从柯里化分析JavaScript重要的高阶函数实例
目录
- 前情回顾
- 百变柯里化
- 缓存传参
- 缓存判断
- 缓存计算
- 缓存函数
- 防抖与节流
- lodash 高阶函数
- 结语
前情回顾
我们在前篇 《从历史讲起,JavaScript 基因里写着函数式编程》 讲到了 JavaScript 的函数式基因最早可追溯到 1930 年的 lambda 运算,这个时间比第一台计算机诞生的时间都还要早十几年。JavaScript 闭包的概念也来源于 lambda 运算中变量的被绑定关系。
因为在 lambda 演算的设定中,参数只能是一个,所以通过柯里化的天才想法来实现接收多个参数:
lambda x. ( lambda y. plus x y )
说这个想法是“天才”一点不为过,把函数自身作为输入参数或输出返回值,至今受用,也就是【高阶函数】的定义。
将上述 lambda 演算柯里化写法转变到 JavaScript 中,就变成了:
function add(a) {
return function (b) {
return a + b
}
}
add(1)(2)
所以,剖析闭包从柯里化开始,柯里化是闭包的“孪生子”。
读完本篇,你会发现 JavaScript 高阶函数中处处是闭包、处处是柯里化~
百变柯里化
最开始,本瓜理解 柯里化 == 闭包 + 递归,得出的柯里化写法是这样的:
let arr = []
function addCurry() {
let arg = Array.prototype.slice.call(arguments); // 递归获取后续参数
arr = arr.concat(arg);
if (arg.length === 0) { // 如果参数为空,则判断递归结束
return arr.reduce((a,b)=>{return a+b}) // 求和
} else {
return addCurry;
}
}
addCurry(1)(2)(3)()
但这样的写法, addCurry 函数会引用一个外部变量 arr,不符合纯函数的特性,于是就优化为:
function addCurry() {
let arr = [...arguments]
let fn = function () {
if(arguments.length === 0) {
return arr.reduce((a, b) => a + b)
} else {
arr.push(...arguments)
return fn
}
}
return fn
}
上述写法,又总是要以 ‘( )’ 空括号结尾,于是再改进为隐式转换 .toString 写法:
function addCurry() {
let arr = [...arguments]
// 利用闭包的特性收集所有参数值
var fn = function() {
arr.push(...arguments);
return fn;
};
// 利用 toString 隐式转换
fn.toString = function () {
return arr.reduce(function (a, b) {
return a + b;
});
}
return fn;
}
- 注意一些旧版本的浏览器隐式转换会默认执行
好了,到这一步,如果你把上述三种柯里化写法都会手写了,那面试中考柯里化的基础一关算是过了。
然而,不止于此,柯里化实际存在很多变体, 只有深刻吃透它的思想,而非停留在一种写法上,才能算得上“高级”、“优雅”。
接下来,让我们看看它怎么变?!
缓存传参
柯里化最基础的用法是缓存传参。
我们经常遇到这样的场景:
已知一个 ajax 函数,它有 3 个参数 url、data、callback
function ajax(url, data, callback) {
// ...
}
不用柯里化是怎样减少传参的呢?通常是以下这样,写死参数位置的方式来减少传参:
function ajaxTest1(data, callback) {
ajax('http://www.test.com/test1', data, callback);
}
而通过柯里化,则是这样:
function ajax(url, data, callback) {
// ...
}
let ajaxTest2 = partial(ajax,'http://www.test.com/test2')
ajaxTest2(data,callback)
其中 partial 函数是这样写的:
function partial(fn, ...presetArgs) { // presetArgs 是需要先被绑定下来的参数
return function partiallyApplied(...laterArgs) { // ...laterArgs 是后续参数
let allArgs =presetArgs.concat(laterArgs) // 收集到一起
return fn.apply(this, allArgs) // 传给回调函数 fn
}
}
柯里化固定参数的好处在:复用了原本的 ajax 函数,并在原有基础上做了修改,取其精华,弃其糟粕,封装原有函数之后,就能为我所用。
并且 partial 函数不止对 ajax 函数有作用,对于其它想减少传参的函数同样适用。
缓存判断
我们可以设想一个通用场景,假设有一个 handleOption 函数,当符合条件 'A',执行语句:console.log('A');不符合时,则执行语句:console.log('others')
转为代码即:
const handleOption = (param) =>{
if(param === 'A'){
console.log('A')
}else{
console.log('others')
}
}
现在的问题是:我们每次调用 handleOption('A'),都必须要走完 if...else... 的判断流程。比如:
const handleOption = (param) =>{
console.log('每次调用 handleOption 都要执行 if...else...')
