Tensorflow 2.1完成对MPG回归预测详解
目录
- 前言
- 1. 获取 Auto MPG 数据并进行数据的归一化处理
- 2. 对数据进行处理
- 搭建深度学习模型
- 使用 EarlyStoping 完成模型训练
- 使用测试数据对模型进行评估
- 使用模型进行预测
- 展示没有进行归一化操作的训练过程
前言
本文的主要内容是使用 cpu 版本的 tensorflor-2.1 完成对 Auto MPG 数据集的回归预测任务。
本文大纲
- 获取 Auto MPG 数据
- 对数据进行处理
- 搭建深度学习模型、并完成模型的配置和编译
- 使用 EarlyStoping 完成模型训练
- 使用测试数据对模型进行评估
- 使用模型进行预测
- 展示没有进行归一化操作的训练过程
1. 获取 Auto MPG 数据并进行数据的归一化处理
(1)Auto MPG 数据集描述了汽车燃油效率的特征值和标签值,我们通过模型的学习可以从特征中找到规律,最后以最小的误差来预测目标 MPG 。
(2)我们使用 keras 自带的函数可以直接从网络上下载数据保存到本地。
(3)每行都包含 MPG 、气缸、排量、马力、重量、加速、车型年份、原产地等八列数据,其中 MPG 就是我们的标签值,其他都是特征。
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
column_names = ['MPG','气缸','排量','马力','重量', '加速', '车型年份', '原产地']
raw_dataset = pd.read_csv(dataset_path, names=column_names, na_values = "?", comment='\t', sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
2. 对数据进行处理
(1)因为数据中存在一些空值,会影响我们对于特征的计算和目标的预测,所以将数据中存在空数据的行删除掉。
dataset = dataset.dropna()
(2)因为“原产地”这一列总共只有 1、2、3 三种值,分别表示三个国家,所以我们将他们各自提出来单独做成一列,这样就相当于给每个国家类别转换成了 ont-hot 。
origin = dataset.pop('原产地')
dataset['阿美莉卡'] = (origin == 1)*1.0
dataset['殴们'] = (origin == 2)*1.0
dataset['小日本子'] = (origin == 3)*1.0
(3)按照一定的比例,取 90% 的数据为训练数据,取 10% 的数据为测试数据。
train_datas = dataset.sample(frac=0.9, random_state=0) test_datas = dataset.drop(train_dataset.index)
(4) 这里主要是使用一些内置的函数来查看训练集对每一列数据的各种常见的统计指标情况,主要有 count、mean、std、min、25%、50%、75%、max ,这样省去了我们后边的计算,直接使用即可。
train_stats = train_datas.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
(5)数据中的 MPG 就是我们需要预测的回归目标,我们将这一列从训练集和测试集中弹出,单独做成标签。 MPG 意思就是 Miles per Gallon ,这是一个衡量一辆汽车在邮箱中只加一加仑汽油或柴油时可以行驶多少英里的中要指标。
train_labels = train_datas.pop('MPG')
test_labels = test_datas.pop('MPG')
(6)这里主要是对训练数据和测试数据进行归一化,将每个特征应独立缩放到相同范围,因为当输入数据特征值存在不同范围时,不利于模型训练的快速收敛,我在文章最后的第七节中放了一张没有进行数据归一化后模型训练评估指标,可以看到很杂乱无章。
def norm(stats, x):
return (x - stats['mean']) / stats['std']
train_datas = norm(train_stats, train_datas)
test_datas = norm(train_stats, test_datas)
搭建深度学习模型
搭建深度学习模型、并完成模型的配置和编译
这里主要是搭建深度学习模型、配置模型并编译模型。
(1)模型主要有三层:
- 第一层主要是一个全连接层操作,将每个样本的所有特征值输入,通过 relu 激活函数的非线性变化,最后输出一个 64 维的向量。
- 第二层主要是一个全连接层操作,将上一层的 64 维的向量,通过 relu 激活函数的非线性变化,最后输出一个 32 维的向量。
- 第三层主要是一个全连接层操作,将上一层的 32 维的向量,最后输出一个 1 维的结果,这其实就是输出预测的回 MPG 。
