Android Dispatchers.IO线程池深入刨析
目录
- 一. Dispatchers.IO
- 1.Dispatchers.IO
- 2.DefaultScheduler类
- 3.LimitingDispatcher类
- 4.ExperimentalCoroutineDispatcher类
- 二.CoroutineScheduler类
- 1.CoroutineScheduler类的继承关系
- 2.CoroutineScheduler类的全局变量
- 三.Worker类与WorkerState类
- 1.WorkerState类
- 2.Worker类的继承关系与全局变量
- 3.Worker类的run方法
- 4.Worker类的任务寻找机制
- 5.Worker类的任务执行机制
- 四.CoroutineScheduler类的dispatch方法
- 五.浅谈WorkQueue类
- 1.add方法
- 2.任务偷取机制
- 六.总结
- 1.两个线程池
- 2.四种队列
- 3.尾调机制
- 4.任务分类与权限控制
- 5.任务偷取机制
- 6.执行梳理图
一. Dispatchers.IO
1.Dispatchers.IO
在协程中,当需要执行IO任务时,会在上下文中指定Dispatchers.IO来进行线程的切换调度。 而IO实际上是CoroutineDispatcher类型的对象,实际的值为DefaultScheduler类的常量对象IO,代码如下:
public actual object Dispatchers {
...
@JvmStatic
public val IO: CoroutineDispatcher = DefaultScheduler.IO
}
2.DefaultScheduler类
DefaultScheduler类继承自ExperimentalCoroutineDispatcher类,内部提供了类型为LimitingDispatcher的IO对象,代码如下:
// 系统配置变量
public const val IO_PARALLELISM_PROPERTY_NAME: String = "kotlinx.coroutines.io.parallelism"
...
// 表示不会阻塞的任务,纯CPU任务
internal const val TASK_NON_BLOCKING = 0
// 表示执行过程中可能会阻塞的任务,非纯CPU任务
internal const val TASK_PROBABLY_BLOCKING = 1
...
// 默认线程池名称
internal const val DEFAULT_DISPATCHER_NAME = "Dispatchers.Default"
...
internal object DefaultScheduler : ExperimentalCoroutineDispatcher() {
// 创建名为Dispatchers.IO的线程池
// 最大并发数量为kotlinx.coroutines.io.parallelism指定的值,默认为64与CPU数量中的较大者
// 默认的执行的任务类型为TASK_PROBABLY_BLOCKING
val IO: CoroutineDispatcher = LimitingDispatcher(
this,
systemProp(IO_PARALLELISM_PROPERTY_NAME, 64.coerceAtLeast(AVAILABLE_PROCESSORS)),
"Dispatchers.IO",
TASK_PROBABLY_BLOCKING
)
override fun close() {
throw UnsupportedOperationException("$DEFAULT_DISPATCHER_NAME cannot be closed")
}
// 可以看出IO和Default共用一个线程池
override fun toString(): String = DEFAULT_DISPATCHER_NAME
@InternalCoroutinesApi
@Suppress("UNUSED")
public fun toDebugString(): String = super.toString()
}
3.LimitingDispatcher类
LimitingDispatcher类继承自ExecutorCoroutineDispatcher类,实现了TaskContext接口和Executor接口。
LimitingDispatcher类的核心是构造方法中类型为ExperimentalCoroutineDispatcher的dispatcher对象。
LimitingDispatcher类看起来是一个标准的线程池,但实际上LimitingDispatcher类只对类参数中传入的dispatcher进行包装和功能扩展。如同名字中的litmit一样,LimitingDispatcher类主要用于对任务执行数量进行限制,代码如下:
// dispatcher参数传入了DefaultScheduler对象
// parallelism表示并发执行的任务数量
// name表示线程池的名字
// taskMode表示任务模式,TaskContext接口中的常量
private class LimitingDispatcher(
private val dispatcher: ExperimentalCoroutineDispatcher,
private val parallelism: Int,
private val name: String?,
override val taskMode: Int
) : ExecutorCoroutineDispatcher(), TaskContext, Executor {
// 用于保存任务的队列
private val queue = ConcurrentLinkedQueue<Runnable>()
// 用于记录当前正在执行的任务的数量
private val inFlightTasks = atomic(0)
// 获取当前线程池
override val executor: Executor
get() = this
// Executor接口的实现,线程池的核心方法,通过dispatch实现
override fun execute(command: Runnable) = dispatch(command, false)
override fun close(): Unit = error("Close cannot be invoked on LimitingBlockingDispatcher")
// CoroutineDispatcher接口的实现
override fun dispatch(context: CoroutineContext, block: Runnable) = dispatch(block, false)
// 任务分发的核心方法
private fun dispatch(block: Runnable, tailDispatch: Boolean) {