if(param === 'A'){
console.log('A')
}else{
console.log('others')
}
}
handleOption('A')
handleOption('A')
handleOption('A')
控制台打印:

有没有什么办法,多次调用 handleOption('A'),却只走一次 if...else...?
答案是:柯里化。
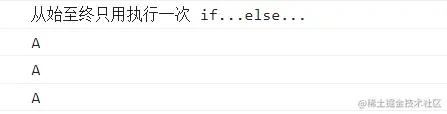
const handleOption = ((param) =>{
console.log('从始至终只用执行一次 if...else...')
if(param === 'A'){
return ()=>console.log('A')
}else{
return ()=>console.log('others')
}
})
const tmp = handleOption('A')
tmp()
tmp()
tmp()
控制台打印:
这样的场景是有实战意义的,当我们做前端兼容时,经常要先判断是来源于哪个环境,再执行某个方法。比如说在 firefox 和 chrome 环境下,添加事件监听是 addEventListener 方法,而在 IE 下,添加事件是 attachEvent 方法;如果每次绑定这个监听,都要判断是来自于哪个环境,那肯定是很费劲。我们通过上述封装的方法,可以做到 一处判断,多次使用。
肯定有小伙伴会问了:这也是柯里化?
嗯。。。怎么不算呢?
把 'A' 条件先固定下来,也可叫“缓存下来”,后续的函数执行将不再传 'A' 这个参数,实打实的:把多参数转化为单参数,逐个传递。
缓存计算
我们再设想这样一个场景,现在有一个函数是来做大数计算的:
const calculateFn = (num)=>{
const startTime = new Date()
for(let i=0;i<num;i++){} // 大数计算
const endTime = new Date()
console.log(endTime - startTime)
return "Calculate big numbers"
}
calculateFn(10_000_000_000)
这是一个非常耗时的函数,在控制台看看,需要 8s+
如果业务代码中需要多次用到这个大数计算结果,多次调用 calculateFn(10_000_000_000) 肯定是不明智的,太费时。
一般的做法就是声明一个全局变量,把运算结果保存下来:
比如 const resNums = calculateFn(10_000_000_000)
如果有多个大数运算呢?沿着这个思路,即声名多个变量:
const resNumsA = calculateFn(10_000_000_000) const resNumsB = calculateFn(20_000_000_000) const resNumsC = calculateFn(30_000_000_000)
我们讲就是说:奥卡姆剃刀原则 —— 如无必要、勿增实体。
申明这么多全局变量,先不谈占内存、占命名空间这事,就把 calculateFn() 函数的参数和声名的常量名一一对应,都是一个麻烦事。
有没有什么办法?只用函数,不增加多个全局常量,就实现多次调用,只计算一次?
