Redis中AOF与RDB持久化策略深入分析
目录
- 写在前面
- 一、Redis为什么要持久化
- 二、Redis的持久化方式
- 2.1. AOF持久化(Append of file)
- 2.1.1 fsync 系统调用
- 2.1.2 AOF持久化策略
- 2.1.3 aof_rewrite
- 2.2 RDB快照(redis默认持久化方式)
- 触发方式(自动触发和非自动触发)
- 2.3 RDB和AOF混用
- 2.4 三种持久化方式比较
- 三、什么是大key以及大key对持久化的影响
- 3.1 什么是大key
- 3.2 fork进程写时复制原理
- 3.3 面试题-大key对持久化有什么影响
- 四、持久化源码分析
- 4.1 RDB持久化
- 4.1.1 RDB文件的创建
- 4.1.2 RDB文件的载入
- 4.2 AOF持久化
- 4.2.1 AOF持久化实现
- 4.2.2 源码分析
写在前面
以下内容是基于Redis 6.2.6 版本整理总结
一、Redis为什么要持久化
Redis 是一个内存数据库,就是将数据库中的内容保存在内存中,这与传统的MySQL,Oracle等关系型数据库直接将内容保存到硬盘中相比,内存数据库的读写效率比传统数据库要快的多(内存的读写效率远远大于硬盘的读写效率)。但是内存中存储的缺点就是,一旦断电或者宕机,那么内存数据库中的数据将会全部丢失。而且,有时候redis需要重启,要加载回原来的状态,也需要持久化重启之前的状态。
为了解决这个缺点,Redis提供了将内存数据持久化到硬盘,以及用持久化文件来恢复数据库数据的功能。Redis 支持两种形式的持久化,一种是RDB快照(snapshotting),另外一种是AOF(append-only-file)。从Redis4.0版本开始还通过RDB和AOF的混合持久化。
二、Redis的持久化方式
2.1. AOF持久化(Append of file)
OF采用的就是顺序追加的方式,对于磁盘来说,顺序写是最快、最友好的方式。AOF文件存储的是redis命令协议格式的数据。Redis通过重放AOF文件,也就是执行AOF文件里的命令,来恢复数据。
2.1.1 fsync 系统调用
fsync 是系统调动。内核自己的机制,调用fysnc把数据从内核缓冲区刷到磁盘。如果想主动刷盘,就write完调用一次fysnc。
2.1.2 AOF持久化策略
- always 在主线程中执行,每次增删改操作,都要调用fsync 落盘,数据最安全,但效率最低
- every second 在后台线程(bio_fsync_aof)中执行,会丢1~2s的数据
- no 由操作系统决定什么时候刷盘,不可控
缺点:
对数据库所有的修改命令(增删改)都会记录到AOF文件,数据冗余,随着运行时间增加,AOF文件会太过庞大,导致恢复速度变慢。比如:set key v1 ,set key v2 ,del key , set key v3,这四条命令都会被记录。但最终的状态就是key == v3,其余的命令就是冗余的数据。也就是说,我们只需要最后一个状态即可。
2.1.3 aof_rewrite
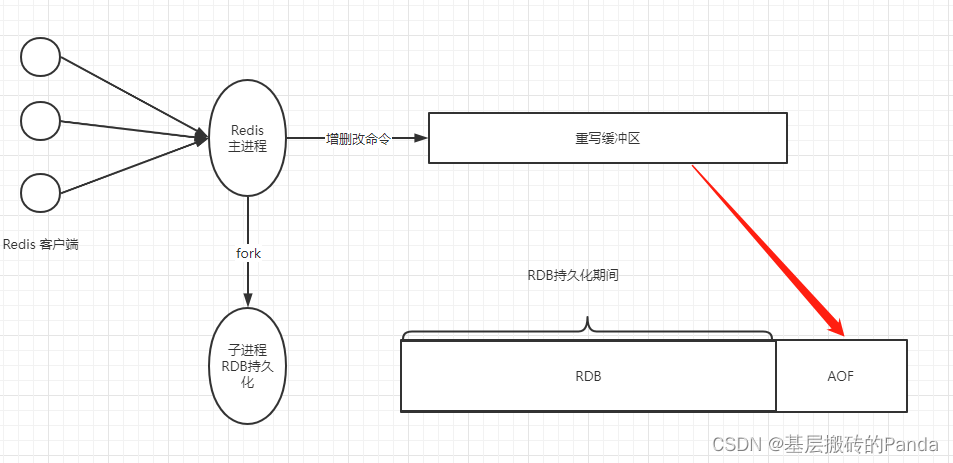
redis针对AOF文件过大的问题,推出了aof_rewrite来优化。aof_rewrite 原理:通过 fork 进程,在子进程中根据当前内存中的数据状态,生成命令协议数据,也就是最新的状态保存到aof文件,避免同一个key的历史数据冗余,提升恢复速度。
在重写aof期间,redis的主进程还在继续响应客户端的请求,redis会将写请求写到重写的缓冲区,等到子进程aof持久化结束,给主进程发信号,主进程再将重写缓冲区的数据追加到新的aof文件中。
虽然rewrite后AOF文件会变小,但aof还是要通过重放的方式恢复数据,需要耗费cpu资源,比较慢。
2.2 RDB快照(redis默认持久化方式)
RDB是把当前内存中的数据集快照写入磁盘RDB文件,也就是 Snapshot 快照(数据库中所有键值对二进制数据)。恢复时是将快照文件直接读到内存里。也是通过fork出子进程去持久化。Redis没有专门的载入RDB文件的命令,Redis服务器会在启动时,如果检测到了RDB文件就会自动载入RDB文件。
触发方式(自动触发和非自动触发)
(1)自动触发
在redis.conf 文件中,SNAPSHOTTING 的配置选项就是用来配置自动触发条件。
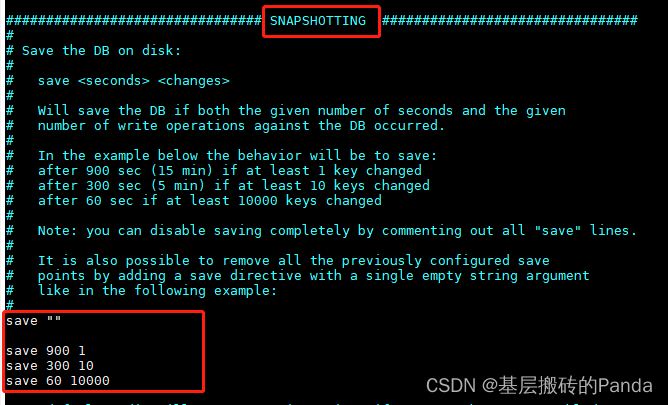
save: 用来配置RDB持久化触发的条件。save m n 表示 m 秒内,数据存在n次修改时,自动触发 bgsave (后台持久化)。
save “” 表示禁用快照;
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存;
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存;