(2)模型中优化器这里选用 RMSprop ,学习率为 0.001 。
(3)模型中的损失值指标是 MSE ,MSE 其实就是均方差,该统计参数是模型预测值和原始样本的 MPG 值误差的平方和的均值。
(4)模型的评估指标选用 MAE 和 MSE ,MSE 和上面的一样,MAE 是平均绝对误差,该统计参数指的就是模型预测值与原始样本的 MPG 之间绝对误差的平均值。
def build_model():
model = keras.Sequential([ layers.Dense(64, activation='relu', input_shape=[len(train_datas.keys())]),
layers.Dense(32, activation='relu'),
layers.Dense(1) ])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])
return model
model = build_model()
使用 EarlyStoping 完成模型训练
(1)这里使用训练集数据和标签进行模型训练,总共需要进行 1000 个 epoch ,并且在训练过程中选取训练数据的 20% 作为验证集来评估模型效果,为了避免存在过拟合的现象,这里我们用 EarlyStopping 技术来进行优化,也就是当经过一定数量的 epoch (我们这里定义的是 20 )后没有改进效果,则自动停止训练。
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=20) history = model.fit(train_datas, train_labels, epochs=1000, validation_split = 0.2, verbose=2, callbacks=[early_stop])
训练过程的指标输出如下,可以看到到了第 106 次 epoch 之后就停止了训练:
Train on 282 samples, validate on 71 samples Epoch 1/1000 282/282 - 0s - loss: 567.8865 - mae: 22.6320 - mse: 567.8865 - val_loss: 566.0270 - val_mae: 22.4126 - val_mse: 566.0270 Epoch 2/1000 282/282 - 0s - loss: 528.5458 - mae: 21.7937 - mse: 528.5459 - val_loss: 526.6008 - val_mae: 21.5748 - val_mse: 526.6008 ... Epoch 105/1000 282/282 - 0s - loss: 6.1971 - mae: 1.7478 - mse: 6.1971 - val_loss: 5.8991 - val_mae: 1.8962 - val_mse: 5.8991 Epoch 106/1000 282/282 - 0s - loss: 6.0749 - mae: 1.7433 - mse: 6.0749 - val_loss: 5.7558 - val_mae: 1.8938 - val_mse: 5.7558
(2)这里也展示的是模型在训练过程,使用训练集和验证集的 mae 、mse 绘制的两幅图片,我们可以看到在到达 100 多个 epoch 之后,训练过程就终止了,避免了模型的过拟合。
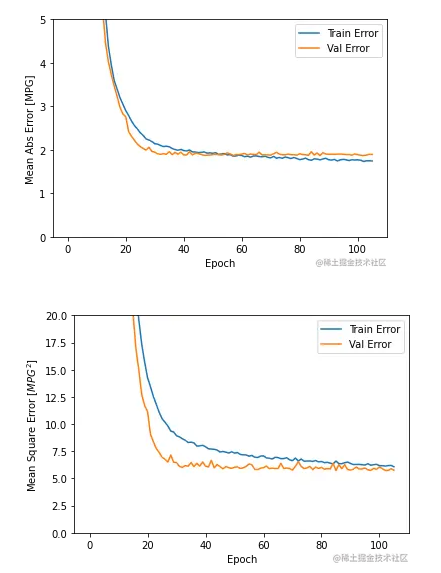
使用测试数据对模型进行评估
loss, mae, mse = model.evaluate(test_datas, test_labels, verbose=2)
print("测试集的 MAE 为: {:5.2f} MPG ,MSE 为 : {:5.2f} MPG".format(mae, mse))
输出结果为:
测试集的 MAE 为: 2.31 MPG ,MSE 为 : 9.12 MPG
使用模型进行预测
我们选取了一条测试数据,使用模型对其 MPG 进行预测。
predictions = model.predict(test_data[:1]).flatten() predictions
结果为 :
array([15.573855], dtype=float32)
而实际的测试样本数据 MPG 为 15.0 ,可以看出与预测值有 0.573855 的误差,其实我们还可以搭建更加复杂的模型,选择更加多的特征来进行模型的训练,理论上可以达到更小的预测误差。
展示没有进行归一化操作的训练过程
我们将没有进行归一化的数据在训练过程中的指标情况进行展示,可以看出来训练的指标杂乱无章。所以一般情况下我们推荐对数据做归一化,有利于模型训练的快速收敛。
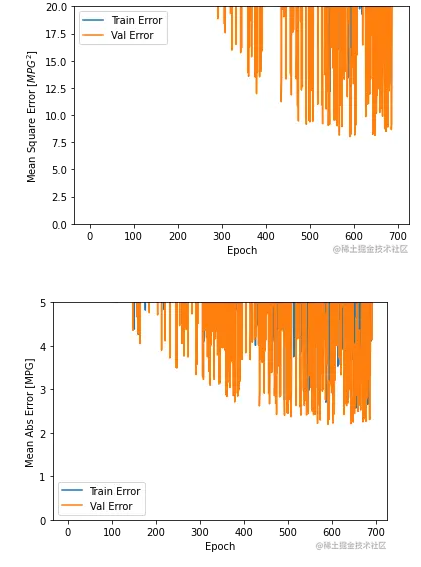
以上就是Tensorflow 2.1完成对MPG回归预测详解的详细内容,更多关于Tensorflow MPG回归预测的资料请关注我们其它相关文章!
