SQLSERVER中忽略索引提示
当我们想让某条查询语句利用某个索引的时候,我们一般会在查询语句里加索引提示,就像这样
SELECT id,name from TB with (index(IX_xttrace_bal)) where bal<100
当在生产环境里面,由于这个索引提示的原因,优化器一般不会再去考虑其他的索引,那有时候这个索引提示可能会导致查询变慢
经过你的测试,发现确实是因为这个索引提示的关系导致查询变慢,但是SQL服务器已经缓存了这条SQL语句的执行计划,如果修改SQL语句的话可能会有影响
而且,可能不单只一条SQL语句用了索引提示,还有其他的SQL语句也用了索引提示,你不可能马上去修改这些SQL语句的时候可以使用SQLSERVER里面的一个trace flag
这个trace flag能忽略SQL语句里面的索引提示和存储过程里面的索引提示
不需要修改SQL语句,就可以进行性能排查
运行下面脚本创建数据库和相关索引
USE master
GO
IF DB_ID('Trace8602') IS NOT NULL
DROP DATABASE Trace8602
GO
CREATE DATABASE Trace8602
GO
USE Trace8602
GO
CREATE TABLE xttrace8602
(
id INT IDENTITY(1, 1)
PRIMARY KEY ,
bal INT ,
name VARCHAR(100)
)
GO
CREATE NONCLUSTERED INDEX IX_xttrace8602_bal_name ON xttrace8602(bal,name)
GO
CREATE NONCLUSTERED INDEX IX_xttrace8602_bal ON xttrace8602(bal)
GO
INSERT INTO xttrace8602
VALUES ( RAND() * 786, 'cnblogs.com/lyhabc' )
GO 10000
CREATE PROC uspFirst
AS
SELECT id ,
name
FROM xttrace8602 TF WITH ( INDEX ( IX_xttrace8602_bal ) )
WHERE bal < 100
GO
现在执行下面代码
--没有使用跟踪标致
EXEC uspFirst
GO

--使用了跟踪标志
DBCC TRACEON(8602,-1)
GO
DBCC FREEPROCCACHE
GO
EXEC uspFirst
GO
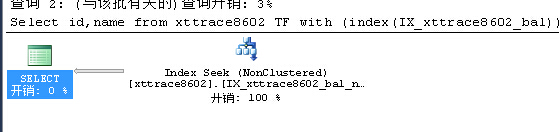
可以看到,打开TRACEON(8602,-1) 跟踪标志之后,SQLSERVER忽略了索引提示,利用复合索引IX_xttrace8602_bal_name 把数据查出来
而不需要额外的键查找
这个跟踪标志不需要你修改你的SQL语句就可以让SQLSERVER忽略索引提示
在使用这个8602跟踪标志之前记得先在开发环境测试好,确认是否需要忽略索引提示,以便做成性能问题
如有不对的地方,欢迎大家拍砖o(∩_∩)o
相关推荐
-

SQLSERVER聚集索引和主键(Primary Key)的误区认识
很多人会把Primary Key和聚集索引搞混起来,或者认为这是同一个东西.这个概念是非常错误的. 主键是一个约束(constraint),他依附在一个索引上,这个索引可以是聚集索引,也可以是非聚集索引. 所以在一个(或一组)字段上有主键,只能说明他上面有个索引,但不一定就是聚集索引. 例如下面: 复制代码 代码如下: USE [pratice] GO CREATE TABLE #tempPKCL ( ID INT PRIMARY KEY CLUSTERED --聚集索引 ) ---------
-
SQLSERVER如何查看索引缺失及DMV使用介绍
当大家发现数据库查询性能很慢的时候,大家都会想到加索引来优化数据库查询性能,但是面对一个复杂的SQL语句,找到一个优化的索引组合对人脑来讲,真的不是一件很简单的事. 好在SQLSERVER提供了两种"自动"功能,给你建议,该怎么调整索引 第一种是使用DMV 第二种是使用DTA (database engine tuning advisor) 数据库引擎优化顾问 这篇文章主要讲第一种 从SQL2005以后,在SQLSERVER对任何一句语句做编译的时候,都会去评估一下, 这句话是不是缺少
-
sqlserver 聚集索引和非聚集索引实例