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存。
如果你只需要使用Redis的缓存功能,不需要持久化,只需要注释掉所有的save行即可。
stop-writes-on-bgsave-error: 默认值为 yes。如果RDB快照开启,并且最近的一次快照保存失败了,Redis会拒绝接收更新操作,以此来提醒用户数据持久化失败了,否则这些更新的数据可能会丢失。
rdbcompression:是否启用RDB快照文件压缩存储,默认是开启的,当数据量特别大时,压缩可以节省硬盘空间,但是会增加CPU消耗,可以选择关闭来节省CPU资源,建议开启。
rdbchecksum:文件校验,默认开启。在Redis 5.0版本后,新增了校验功能,用于保证文件的完整性。开启这个选项会增加10%左右的性能损耗,如果追求高性能,可以关闭该选项。
dbfilename :RDB文件名,默认为 dump.rdb
rdb-del-sync-files: Redis主从全量同步时,通过RDB文件传输实现。如果没有开启持久化,同步完成后,是否要移除主从同步的RDB文件,默认为no。
dir:存放RDB和AOF持久化文件的目录 默认为当前目录
(2)手动触发
Redis手动触发RDB持久化的命令有两种:
1)save :该命令会阻塞Redis主进程,在save持久化期间,Redis不能响应处理其他命令,这段时间Redis不可用,可能造成业务的停摆,直至RDB过程完成。一般不用。
2)bgsave:会在主进程fork出子进程进行RDB的持久化。阻塞只发生在fork阶段,而大key会导致fork时间增长。
2.3 RDB和AOF混用
RDB借鉴了aof_rewrite的思路,就是rbd文件写完,再把重写缓冲区的数据,追加到rbd文件的末尾,追加的这部分数据的格式是AOF的命令格式,这就是rdb_aof的混用。
2.4 三种持久化方式比较
- AOF 优点:数据可靠,丢失少;缺点:AOF 文件大,恢复速度慢;
- RDB 优点:RDB文件体积小,数据恢复快。缺点:无法做到实时/秒级持久化,会丢失最后一次快照后的所有数据。每次bgsave运行都需要fork进程,主进程和子进程共享一份内存空间,主进程在继续处理客户端命令时,采用的时写时复制技术,只有修改的那部分内存会重新复制出一份,更新页表指向。复制出的那部分,会导致内存膨胀。具体膨胀的程度,取决于主进程修改的比例有多大。注意:子进程只是读取数据,并不修改内存中的数据。
三、什么是大key以及大key对持久化的影响
3.1 什么是大key
redis 是kv 中的v站用了大量的空间。比如当v的类型是hash、zset,并且里面存储了大量的元素,这个v对应的key就是大key。
3.2 fork进程写时复制原理
在Redis主进程中调用fork()函数,创建出子进程。这个子进程在fork()函数返回时,跟主进程的状态是一模一样的。包括mm_struct和页表。此时,他们的页表都被标记为私有的写时复制状态(只读状态)。当某个进程试图写某个数据页时,会触发写保护,内核会重新为该进程映射一段内存,供其读写,并将页表指向这个新的数据页。
3.3 面试题-大key对持久化有什么影响
结合不同的持久化方式回答。fsync压力大,fork时间长。
如果是AOF:always、every second、no aof_rewrite
如果是RDB: rdb_aof
fork是在主进程中执行的,如果fork慢,会影响到主进程的响应。
四、持久化源码分析
4.1 RDB持久化
4.1.1 RDB文件的创建
Redis是通过rdbSave函数来创建RDB文件的,SAVE 和 BGSAVE 会以不同的方式去调用rdbSave。
// src/rdb.c
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */
int rdbSave(char *filename, rdbSaveInfo *rsi) {
char tmpfile[256];
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
FILE *fp = NULL;
rio rdb;
int error = 0;
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Failed opening the RDB file %s (in server root dir %s) "
"for saving: %s",
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
return C_ERR;
}
rioInitWithFile(&rdb,fp);
startSaving(RDBFLAGS_NONE);
if (server.rdb_save_incremental_fsync)
rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);
if (rdbSaveRio(&rdb,&error,RDBFLAGS_NONE,rsi) == C_ERR) {
errno = error;
goto werr;
}
/* Make sure data will not remain on the OS's output buffers */
if (fflush(fp)) goto werr;
if (fsync(fileno(fp))) goto werr;
if (fclose(fp)) { fp = NULL; goto werr; }
fp = NULL;
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
if (rename(tmpfile,filename) == -1) {
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
strerror(errno));
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
serverLog(LL_NOTICE,"DB saved on disk");
server.dirty = 0;
server.lastsave = time(NULL);
server.lastbgsave_status = C_OK;
stopSaving(1);
return C_OK;
werr:
serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));
if (fp) fclose(fp);
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
SAVE命令,在Redis主线程中执行,如果save时间太长会影响Redis的性能。
void saveCommand(client *c) {
// 如果已经有子进程在进行RDB持久化
if (server.child_type == CHILD_TYPE_RDB) {
addReplyError(c,"Background save already in progress");
return;
}
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
// 持久化
if (rdbSave(server.rdb_filename,rsiptr) == C_OK) {
addReply(c,shared.ok);
} else {
addReplyErrorObject(c,shared.err);
}
}
BGSAVE命令是通过执行rdbSaveBackground函数,可以看到rdbSave的调用时在子进程中。在BGSAVE执行期间,客户端发送的SAVE命令会被拒绝,禁止SAVE和BGSAVE同时执行,主要时为了防止主进程和子进程同时执行rdbSave,产生竞争;同理,也不能同时执行两个BGSAVE,也会产生竞争条件。
/* BGSAVE [SCHEDULE] */
void bgsaveCommand(client *c) {
int schedule = 0;
/* The SCHEDULE option changes the behavior of BGSAVE when an AOF rewrite
* is in progress. Instead of returning an error a BGSAVE gets scheduled. */
if (c->argc > 1) {
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"schedule")) {
schedule = 1;
} else {
addReplyErrorObject(c,shared.syntaxerr);
return;
}
}
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
if (server.child_type == CHILD_TYPE_RDB) {
addReplyError(c,"Background save already in progress");
} else if (hasActiveChildProcess()) {
if (schedule) {
server.rdb_bgsave_scheduled = 1;
addReplyStatus(c,"Background saving scheduled");
} else {
addReplyError(c,
"Another child process is active (AOF?): can't BGSAVE right now. "
"Use BGSAVE SCHEDULE in order to schedule a BGSAVE whenever "
