基于MySQL体系结构的分析
了解MySql必须牢牢记住其体系结构图,Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的
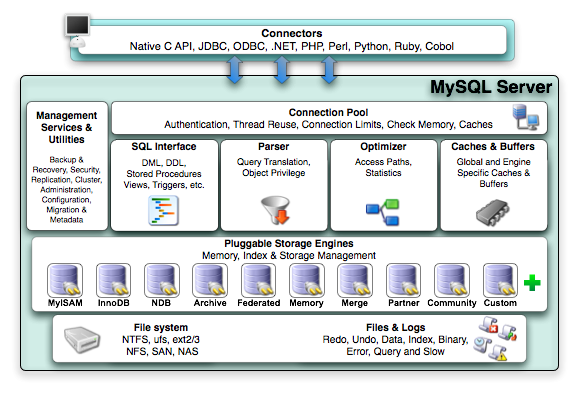
1 Connectors指的是不同语言中与SQL的交互
2 Management Serveices & Utilities: 系统管理和控制工具
3 Connection Pool: 连接池。
管理缓冲用户连接,线程处理等需要缓存的需求
4 SQL Interface: SQL接口。
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
5 Parser: 解析器。
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
6 Optimizer: 查询优化器。
SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果
7 Cache和Buffer: 查询缓存。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
8 Engine :存储引擎。
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。
Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)
现在有很多种存储引擎,各个存储引擎的优势各不一样,最常用的MyISAM,InnoDB,BDB
默认下MySql是使用MyISAM引擎,它查询速度快,有较好的索引优化和数据压缩技术。但是它不支持事务。
InnoDB支持事务,并且提供行级的锁定,应用也相当广泛。
Mysql也支持自己定制存储引擎,甚至一个库中不同的表使用不同的存储引擎,这些都是允许的。
相关推荐
-

基于mysql体系结构的深入解析
由:连接池组件.管理服务和工具组件.sql接口组件.查询分析器组件.优化器组件. 缓冲组件.插件式存储引擎.物理文件组成. mysql是独有的插件式体系结构,各个存储引擎有自己的特点. mysql各个存储引擎概述:innodb存储引擎:[/color][/b] 面向oltp(online transaction processing).行锁.支持外键.非锁定读.默认采用repeaable级别(可重复读)通过next-keylocking策略避免幻读.插入缓冲.二次写.自适应哈希索引
-
基于MySQL体系结构的分析
了解MySql必须牢牢记住其体系结构图,Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的 1 Connectors指的是不同语言中与SQL的交互 2 Management Serveices & Utilities: 系统管理和控制工具 3 Connection Pool: 连接池. 管理缓冲用户连接,线程处理等需要缓存的需求 4 SQL Interface: SQL接口. 接受用户的SQL命令,并且返回用户需要查询的结果.比如select from就是调用SQL Interfac
-
基于MySQL的存储引擎与日志说明(全面讲解)
1.1 存储引擎的介绍 1.1.1 文件系统存储 文件系统:操作系统组织和存取数据的一种机制.文件系统是一种软件. 类型:ext2 3 4 ,xfs 数据. 不管使用什么文件系统,数据内容不会变化,不同的是,存储空间.大小.速度. 1.1.2 mysql数据库存储 MySQL引擎: 可以理解为,MySQL的"文件系统",只不过功能更加强大. MySQL引擎功能: 除了可以提供基本的存取功能,还有更多功能事务功能.锁定.备份和恢复.优化以及特殊功能. 1.1.3 MySQL存储引擎种类
-
浅谈MySQL索引优化分析
为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字段的意义.助你了解索引,分析索引,使用索引,从而写出更高性能的sql语句.还在等啥子?撸起袖子就是干! 案例分析 我们先简单了解一下非关系型数据库和关系型数据库的区别. MongoDB是NoSQL中的一种.NoSQL的全称是Not only SQL,非关系型数据库.它的特点是性能高,扩张性强,模式灵活,在高并发场景表现得尤
-
mysql 体系结构和存储引擎介绍
目录 1 前言 2 mysql 配置文件加载顺序 3 mysql 引擎介绍 3.1 InnoDB 引擎 3.2 MyISAM 引擎 3.3 NDB 引擎 3.4 Archive 引擎 3.5 Federated 引擎 3.6 Maria 引擎 3.7 其它引擎 4 总结 1 前言 mysql 是一个单进程多线程架构的可移植的数据库,mysql 数据库实例在系统上的表现就是一个进程,可以在所有的平台上运行. mysql 的整体架构图如下图所示: 2 mysql 配置文件加载顺序 mysql 启动
-
golang 基于 mysql 简单实现分布式读写锁
目录 业务场景 什么是分布式读写锁 分布式读写锁的访问原则 读锁 写锁 具体实现 通过 gorm 连接 mysql 实现读锁模式 实现写锁模式 总结 业务场景 因为项目刚上线,目前暂不打算引入其他中间件,所以打算通过 mysql 来实现分布式读写锁:而该业务场景也满足分布式读写锁的场景,抽象后的业务场景是:特定资源 X,可以执行 2 种操作:读操作和写操作,2种操作需要满足下面条件: 执行操作的机器分布式在不同的节点中,也就是分布式的: 读操作是共享的,也就是说同时可以有多个 goroutine
-
Mysql通过explain分析定位数据库性能问题
目录 引言 explain基础 exlpain分析实战 总结 引言 数据库性能优化是每个后端程序猿必备的基础技能之一,而Mysql中的explain堪称Mysql的性能优化分析神器,我们可以通过它来分析SQL语句的对应的执行计划在Mysql底层到底是如何执行的,它对于我们评估SQL的执行效率以及确定Mysql的性能优化方向具有重要的意义.但是很多同学对于如何根据explain对已有SQL进行深度的执行分析还是丈二和尚摸不着头脑,因此本文详细阐述通过explain分析定位数据库性能问题. expl
-
基于Mysql的Sequence实现方法
团队更换新框架.新的业务全部使用新的框架,甚至是新的数据库--Mysql. 这边之前一直是使用oracle,各种订单号.流水号.批次号啥的,都是直接使用oracle的sequence提供的数字序列号.现在数据库更换成Mysql了,显然以前的老方法不能适用了. 需要新写一个: •分布式场景使用 •满足一定的并发要求 找了一些相关的资料,发现mysql这方面的实现,原理都是一条数据库记录,不断update它的值.然后大部分的实现方案,都用到了函数. 贴一下网上的代码: 基于mysql函数实现 表结构
-
基于MySql的扩展功能生成全局ID
本文利用 MySQL的扩展功能 REPLACE INTO 来生成全局id,REPLACE INTO和INSERT的功能一样,但是当使用REPLACE INTO插入新数据行时,如果新插入的行的主键或唯一键(UNIQUE Key)已有的行重复时,已有的行会先被删除,然后再将新数据行插入(REPLACE INTO 是原始操作). 建立类似下面的表: CREATE TABLE `tickets64` ( `id` bigint(20) unsigned NOT NULL auto_increment,
-
PHP基于MySQL数据库实现对象持久层的方法
本文实例讲述了PHP基于MySQL数据库实现对象持久层的方法.分享给大家供大家参考.具体如下: 心血来潮,做了一下PHP的对象到数据库的简单持久层. 不常用PHP,对PHP也不熟,关于PHP反射的大部分内容都是现学的. 目前功能比较弱,只是完成一些简单的工作,对象之间的关系还没法映射,并且对象的成员只能支持string或者integer两种类型的. 成员变量的值也没有转义一下... 下面就贴一下代码: 首先是数据库的相关定义,该文件定义了数据库的连接属性: <?php /* * Filename