答案是:柯里化。
代码如下:
function cached(fn){
const cacheObj = Object.create(null); // 创建一个对象
return function cachedFn (str) { // 返回回调函数
if ( !cacheObj [str] ) { // 在对象里面查询,函数结果是否被计算过
let result = fn(str);
cacheObj [str] = result; // 没有则要执行原函数,并把计算结果缓存起来
}
return cacheObj [str] // 被缓存过,直接返回
}
}
const calculateFn = (num)=>{
console.log("计算即缓存")
const startTime = new Date()
for(let i=0;i<num;i++){} // 大数计算
const endTime = new Date()
console.log(endTime - startTime) // 耗时
return "Calculate big numbers"
}
let cashedCalculate = cached(calculateFn)
console.log(cashedCalculate(10_000_000_000)) // 计算即缓存 // 9944 // Calculate big numbers
console.log(cashedCalculate(10_000_000_000)) // Calculate big numbers
console.log(cashedCalculate(20_000_000_000)) // 计算即缓存 // 22126 // Calculate big numbers
console.log(cashedCalculate(20_000_000_000)) // Calculate big numbers
这样只用通过一个 cached 缓存函数的处理,所有的大数计算都能保证:输入参数相同的情况下,全局只用计算一次,后续可直接使用更加语义话的函数调用来得到之前计算的结果。
此处也是柯里化的应用,在 cached 函数中先传需要处理的函数参数,后续再传入具体需要操作得值,将多参转化为单个参数逐一传入。
缓存函数
柯里化的思想不仅可以缓存判断条件,缓存计算结果、缓存传参,还能缓存“函数”。
设想,我们有一个数字 7 要经过两个函数的计算,先乘以 10 ,再加 100,写法如下:
const multi10 = function(x) { return x * 10; }
const add100 = function(x) { return x + 100; }
add100(multi10(7))
用柯里化处理后,即变成:
const multi10 = function(x) { return x * 10; }
const add100 = function(x) { return x + 100; }
const compose = function(f,g) {
return function(x) {
return f(g(x))
}
}
compose(add100, multi10)(7)
前者写法有两个传参是写在一起的,而后者则逐一传参。把最后的执行函数改写:
let compute = compose(add100, multi10) compute(7)
所以,这里的柯里化直接把函数处理给缓存了,当声明 compute 变量时,并没有执行操作,只是为了拿到 ()=> f(g(x)),最后执行 compute(7),才会执行整个运算;
怎么样?柯里化确实百变吧?柯里化的起源和闭包的定义是同宗同源。正如前文最开始所说,柯里化是闭包的一对“孪生子”。
我们对闭包的解释:“闭包是一个函数内有另外一个函数,内部的函数可以访问外部函数的变量,这样的语法结构是闭包。”与我们对柯里化的解释“把接受多个参数的函数变换成接受一个单一参数(或部分)的函数,并且返回接受余下的参数和返回结果的新函数的技术”,这两种说法几乎是“等效的”,只是从不同角度对 同一问题 作出的解释,就像 lambda 演算和图灵机对希尔伯特第十问题的解释一样。
同一问题:指的是在 lambda 演算诞生之时,提出的:怎样用 lambda 演算实现接收多个参数?
防抖与节流
好了,我们再来看看除了其它高阶函数中闭包思想(柯里化思想)的应用。首先是最最常用的防抖与节流函数。
防抖:就像英雄联盟的回城键,按了之后,间隔一定秒数才会执行生效。
function debounce(fn, delay) {
delay = delay || 200;
let timer = null;
return function() {
let arg = arguments;
// 每次操作时,清除上次的定时器
clearTimeout(timer);
timer = null;
// 定义新的定时器,一段时间后进行操作
timer = setTimeout(function() {
fn.apply(this, arg);
}, delay);
}
};
var count = 0;
window.onscroll = debounce(function(e) {
console.log(e.type, ++count); // scroll
}, 500);
节流函数:就像英雄联盟的技能键,是有 CD 的,一段时间内只能按一次,按了之后就要等 CD;
// 函数节流,频繁操作中间隔 delay 的时间才处理一次
function throttle(fn, delay) {
delay = delay || 200;
let timer = null;
// 每次滚动初始的标识
let timestamp = 0;
return function() {
let arg = arguments;
let now = Date.now();
// 设置开始时间
if (timestamp === 0) {
timestamp = now;
}
clearTimeout(timer);
timer = null;
// 已经到了delay的一段时间,进行处理
if (now - timestamp >= delay) {
fn.apply(this, arg);
timestamp = now;
}
// 添加定时器,确保最后一次的操作也能处理
else {
timer = setTimeout(function() {
fn.apply(this, arg);
// 恢复标识
timestamp = 0;
}, delay);
}
}
};
var count = 0;
window.onscroll = throttle(function(e) {
console.log(e.type, ++count); // scroll
}, 500);
代码均可复制到控制台中测试。在防抖和节流的场景下,被预先固定住的变量是 timer。
lodash 高阶函数
lodash 大家肯定不陌生,它是最流行的 JavaScript 库之一,透过函数式编程模式为开发者提供常用的函数。
其中有一些封装的高阶函数,让一些平平无奇的普通函数也能有相应的高阶功能。
举几个例子:
// 防抖动
_.debounce(func, [wait=0], [options={}])
// 节流
_.throttle(func, [wait=0], [options={}])
// 将一个断言函数结果取反
_.negate(predicate)
// 柯里化函数
_.curry(func, [arity=func.length])
// 部分应用
_.partial(func, [partials])
// 返回一个带记忆的函数
_.memoize(func, [resolver])
// 包装函数
_.wrap(value, [wrapper=identity])
研究源码你就会发现,_.debounce 防抖、_.throttle 节流上面说过,_.curry 柯里化上面说过、_.partial 在“缓存传参”里说过、_.memoize 在“缓存计算”里也说过......