"possible.");
}
} else if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK) {
addReplyStatus(c,"Background saving started");
} else {
addReplyErrorObject(c,shared.err);
}
}
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
// 子进程
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
sendChildCowInfo(CHILD_INFO_TYPE_RDB_COW_SIZE, "RDB");
}
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent */
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}
4.1.2 RDB文件的载入
Redis通过rdbLoad函数完成RDB文件的载入工作。Redis服务器在RDB的载入过程中会一直阻塞,直到完成加载。
int rdbLoad(char *filename, rdbSaveInfo *rsi, int rdbflags) {
FILE *fp;
rio rdb;
int retval;
if ((fp = fopen(filename,"r")) == NULL) return C_ERR;
startLoadingFile(fp, filename,rdbflags);
rioInitWithFile(&rdb,fp);
retval = rdbLoadRio(&rdb,rdbflags,rsi);
fclose(fp);
stopLoading(retval==C_OK);
return retval;
}
4.2 AOF持久化
4.2.1 AOF持久化实现
- AOF命令追加:当Redis服务器执行完一个写命令后,会将该命令以协议格式追加到aof_buf缓冲区的末尾
- AOF文件的写入和同步:Redis服务是单线程的,主要在一个事件循环(event loop)中循环。Redis中事件分为文件事件和时间事件,文件事件负责接收客户端的命令请求和给客户端回复数据,时间事件负责执行定时任务。在一次的事件循环结束之前,都会调用flushAppendOnlyFile函数,该函数会根据redis.conf配置文件中的持久化策略决定何时将aof_buf缓冲区中的命令数据写入的AOF文件。
4.2.2 源码分析
// src/server.h
/* Append only defines */
#define AOF_FSYNC_NO 0
#define AOF_FSYNC_ALWAYS 1
#define AOF_FSYNC_EVERYSEC 2
// src/aof.c
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
// 如果当前aof_buf缓冲区为空
if (sdslen(server.aof_buf) == 0) {
/* Check if we need to do fsync even the aof buffer is empty,
* because previously in AOF_FSYNC_EVERYSEC mode, fsync is
* called only when aof buffer is not empty, so if users
* stop write commands before fsync called in one second,
* the data in page cache cannot be flushed in time. */
if (server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.aof_fsync_offset != server.aof_current_size &&
server.unixtime > server.aof_last_fsync &&
!(sync_in_progress = aofFsyncInProgress())) {
goto try_fsync;
} else {
return;
}
}
if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
sync_in_progress = aofFsyncInProgress();
if (server.aof_fsync == AOF_FSYNC_EVERYSEC && !force) {
/* With this append fsync policy we do background fsyncing.
* If the fsync is still in progress we can try to delay
* the write for a couple of seconds. */
if (sync_in_progress) {
if (server.aof_flush_postponed_start == 0) {
/* No previous write postponing, remember that we are
* postponing the flush and return. */
server.aof_flush_postponed_start = server.unixtime;
return;
} else if (server.unixtime - server.aof_flush_postponed_start < 2) {
/* We were already waiting for fsync to finish, but for less
* than two seconds this is still ok. Postpone again. */
return;
}
/* Otherwise fall trough, and go write since we can't wait
* over two seconds. */
server.aof_delayed_fsync++;
serverLog(LL_NOTICE,"Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.");
}
}
/* We want to perform a single write. This should be guaranteed atomic
* at least if the filesystem we are writing is a real physical one.
* While this will save us against the server being killed I don't think
* there is much to do about the whole server stopping for power problems
* or alike */
if (server.aof_flush_sleep && sdslen(server.aof_buf)) {
usleep(server.aof_flush_sleep);
}
latencyStartMonitor(latency);
nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
latencyEndMonitor(latency);
/* We want to capture different events for delayed writes:
* when the delay happens with a pending fsync, or with a saving child
* active, and when the above two conditions are missing.
* We also use an additional event name to save all samples which is
* useful for graphing / monitoring purposes. */
if (sync_in_progress) {
latencyAddSampleIfNeeded("aof-write-pending-fsync",latency);
} else if (hasActiveChildProcess()) {
latencyAddSampleIfNeeded("aof-write-active-child",latency);
} else {
latencyAddSampleIfNeeded("aof-write-alone",latency);
}
latencyAddSampleIfNeeded("aof-write",latency);
/* We performed the write so reset the postponed flush sentinel to zero. */
server.aof_flush_postponed_start = 0;
if (nwritten != (ssize_t)sdslen(server.aof_buf)) {
static time_t last_write_error_log = 0;
int can_log = 0;
/* Limit logging rate to 1 line per AOF_WRITE_LOG_ERROR_RATE seconds. */
if ((server.unixtime - last_write_error_log) > AOF_WRITE_LOG_ERROR_RATE) {
can_log = 1;
last_write_error_log = server.unixtime;
}
/* Log the AOF write error and record the error code. */
if (nwritten == -1) {
if (can_log) {
serverLog(LL_WARNING,"Error writing to the AOF file: %s",
strerror(errno));
server.aof_last_write_errno = errno;
}
} else {
if (can_log) {
serverLog(LL_WARNING,"Short write while writing to "
"the AOF file: (nwritten=%lld, "
"expected=%lld)",
(long long)nwritten,
(long long)sdslen(server.aof_buf));
}