create database myIndexDemo go use myIndexDemo go create table ABC ( A int not null, B char(10), C varchar(10) ) go insert into ABC select 1,'B','C' union select 5,'B','C' union select 7,'B','C' union select 9,'B','C' go select * from ABC --在ABC表上创建聚
-
sqlserver2005自动创建数据表和自动添加某个字段索引
创建数据表的SQL语句如下: string tatlename = "T_useruid";//定义一个变量.用于自动创建数据表的名称,当前表名为:T_useruid string sql = "CREATE TABLE [dbo].[" + tatlename + "]([Cid] [int] IDENTITY(1,1) NOT NULL,[Uid] [nchar](32) COLLATE Chinese_PRC_CI_AS NULL,CONSTRAIN
-
sqlserver 索引的一些总结
1.1.1 摘要 如果说要对数据库进行优化,我们主要可以通过以下五种方法,对数据库系统进行优化. 1. 计算机硬件调优 2. 应用程序调优 3. 数据库索引优化 4. SQL语句优化 5. 事务处理调优 在本篇博文中,我们将想大家讲述数据库中索引类型和使用场合,本文以SQL Server为例,对于其他技术平台的朋友也是有参考价值的,只要替换相对应的代码就行了! 索引使数据库引擎执行速度更快,有针对性的数据检索,而不是简单地整表扫描(Full table scan). 为了使用有效的索引,我们必须
-
SqlServer 索引自动优化工具
鉴于人手严重不足(当时算两个半人的资源),打消了逐个库手动去改的念头.当前的程序结构不允许搞革命的做法,只能搞搞改良,所以准备搞个自动化工具去处理.原型刚开发完,开会的时候以拿出来就遭到运维DBA团队强烈抵制,具体原因不详.最后无限延期.这里把思路分享下.欢迎拍砖. 整个思路是这样的,索引都是为查询和更新服务的,但是不合适的索引又会对插入和更新带来负面影响.面对表上现有的索引想识别那些是有效的不太可能.那么根据现有的数据使用情况重建所有的新索引不就解决了嘛.根据查询生成全新索引,然后和现有对比,
-
SQLServer2005重建索引前后对比分析
在做维护项目的时,我们经常会遇到索引维护的问题,通过语句,我们就可以判断某个表的索引是否需要重建. 执行一下语句:先分析表的索引 分析表的索引建立情况:DBCC showcontig('Table') DBCC SHOWCONTIG 正在扫描 'Table'' 表... 表: 'Table'' (53575229):索引 ID: 1,数据库 ID: 14 已执行 TABLE 级别的扫描. - 扫描页数................................: 228 - 扫描区数....
-
SQLSERVER 创建索引实现代码
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K.为了加快查找的速度,汉语字(词)典一般都有按拼音.笔画.偏旁部首等排序的目录(索引),我们可以选择按拼音或笔画查找方式,快速查找到需要的字(词). 同理,SQL Server允许用户在表中创建索引,指定按某列预先排序,从而大大提高查询速度. • SQL Server中的数据也是按页(4KB)存放 • 索引:是SQL Server编排数据的内部方法.它
-
sqlserver索引的原理及索引建立的注意事项小结
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上.就好像参考手册将所有主题按顺序编排一样.一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据. SQL Server中的索引使用标准的B-树来存储他们的信息,如下图所示,B-树通过查找索引中的一个关键之来提供对于数据的快速访问,B-树以相似的键记录聚合在一起,B不代表二叉(binary),而是代表balanced(平衡的),而B-树的一个核心作用就
-
SQLSERVER中忽略索引提示
当我们想让某条查询语句利用某个索引的时候,我们一般会在查询语句里加索引提示,就像这样 复制代码 代码如下: SELECT id,name from TB with (index(IX_xttrace_bal)) where bal<100 当在生产环境里面,由于这个索引提示的原因,优化器一般不会再去考虑其他的索引,那有时候这个索引提示可能会导致查询变慢 经过你的测试,发现确实是因为这个索引提示的关系导致查询变慢,但是SQL服务器已经缓存了这条SQL语句的执行计划,如果修改SQL语句的话可能会有影
-