再举一个例子:
现在要求一个函数在达到 n 次之前,每次都正常执行,第 n 次不执行。
也是非常常见的业务场景!JavaScript 实现:
function before(n, func) {
let result, count = n;
return function(...args) {
count = count - 1
if (count > 0) result = func.apply(this, args)
if (count <= 1) func = undefined
return result
}
}
const fn= before(3,(x)=>console.log(x))
fn(1) // 1
fn(2) // 2
fn(3) // 不执行
反过来:函数只有到 n 次的时候才执行,n 之前的都不执行。
function after(n, func) {
let count = n || 0
return function(...args) {
count = count - 1
if (count < 1) return func.apply(this, args)
}
}
const fn= after(3,(x)=>console.log(x))
fn(1) // 不执行
fn(2) // 不执行
fn(3) // 3
全是“闭包”、全是把参数“柯里化”。
细细体会,在控制台上敲一敲、改一改、跑一跑,下次或许你就可以自己写出这些有特定功能的高阶函数了。
结语
综合以上,可见由函数式启发的“闭包”、“柯里化”思想对 JavaScript 有多重要。几乎所有的高阶函数都离不开闭包、参数由多转逐一的柯里化传参思想。所在在很多面试中,都会问闭包,不管是一两年、还是三五年经验的前端程序员。定义一个前端的 JavaScript 技能是初级,还是中高级,这是其中很重要的一个判断点。
对闭包概念模糊不清的、或者只会背概念的 => 初级
会写防抖、节流、或柯里化等高阶函数的 => 中级
深刻理解高阶函数封装思想、能自主用闭包封装高阶函数 => 高级
以上就是从柯里化分析JavaScript重要的高阶函数实例的详细内容,更多关于JavaScript 柯里化高阶函数的资料请关注我们其它相关文章!
相关推荐
-
从JavaScript纯函数解析最深刻的函子 Monad实例
目录 序言 纯函数 输入 & 输出 副作用 “纯”的好处 自文档化 组合函数 引用透明性 其它 无形参风格 Monad 结语 序言 转眼间,来到专栏第 3 篇,前两篇分别是: 从历史讲起,JavaScript 基因里写着函数式编程 从柯里化讲起,一网打尽 JavaScript 重要的高阶函数 建议按顺序“食用”.饮水知其源,由 lambda 演算演化而来的闭包思想是 JavaScript 写在基因里的东西,闭包的“孪生子”柯里化,是封装高阶函数的利器. 当我们频繁使用高阶函数.甚至自己不断在封装
-
JavaScript函数式编程示例分析
目录 函数式编程 函数柯理化(Curring) Compose 场景案例 总结 函数式编程 1.函数式编程指的是函数的映射关系 2.vue3.react16.8的函数组件推动了前端函数编程 3.必须是纯函数(幂等):同样的输入有同样的输出 //非纯函数 function getFirst1(arr){ return arr.splice(0,1); }; //纯函数 function getFirst2(arr){ return arr.slice(0,1); }; const arr = [1
-
JavaScript前端面试组合函数
经历过一些列的函数式编程思想的学习总结,一些重要的高阶函数的学习,以及前一段时间关于 RxJS 的学习. 我们再回看一次 —— 组合函数 compose 本瓜越来越觉得,[易读]的代码应该是将声明和调用分开来的.根据不同的流程,用函数组合的方式.也可以说它是管道.或者说是链式调用,将声明的函数组合起来,再等待时机进行调用. 如果没有组合函数 compose,函数连续调用将会是嵌套的: const multi10 = function(x) { return x * 10; } const toS
-
JS函数式编程之纯函数、柯里化以及组合函数