if (ftruncate(server.aof_fd, server.aof_current_size) == -1) {
if (can_log) {
serverLog(LL_WARNING, "Could not remove short write "
"from the append-only file. Redis may refuse "
"to load the AOF the next time it starts. "
"ftruncate: %s", strerror(errno));
}
} else {
/* If the ftruncate() succeeded we can set nwritten to
* -1 since there is no longer partial data into the AOF. */
nwritten = -1;
}
server.aof_last_write_errno = ENOSPC;
}
/* Handle the AOF write error. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* We can't recover when the fsync policy is ALWAYS since the reply
* for the client is already in the output buffers (both writes and
* reads), and the changes to the db can't be rolled back. Since we
* have a contract with the user that on acknowledged or observed
* writes are is synced on disk, we must exit. */
serverLog(LL_WARNING,"Can't recover from AOF write error when the AOF fsync policy is 'always'. Exiting...");
exit(1);
} else {
/* Recover from failed write leaving data into the buffer. However
* set an error to stop accepting writes as long as the error
* condition is not cleared. */
server.aof_last_write_status = C_ERR;
/* Trim the sds buffer if there was a partial write, and there
* was no way to undo it with ftruncate(2). */
if (nwritten > 0) {
server.aof_current_size += nwritten;
sdsrange(server.aof_buf,nwritten,-1);
}
return; /* We'll try again on the next call... */
}
} else {
/* Successful write(2). If AOF was in error state, restore the
* OK state and log the event. */
if (server.aof_last_write_status == C_ERR) {
serverLog(LL_WARNING,
"AOF write error looks solved, Redis can write again.");
server.aof_last_write_status = C_OK;
}
}
server.aof_current_size += nwritten;
/* Re-use AOF buffer when it is small enough. The maximum comes from the
* arena size of 4k minus some overhead (but is otherwise arbitrary). */
if ((sdslen(server.aof_buf)+sdsavail(server.aof_buf)) < 4000) {
sdsclear(server.aof_buf);
} else {
sdsfree(server.aof_buf);
server.aof_buf = sdsempty();
}
try_fsync:
/* Don't fsync if no-appendfsync-on-rewrite is set to yes and there are
* children doing I/O in the background. */
if (server.aof_no_fsync_on_rewrite && hasActiveChildProcess())
return;
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* redis_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
latencyStartMonitor(latency);
/* Let's try to get this data on the disk. To guarantee data safe when
* the AOF fsync policy is 'always', we should exit if failed to fsync
* AOF (see comment next to the exit(1) after write error above). */
if (redis_fsync(server.aof_fd) == -1) {
serverLog(LL_WARNING,"Can't persist AOF for fsync error when the "
"AOF fsync policy is 'always': %s. Exiting...", strerror(errno));
exit(1);
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_fsync_offset = server.aof_current_size;
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
if (!sync_in_progress) {
aof_background_fsync(server.aof_fd);
server.aof_fsync_offset = server.aof_current_size;
}
server.aof_last_fsync = server.unixtime;
}
}
到此这篇关于Redis中AOF与RDB持久化策略深入分析的文章就介绍到这了,更多相关Redis持久化策略内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Redis 持久化 RDB 与 AOF的执行过程
目录 前言 一.RDB 1. save 命令 2. bgsave 命令 3. 内部触发 RDB 场景 4. RDB 参数配置 5. RDB 缺点 二.AOF 1. 参数配置 2. AOF 执行流程 前言 Redis 持久化支持两种方式 RDB 与 AOF,文章记录两者的执行过程与配置. 一.RDB RDB 持久化是把当前进程数据生成快照保存到硬盘的过程,触发 RDB 持久化过程分为手动触发和自动触发. 1. save 命令 会堵塞当前 Redis 服务器,直到 RDB 结束为止,对数据量较大或者
-
Redis实现持久化的方式汇总
目录 Redis写入AOF日志的过程 Redis实现RDB快照 混合持久化 Redis有3种实现持久化的方式:AOF日志.RDB快照.混合持久化 Redis写入AOF日志的过程 Redis执行完写操作命令后,将命令追加到server.aof_buf缓冲区通过write()系统调用,将aof_buf缓冲区的数据写入到AOF文件数据被拷贝到了内核缓冲区page cache由内核决定何时将数据写入硬盘 Redis实现RDB快照 生成 RDB 文件的两个命令:save 和 bgsave 执行save命令
-
关于Redis数据库三种持久化方案介绍
目录 一.回顾Redis 二.方案一:bgsave 三.方案二:配置文件rdb 四.方案三:aof 总结 一.回顾Redis 1.redis的特点 redis是一个内存中的数据结构存储系统.优点:内存操作速度比硬盘很快.缺点:但是内存没有办法保存数据. 2.redis提供了磁盘持久化 通过磁盘持久化功能,就可以把内存中的数据,持久化到磁盘当中去.数据就可以长时间的进行保存. 二.方案一:bgsave 1.如何操作 启动redis-cli 客户端,输入一条数据,并输入持久化命令basave就可以完
-
Redis做数据持久化的解决方案及底层原理
目录 数据持久化 RDB 生成方法 save bgsave 优点 缺点 AOF AOF记录过程 ServerCron 作用 server.hz 写入策略 End 之前的文章介绍了Redis的简单数据结构的相关使用和底层原理,这篇文章我们就来聊一下Redis应该如何保证高可用. 数据持久化 我们知道虽然单机的Redis虽然性能十分的出色, 单机能够扛住10w的QPS,这是得益于其基于内存的快速读写操作,那如果某个时间Redis突然挂了怎么办?我们需要一种持久化的机制,来保存内存中的数据,否则数据就
-
一文详解Redis中的持久化
目录 1. 前言 2. RDB 2.1 手动触发 2.2 自动触发 3. bgsave大致流程 4. RDB持久化方式的优缺点 5. AOF 6. AOF的使用方式 7. AOF流程剖析 7.1 命令写入 7.2 文件同步 7.3 重写机制 7.4 重启加载 8. 问题定位与优化 8.1 关于fork操作 8.2 关于子进程开销 8.3 关于AOF追加阻塞 1. 前言 为什么要进行持久化?:持久化功能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复. 持久
-
Redis数据持久化方式技术解析
RDB(Redis DataBases) 1.RDB是什么: 在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是Snapshot快照,它恢复时是将快照文件直接读到内存里. Redis会单独创建(fork)一个子进程来进行持久化,会将数据写入到一个临时文件中,持久化过程都结束了,再用这个临时文件替换上次持久化好的文件.整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式是要比AOF方式更加的高效.RDB的
-
关于Redis数据持久化的概念介绍
目录 一.数据持久化的概述 1.RDB持久化 2.开启AOF 二 .RDB 和 AOF 的优缺点 1. RDB 持久化优缺点 2. AOF 持久化优缺点 一.数据持久化的概述 Redis是内存数据库,数据都是存储在内存中,为了避免服务器断电等原因导致Redis进程异常退出后数据的永久丢失,需要定期将Redis中的数据以某种形式(或命数据令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复.除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置(NFS) . Redis
-
Redis RDB与AOF持久化方式详细讲解
目录 1.RDB持久化 1.1 RDB文件的保存 1.2 RDB文件的载入 1.3 RDB持久化时服务器的状态 1.4 RDB持久化策略 2.AOF持久化 2.1 持久化的实现 2.2 文件的载入与数据还原 2.3 AOF文件的重写 1.RDB持久化 首先,RDB持久化方式会产生一个经过压缩的二进制文件,Redis服务器在启动之初,通过这个文件可以还原数据库的状态.那么我们接下来看下RDB文件是如何实现保存和载入的. 1.1 RDB文件的保存 RDB文件的保存有两个命令可以实现,分别是sav