SQLServer中防止并发插入重复数据的方法详解
SQLServer中防止并发插入重复数据,大致有以下几种方法: 1.使用Primary Key,Unique Key等在数据库层面让重复数据无法插入. 2.插入时使用条件 insert into Table(****) select **** where not exists(select 1 from Table where ****); 3.使用SERIALIZABLE隔离级别,并且使用updlock或者xlock锁提示(等效于在默认隔离级别下使用(updlock,holdlock)或(xl
-
详解C#批量插入数据到Sqlserver中的四种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
Oracle数据库中建立索引的基本方法讲解
怎样建立最佳索引? 1.明确地创建索引 create index index_name on table_name(field_name) tablespace tablespace_name pctfree 5 initrans 2 maxtrans 255 storage ( minextents 1 maxextents 16382 pctincrease 0 ); 2.创建基于函数的索引 常用与UPPER.LOWER.TO_CHAR(date)等函数分类上,例: create index
-
SqlServer中如何解决session阻塞问题
简介 对于数据库运维人员来说创建session或者查询时产生问题是常规情况,下面介绍一种很有效且不借助第三方工具的方式来解决类似问题. 最近开始接触运维工作,所以自己总结一些方案便于不懂数据库的同事解决一些不太紧要的数据库问题.类似方法很多理论也很多,我就不做深究,就是简单写一个方案,便于菜鸟使用的. 阻塞理解 在Sql Server 中当一个数据库会话中的事务正锁定一个或多个其他会话事务想要读取或修改的资源时,会产生阻塞(Blocking).通常短时间的阻塞没有问题,且是较忙的应用程序所需要的
-
C#批量插入数据到Sqlserver中的三种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
MySQL入门(五) MySQL中的索引详讲
序言 之前写到MySQL对表的增删改查(查询最为重要)后,就感觉MySQL就差不多学完了,没有想继续学下去的心态了,原因可能是由于别人的影响,觉得对于MySQL来说,知道了一些复杂的查询,就够了,但是我认为,不管有没有用,现在学着不懂的东西,说明就是自己薄弱的地方,多学才能比别人更强 --WH 一.什么是索引?为什么要建立索引? 索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有
-
MongoDB中唯一索引(Unique)的那些事
写在前面 MongoDB支持的索引种类很多,诸如单键索引,复合索引,多键索引,TTL索引,文本索引,空间地理索引等.同时索引的属性可以具有唯一性,即唯一索引.唯一索引用于确保索引字段不存储重复的值,即强制索引字段的唯一性.缺省情况下,MongoDB的_id字段在创建集合的时候会自动创建一个唯一索引.本文主要描述唯一索引的用法. 关于什么是索引以及唯一索引这里就不做说明了,不清楚的可以自行谷歌或者百度.是什么引起我写这篇文章呢,这来自于之前项目中的一个问题. 我们用的是MongoDB数据存储用户信
-
谈谈c#中的索引器
概念 索引器(Indexer) 允许类中的对象可以像数组那样方便.直观的被引用.当为类定义一个索引器时,该类的行为就会像一个 虚拟数组(virtual array) 一样. 索引器可以有参数列表,且只能作用在实例对象上,而不能在类上直接作用. 可以使用数组访问运算符([ ])来访问该类的实例. 索引器的行为的声明在某种程度上类似于属性(property).属性可使用 get 和 set 访问器来定义索引器.但是属性返回或设置的是一个特定的数据成员,而索引器返回或设置对象实例的一个特定值. 定义一
-
SQLServer中exists和except用法介绍
目录 一.exists 1.1 说明 1.2 示例 1.3 intersect/2017-07-21 二.except 2.1 说明 2.2 示例 三.测试数据 一.exists 1.1 说明 EXISTS(包括 NOT EXISTS)子句的返回值是一个 BOOL 值.EXISTS 内部有一个子查询语句(SELECT ... FROM...),我将其称为 EXIST 的内查询语句.其内查询语句返回一个结果集. EXISTS 子句根据其内查询语句的结果集空或者非空,返回一个布尔值. exists: