对PPT演示文档读写,是通过第三方库python-pptx实现的,python-pptx是用于创建和更新 PowerPoint(.pptx)文件的 Python 库. 关于PPT演示文档与幻灯片模板的内容不是本文的
-
React Fiber 链表操作及原理示例详解
目录 正文 什么是Fiber Fiber节点React源码 Fiber树是链表 节点独立 节省操作时间与单向操作 利于双缓存与异步可中断更新操作 异步可中断更新 双缓存 正文 看了React源码之后相信大家都会对Fiber有自己不同的见解,而我对Fiber最大的见解就是这玩意儿就是个链表.如果把整个Fiber树当成一个整体确实有点难理解源码,但是如果把它拆开了,将每个节点都看成一个独立单元却能得到一个很清晰的思路,接下来我就简单几点讲讲,我所认为的为什么React要用链表这种数据结构来构建Fib
-
C#操作INI配置文件示例详解
本文实例为大家分享了C#操作INI配置文件示例的具体代码,供大家参考,具体内容如下 源文件地址:C#操作INI配置文件示例 创建如图所示的控件: 源代码: using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Win
-
Java API操作Hdfs的示例详解
目录 1.遍历当前目录下所有文件与文件夹 2.遍历所有文件 3.创建文件夹 4.删除文件夹 5.上传文件 6.下载文件 1.遍历当前目录下所有文件与文件夹 可以使用listStatus方法实现上述需求.listStatus方法签名如下 /** * List the statuses of the files/directories in the given path if the path is * a directory. * * @param f given path * @return t
-
SpringMVC框架搭建idea2021.3.2操作数据库的示例详解
目录 1.目录 2.PersonController 3.PersonMapper 4.Person 5.PersonServiceImpl 6.PersonService 7.jdbc.properties 8.springmvc-servlet.xml 9.sql 10.pom 1.目录 2.PersonController package com.sk.controller; import com.sk.entity.Person; import com.sk.service.Person