相关推荐
-
Tensorflow模型实现预测或识别单张图片
利用Tensorflow训练好的模型,图片进行预测和识别,并输出相应的标签和预测概率. 如果想要多张图片,可以进行批次加载和预测,这里仅用单张图片进行演示. 模型文件: 预测图片: 这里直接贴代码,都有注释,应该很好理解 import tensorflow as tf import inference image_size = 128 # 输入层图片大小 # 模型保存的路径和文件名 MODEL_SAVE_PATH = "model/" MODEL_NAME = "model.
-

python神经网络tensorflow利用训练好的模型进行预测
目录 学习前言 载入模型思路 实现代码 学习前言 在神经网络学习中slim常用函数与如何训练.保存模型文章里已经讲述了如何使用slim训练出来一个模型,这篇文章将会讲述如何预测. 载入模型思路 载入模型的过程主要分为以下四步: 1.建立会话Session: 2.将img_input的placeholder传入网络,建立网络结构: 3.初始化所有变量: 4.利用saver对象restore载入所有参数. 这里要注意的重点是,在利用saver对象restore载入所有参数之前,必须要建立网络结构,因
-
TensorFlow自定义损失函数来预测商品销售量
在预测商品销量时,如果预测多了(预测值比真实销量大),商家损失的是生产商品的成本:而如果预测少了(预测值比真实销量小),损失的则是商品的利润.因为一般商品的成本和商品的利润不会严格相等,比如如果一个商品的成本是1元,但是利润是10元,那么少预测一个就少挣10元:而多预测一个才少挣1元,所以如果神经网络模型最小化的是均方误差损失函数,那么很有可能此模型就无法最大化预期的销售利润. 为了最大化预期利润,需要将损失函数和利润直接联系起来,需要注意的是,损失函数定义的是损失,所以要将利润最大化,定义的损
-
Tensorflow实现酸奶销量预测分析
本文实例为大家分享了Tensorflow酸奶销量预测分析的具体代码,供大家参考,具体内容如下 # coding:utf-8 # 酸奶成本为1元,利润为9元 # 预测少了相应的损失较大,故不要预测少 # 导入相应的模块 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt BATCH_SIZE=8 SEED=23455 COST=3 PROFIT=4 rdm=np.random.RandomState(
-
Tensorflow 2.1完成对MPG回归预测详解
目录 前言 1. 获取 Auto MPG 数据并进行数据的归一化处理 2. 对数据进行处理 搭建深度学习模型 使用 EarlyStoping 完成模型训练 使用测试数据对模型进行评估 使用模型进行预测 展示没有进行归一化操作的训练过程 前言 本文的主要内容是使用 cpu 版本的 tensorflor-2.1 完成对 Auto MPG 数据集的回归预测任务. 本文大纲 获取 Auto MPG 数据 对数据进行处理 搭建深度学习模型.并完成模型的配置和编译 使用 EarlyStoping 完成模型训
-
tensorflow之变量初始化(tf.Variable)使用详解
默认本系列的的读者已经初步熟悉tensorflow. 我们通过tf.Variable构造一个variable添加进图中,Variable()构造函数需要变量的初始值(是一个任意类型.任意形状的tensor),这个初始值指定variable的类型和形状.通过Variable()构造函数后,此variable的类型和形状固定不能修改了,但值可以用assign方法修改. 如果想修改variable的shape,可以使用一个assign op,令validate_shape=False. 通过Varia
-
关于TensorFlow新旧版本函数接口变化详解
TensorFlow版本更新太快 了,所以导致一些以前接口函数不一致,会报错. 这里总结了一下自己犯的错,以防以后再碰到,也可以给别人参考. 首先我的cifar10的代码都是找到当前最新的tf官网给的,所以后面还有新的tf出来改动了的话,可能又会失效了. 1.python3:(unicode error) 'utf-8' codec can't decode 刚开始执行的时候就报这个错,很郁闷后来发现是因为我用多个编辑器编写, 保存.导致不同编辑器编码解码不一致,会报错.所以唯一的办法全程用 一
-