// 获取当前要执行的任务
var taskToSchedule = block
// 死循环
while (true) {
// 当前执行的任务数加一,也可理解生成生成当前要执行的任务的编号
val inFlight = inFlightTasks.incrementAndGet()
// 如果当前需要执行的任务数小于允许的并发执行任务数量,说明可以执行,
if (inFlight <= parallelism) {
// 调用参数中的dispatcher对象,执行任务
dispatcher.dispatchWithContext(taskToSchedule, this, tailDispatch)
// 返回,退出循环
return
}
// 如果达到的最大并发数的限制,则将任务加入到队列中
queue.add(taskToSchedule)
// 下面的代码防止线程竞争导致任务卡在队列里不被执行,case如下:
// 线程1:inFlightTasks = 1 ,执行任务
// 线程2:inFlightTasks = 2,当前达到了parallelism限制,
// 线程1:执行结束,inFlightTasks = 1
// 线程2:将任务添加到队列里,执行结束,inFlightTasks = 0
// 由于未执行,因此这里当前执行的任务数先减一
// 减一后如果仍然大于等于在大并发数,则直接返回,退出循环
if (inFlightTasks.decrementAndGet() >= parallelism) {
return
}
// 如果减一后,发现可以执行任务,则从队首获取任务,进行下一次循环
// 如果队列为空,说明没有任务,则返回,退出循环
taskToSchedule = queue.poll() ?: return
}
}
// CoroutineDispatcher接口的实现,用于yield挂起协程时的调度处理
override fun dispatchYield(context: CoroutineContext, block: Runnable) {
// 也是通过dispatch方法实现,注意这里tailDispatch参数为true
dispatch(block, tailDispatch = true)
}
override fun toString(): String {
return name ?: "${super.toString()}[dispatcher = $dispatcher]"
}
// TaskContext接口的实现,用于在一个任务执行完进行回调
override fun afterTask() {
// 从队首获取一个任务
var next = queue.poll()
// 若可以获取到
if (next != null) {
// 则执行任务,注意这里tailDispatch参数为true
dispatcher.dispatchWithContext(next, this, true)
// 返回
return
}
// 任务执行完毕,当前执行的任务数量减一
inFlightTasks.decrementAndGet()
// 下面的代码防止线程竞争导致任务卡在队列里不被执行,case如下:
// 线程1:inFlightTasks = 1 ,执行任务
// 线程2:inFlightTasks = 2
// 线程1:执行结束,执行afterTask方法,发现队列为空,此时inFlightTasks = 2
// 线程2:inFlightTasks当前达到了parallelism限制,
// 将任务加入到队列中,执行结束,inFlightTasks = 1
// 线程1:inFlightTasks=1,执行结束
// 从队列中取出任务,队列为空则返回
next = queue.poll() ?: return
// 执行任务,注意这里tailDispatch参数为true
dispatch(next, true)
}
}
dispatcher的dispatch方法定义在ExperimentalCoroutineDispatcher类中。
4.ExperimentalCoroutineDispatcher类
ExperimentalCoroutineDispatcher类继承自ExecutorCoroutineDispatcher类,代码如下:
// corePoolSize线程池核心线程数
// maxPoolSize表示线程池最大线程数
// schedulerName表示内部协程调度器的名字
// idleWorkerKeepAliveNs表示空闲的线程存活时间
@InternalCoroutinesApi
public open class ExperimentalCoroutineDispatcher(
private val corePoolSize: Int,
private val maxPoolSize: Int,
private val idleWorkerKeepAliveNs: Long,
private val schedulerName: String = "CoroutineScheduler"
) : ExecutorCoroutineDispatcher() {
// 我们在DefaultScheduler类中就是通过默认的构造方法,
// 创建的父类ExperimentalCoroutineDispatcher对象
public constructor(
corePoolSize: Int = CORE_POOL_SIZE,
maxPoolSize: Int = MAX_POOL_SIZE,
schedulerName: String = DEFAULT_SCHEDULER_NAME
) : this(corePoolSize, maxPoolSize, IDLE_WORKER_KEEP_ALIVE_NS, schedulerName)
...
// 创建coroutineScheduler对象
private var coroutineScheduler = createScheduler()
// 核心的分发方法
override fun dispatch(context: CoroutineContext, block: Runnable): Unit =
try {
// 调用coroutineScheduler对象的dispatch方法
coroutineScheduler.dispatch(block)
} catch (e: RejectedExecutionException) {
// 只有当coroutineScheduler正在关闭时,才会拒绝执行,抛出异常
DefaultExecutor.dispatch(context, block)
}
...
private fun createScheduler() = CoroutineScheduler(corePoolSize, maxPoolSize, idleWorkerKeepAliveNs, schedulerName)
...