-
Redis中AOF与RDB持久化策略深入分析
目录 写在前面 一.Redis为什么要持久化 二.Redis的持久化方式 2.1. AOF持久化(Append of file) 2.1.1 fsync 系统调用 2.1.2 AOF持久化策略 2.1.3 aof_rewrite 2.2 RDB快照(redis默认持久化方式) 触发方式(自动触发和非自动触发) 2.3 RDB和AOF混用 2.4 三种持久化方式比较 三.什么是大key以及大key对持久化的影响 3.1 什么是大key 3.2 fork进程写时复制原理 3.3 面试题-大key对持
-
Redis中键的过期删除策略深入讲解
如果一个键过期了,那么它什么时候会被删除呢? 这个问题有三种可能的答案,它们分别代表了三种不同的删除策略: 定时删除:在设置键的过期时间的同时,创建一个定时器( timer ). 让定时器在键的过期时间来临时,立即执行对键的删除操作. 惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键. 定期删除: 每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键.至于要删除多少过期键,以及要检查多少个数据库, 则由算法决定
-
Redis中的数据过期策略详解
1.Redis中key的的过期时间 通过EXPIRE key seconds命令来设置数据的过期时间.返回1表明设置成功,返回0表明key不存在或者不能成功设置过期时间.在key上设置了过期时间后key将在指定的秒数后被自动删除.被指定了过期时间的key在Redis中被称为是不稳定的. 当key被DEL命令删除或者被SET.GETSET命令重置后与之关联的过期时间会被清除 127.0.0.1:6379> setex s 20 1 OK 127.0.0.1:6379> ttl s (intege
-
浅谈Redis 中的过期删除策略和内存淘汰机制
目录 前言 Redis 中 key 的过期删除策略 1.定时删除 2.惰性删除 3.定期删除 Redis 中过期删除策略 从库是否会脏读主库创建的过期键 内存淘汰机制 内存淘汰触发的最大内存 有哪些内存淘汰策略 内存淘汰算法 LRU LFU 为什么数据删除后内存占用还是很高 内存碎片如何产生 碎片率的意义 如何清理内存碎片 总结 参考 前言 Redis 中的 key 设置一个过期时间,在过期时间到的时候,Redis 是如何清除这个 key 的呢? 这来分析下 Redis 中的过期删除策略和内存淘
-
浅谈Redis 中的过期删除策略和内存淘汰机制
目录 前言 Redis 中 key 的过期删除策略 1.定时删除 2.惰性删除 3.定期删除 Redis 中过期删除策略 从库是否会脏读主库创建的过期键 内存淘汰机制 内存淘汰触发的最大内存 有哪些内存淘汰策略 内存淘汰算法 LRU LFU 为什么数据删除后内存占用还是很高 内存碎片如何产生 碎片率的意义 如何清理内存碎片 总结 参考 前言 Redis 中的 key 设置一个过期时间,在过期时间到的时候,Redis 是如何清除这个 key 的呢? 这来分析下 Redis 中的过期删除策略和内存淘
-
Redis中过期键如何删除示例详解
目录 前言 Redis 中 key 的过期删除策略 1.定时删除 2.惰性删除 3.定期删除 Redis 中过期删除策略 从库是否会脏读主库创建的过期键 内存淘汰机制 内存淘汰触发的最大内存 有哪些内存淘汰策略 内存淘汰算法 LRU LFU 为什么数据删除后内存占用还是很高 内存碎片如何产生 碎片率的意义 如何清理内存碎片 总结 参考 前言 Redis 中的 key 设置一个过期时间,在过期时间到的时候,Redis 是如何清除这个 key 的呢? 这来分析下 Redis 中的过期删除策略和内存淘
-
Redis中LRU淘汰策略的深入分析
前言 Redis作为缓存使用时,一些场景下要考虑内存的空间消耗问题.Redis会删除过期键以释放空间,过期键的删除策略有两种: 惰性删除:每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键:如果没有过期,就返回该键. 定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键. 另外,Redis也可以开启LRU功能来自动淘汰一些键值对. LRU算法 当需要从缓存中淘汰数据时,我们希望能淘汰那些将来不可能再被使用的数据,保留那些将来还会频繁访问的数据,但最大的问题是
-
浅谈Redis中的RDB快照
一.概述 所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息就记录到了一张照片. 所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据. 因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 快些,因为直接将 RDB 文件读入内存就可以了,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据. 接下来,就来具体聊聊 RDB 快照 . 二.快照怎么用? 要熟悉一个东西,先
-
Redis 彻底禁用RDB持久化操作
Redis 禁用RDB持久化 Redis是默认开启RDB的,AOF则是默认关闭的.如果需要关闭RDB,将Redis完全作为一个缓存使用,需要修改配置项save. 开启save "", 将save 900 1.save 300 10.save 60 10000注释掉. 配置文件修改如下: save "" #save 900 1 #save 300 10 #save 60 10000 如果是中途关闭RDB持久化,还需要删除已经生成的文件dump.rdb.重启即可完全关闭