TensorFlow的环境配置与安装教程详解(win10+GeForce GTX1060+CUDA 9.0+cuDNN7.3+tensorflow-gpu 1.12.0+python3.5.5)
记录一下安装win10+GeForce GTX1060+CUDA 9.0+cuDNN7.3+tensorflow-gpu 1.12.0+python3.5.5 之前已经安装过pycharm.Anaconda以及VS2013,因此,安装记录从此后开始 总体步骤大致如下: 1.确认自己电脑显卡型号是否支持CUDA(此处有坑) 此处有坑!不要管NVIDIA控制面板组件中显示的是CUDA9.2.148. 你下载的CUDA不一定需要匹配,尤其是CUDA9.2,最好使用CUDA9.0,我就在此坑摔的比较惨.
-
TensorFlow人工智能学习创建数据实现示例详解
目录 一.数据创建 1.tf.constant() 2.tf.convert_to_tensor() 3.tf.zeros() 4.tf.fill() 二.数据随机初始化 ①tf.random.normal() ②tf.random.truncated_normal() ③tf.random.uniform() ④tf.random.shuffle() 一.数据创建 1.tf.constant() 创建自定义类型,自定义形状的数据,但不能创建类似于下面In [59]这样的,无法解释的数据. 2.
-
用十张图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下TensorFlow的数据读取机制,文章的最后还会给出实战代码以供参考. TensorFlow读取机制图解 首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示: 假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg--我们只需要把
-
详解TensorFlow在windows上安装与简单示例
本文介绍了详解TensorFlow在windows上安装与简单示例,分享给大家,具体如下: 安装说明 平台:目前可在Ubuntu.Mac OS.Windows上安装 版本:提供gpu版本.cpu版本 安装方式:pip方式.Anaconda方式 Tips: 在Windows上目前支持python3.5.x gpu版本需要cuda8,cudnn5.1 安装进度 2017/3/4进度: Anaconda 4.3(对应python3.6)正在安装,又删除了,一无所有了 2017/3/5进度: Anaco
-
windows环境下tensorflow安装过程详解
一.前言 本次安装tensorflow是基于Python的,安装Python的过程不做说明(既然决定按,Python肯定要先了解啊):本次教程是windows下Anaconda安装Tensorflow的过程(cpu版,显卡不支持gpu版的...) 二.安装环境 (tensorflow支持的系统是64位的,windows和linux,mac都需要64位) windows7(其实和windows版本没什么关系,我的是windows7,安装时参照的有windows10的讲解) Python3.5.2(
-
对TensorFlow的assign赋值用法详解
TensorFlow修改变量值后,需要重新赋值,assign用起来有点小技巧,就是需要需要弄个操作子,运行一下. 下面这么用是不行的 import tensorflow as tf import numpy as np x = tf.Variable(0) init = tf.initialize_all_variables() sess = tf.InteractiveSession() sess.run(init) print(x.eval()) x.assign(1) print(x.ev
-
tensorflow: variable的值与variable.read_value()的值区别详解
问题 查看 tensorflow api manual 时,看到关于 variable.read_value() 的注解如图: 那么在 tensorflow 中,variable的值 与 variable.read_value()的值 到底有何区别? 实验代码 # coding=utf-8 import tensorflow as tf # Create a variable. w = tf.Variable(initial_value=10., dtype=tf.float32) sess =