目录 前言 纯函数 纯函数的概念 副作用 纯函数案例 柯里化 柯里化的概念 函数柯里化的过程 函数柯里化的特点及应用 自动柯里化函数的实现 组合函数 前言 函数式编程(Functional Programming),又称为泛函编程,是一种编程范式. 早在很久以前就提出了函数式编程这个概念了,而后面一直长期被面向对象编程所统治着,最近几年函数式编程又回到了大家的视野中,JavaScript是一门以函数为第一公民的语言,必定是支持这一种编程范式的. 下面就来谈谈JavaScript函数式编程中的核心
-
JavaScript函数式编程实现介绍
目录 为什么要学习函数式编程 什么是函数式编程 前置知识 函数是一等公民 函数可以储存在变量中 函数作为参数 函数作为返回值 高阶函数 什么是高阶函数 使用高阶函数的意义 常用高阶函数 闭包 纯函数 纯函数概念 纯函数的好处 副作用 柯里化 函数组合 Functor(函子) MayBe 函子 Either函子 为什么要学习函数式编程 Vue进入3.*(One Piece 海贼王)世代后,引入的setup语法,颇有向老大哥React看齐的意思,说不定前端以后还真是一个框架的天下.话归正传,框架的趋
-
JavaScript函数柯里化
目录 1 什么是函数柯里化 2 柯里化的作用和特点 2.1 参数复用 2.2 提前返回 2.3 延迟执行 3 封装通用柯里化工具函数# 4 总结和补充 1 什么是函数柯里化 在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术.这个技术以逻辑学家 Haskell Curry 命名的. 什么意思?简单来说,柯里化是一项技术,它用来改造多参数的函数. 比如: // 这是一个接受3个参数的函
-
JavaScript函数式编程(Functional Programming)纯函数用法分析
本文实例讲述了JavaScript函数式编程(Functional Programming)纯函数用法.分享给大家供大家参考,具体如下: 函数式编程鼓励我们多创建纯函数(pure functions),纯函数只依赖你交给它的东西,不使用任何函数以外的东西,也不会影响到函数以外的东西.跟纯函数对应的就是不纯函数(impure functions),也就是不纯函数可能会使用函数以外的东西,比如使用了一个全局变量.也可能会影响到函数以外的东西,比如改变了一个全局变量的值. 多使用纯属函数是因为它更可靠
-
从柯里化分析JavaScript重要的高阶函数实例
目录 前情回顾 百变柯里化 缓存传参 缓存判断 缓存计算 缓存函数 防抖与节流 lodash 高阶函数 结语 前情回顾 我们在前篇 <从历史讲起,JavaScript 基因里写着函数式编程> 讲到了 JavaScript 的函数式基因最早可追溯到 1930 年的 lambda 运算,这个时间比第一台计算机诞生的时间都还要早十几年.JavaScript 闭包的概念也来源于 lambda 运算中变量的被绑定关系. 因为在 lambda 演算的设定中,参数只能是一个,所以通过柯里化的天才想法来实现接
-
javascript之典型高阶函数应用介绍二
前言 在前一篇文章javascript之典型高阶函数中主要实现了几个典型的functional函数.文章最后也提出了疑问,为啥那样的实现与F#之类的函数式语言"不太一样"呢?今天来试试更"函数式"的实现. 另一种实现 同样地,尝试对之前实现的函数做一些改动,把for循环去掉.如何去掉呢?这里先要引入一个集合的归纳法定义: 一个集合要么是空集,要么是一个数与一个集合组成的数对从定义可以看到,每一个集合都可以看作为一个数和一个集合的对.例如:{1,2,4,5} 可以认为
-
Javascript中的高阶函数介绍
这是一个有趣的东西,这或许也在说明Javascript对象的强大.我们要做的就是在上一篇说到的那样,输出一个Hello,World,而输入的东西是print('Hello')('World'),而这就是所谓的高阶函数. 高阶函数 高阶看上去就像是一种先进的编程技术的一个深奥术语,一开始我看到的时候我也这样认为的. Javascript的高阶函数 然而,高阶函数只是将函数作为参数或返回值的函数.以上面的Hello,World作为一个简单的例子. 复制代码 代码如下: var Moqi = func
-
Javascript 常见的高阶函数详情
目录 一.常见的高阶函数 1.1.filter 1.2.map 1.3.reduce 高阶函数,英文叫 Higher Order function.一个函数可以接收另外一个函数作为参数,这种函数就叫做高阶函数. 示例: function add(x, y, f) { return f(x) + f(y); } //用代码验证一下: add(-5, 6, Math.abs); // 11 一.常见的高阶函数 ES6中数组新增了几种方法,其中 map.reduce.filter 几个都是高阶函数,除
-
javascript之典型高阶函数应用介绍
缘由 虽然以前也使用过javascript语言,但终究是为了配合后端写的一些零零散散的"代码段",更不能说是javascript项目了.很荣幸的是上个月刚到公司正好碰上项目开始推倒重写,我们team从头开始做架构和实现,目的很清楚,为了改进和超越前面的版本.这是个真正意义上的javascript"项目",当然服务端不是我们team来负责啦.这也是我真正开始全职使用javascript来编程.由于之前在学校对形式化方法这门课程比较感兴趣,而javascript又是函数
-
react中事件处理与柯里化的实现
目录 1. 事件处理 阻止默认行为 合成事件 2. 柯里化 柯里化的目的 一个简单的例子 1. 事件处理 React 中元素也可接受.处理事件,但是在语法上有一点不同. 在React 中所有事件的命名采用的是小驼峰,而非原生 DOM 的纯小写,所有事件需要我们传入一个函数,而非字符串. 例如: const Button = () => { const handleClick = () => { console.log('click') } return <button onClick={
-
JavaScript偏函数与柯里化实例详解
本文实例讲述了JavaScript偏函数与柯里化.分享给大家供大家参考,具体如下: 到目前为止我们仅讨论绑定this,现在让我们更深入学习. 我们不仅能绑定this,也可以是参数,这较少使用,但有时很方便. bind完整的语法为: let bound = func.bind(context, arg1, arg2, ...); 可以绑定上下文this和函数的初始参数.举例,我们有个乘法函数mul(a,b): function mul(a, b) { return a * b; } 我们可以在该函
-

前端JavaScript彻底弄懂函数柯里化curry
目录 一.什么是柯里化( curry) 二.柯里化的用途 三.如何封装柯里化工具函数 一.什么是柯里化( curry) 在数学和计算机科学中,柯里化是一种将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术. 举例来说,一个接收3个参数的普通函数,在进行柯里化后, 柯里化版本的函数接收一个参数并返回接收下一个参数的函数, 该函数返回一个接收第三个参数的函数. 最后一个函数在接收第三个参数后, 将之前接收到的三个参数应用于原普通函数中,并返回最终结果. 数学和计算科学中的柯里化: // 数
-
浅谈JS中的反柯里化( uncurrying)
反柯里化 相反,反柯里化的作用在与扩大函数的适用性,使本来作为特定对象所拥有的功能的函数可以被任意对象所用. 即把如下给定的函数签名, obj.func(arg1, arg2) 转化成一个函数形式,签名如下: func(obj, arg1, arg2) 这就是 反柯里化的形式化描述. 例如,下面的一个简单实现: Function.prototype.uncurrying = function() { var that = this; return function() { return Func
-
JS中精巧的自动柯里化实现方法
以下内容通过代码讲解和实例分析了JS中精巧的自动柯里化实现方法,并分析了柯里化函数的基础用法和知识,学习一下吧. 什么是柯里化? 在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术.这个技术由 Christopher Strachey 以逻辑学家 Haskell Curry 命名的,尽管它是 Moses Schnfinkel 和 Gottlob Frege 发明的. 理论看着头大?没