}
// 核心线程数
@JvmField
internal val CORE_POOL_SIZE = systemProp(
"kotlinx.coroutines.scheduler.core.pool.size",
AVAILABLE_PROCESSORS.coerceAtLeast(2), // !!! at least two here
minValue = CoroutineScheduler.MIN_SUPPORTED_POOL_SIZE
)
// 最大线程数
@JvmField
internal val MAX_POOL_SIZE = systemProp(
"kotlinx.coroutines.scheduler.max.pool.size",
(AVAILABLE_PROCESSORS * 128).coerceIn(
CORE_POOL_SIZE,
CoroutineScheduler.MAX_SUPPORTED_POOL_SIZE
),
maxValue = CoroutineScheduler.MAX_SUPPORTED_POOL_SIZE
)
// 空闲线程的存活时间
@JvmField
internal val IDLE_WORKER_KEEP_ALIVE_NS = TimeUnit.SECONDS.toNanos(
systemProp("kotlinx.coroutines.scheduler.keep.alive.sec", 60L)
)
在ExperimentalCoroutineDispatcher类的dispatch方法内部,通过调用类型为CoroutineScheduler的对象的dispatch方法实现。
二.CoroutineScheduler类
1.CoroutineScheduler类的继承关系
在对CoroutineScheduler类的dispatch方法分析之前,首先分析一下CoroutineScheduler类的继承关系,代码如下:
// 实现了Executor和Closeable接口
// corePoolSize线程池核心线程数
// maxPoolSize表示线程池最大线程数
// schedulerName表示内部协程调度器的名字
// idleWorkerKeepAliveNs表示空闲的线程存活时间
internal class CoroutineScheduler(
@JvmField val corePoolSize: Int,
@JvmField val maxPoolSize: Int,
@JvmField val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
@JvmField val schedulerName: String = DEFAULT_SCHEDULER_NAME
) : Executor, Closeable {
init {
// 核心线程数量必须大于等于MIN_SUPPORTED_POOL_SIZE
require(corePoolSize >= MIN_SUPPORTED_POOL_SIZE) {
"Core pool size $corePoolSize should be at least $MIN_SUPPORTED_POOL_SIZE"
}
// 最大线程数量必须大于等于核心线程数量
require(maxPoolSize >= corePoolSize) {
"Max pool size $maxPoolSize should be greater than or equals to core pool size $corePoolSize"
}
// 最大线程数量必须小于等于MAX_SUPPORTED_POOL_SIZE
require(maxPoolSize <= MAX_SUPPORTED_POOL_SIZE) {
"Max pool size $maxPoolSize should not exceed maximal supported number of threads $MAX_SUPPORTED_POOL_SIZE"
}
// 空闲的线程存活时间必须大于0
require(idleWorkerKeepAliveNs > 0) {
"Idle worker keep alive time $idleWorkerKeepAliveNs must be positive"
}
}
...
// Executor接口中的实现,通过dispatch方法实现
override fun execute(command: Runnable) = dispatch(command)
// Closeable接口中的实现,通过shutdown方法实现
override fun close() = shutdown(10_000L)
...
}
2.CoroutineScheduler类的全局变量
接下来对CoroutineScheduler类中重要的全局变量进行分析,代码如下:
// 用于存储全局的纯CPU(不阻塞)任务
@JvmField
val globalCpuQueue = GlobalQueue()
// 用于存储全局的执行非纯CPU(可能阻塞)任务
@JvmField
val globalBlockingQueue = GlobalQueue()
...
// 用于记录当前处于Parked状态(一段时间后自动终止)的线程的数量
private val parkedWorkersStack = atomic(0L)
...
// 用于保存当前线程池中的线程
// workers[0]永远为null,作为哨兵位
// index从1到maxPoolSize为有效线程
@JvmField
val workers = AtomicReferenceArray<Worker?>(maxPoolSize + 1)
...
// 控制状态
private val controlState = atomic(corePoolSize.toLong() shl CPU_PERMITS_SHIFT)
// 表示已经创建的线程的数量
private val createdWorkers: Int inline get() = (controlState.value and CREATED_MASK).toInt()
// 表示可以获取的CPU令牌数量,初始值为线程池核心线程数量
private val availableCpuPermits: Int inline get() = availableCpuPermits(controlState.value)
// 获取指定的状态的已经创建的线程的数量
private inline fun createdWorkers(state: Long): Int = (state and CREATED_MASK).toInt()
// 获取指定的状态的执行阻塞任务的数量
private inline fun blockingTasks(state: Long): Int = (state and BLOCKING_MASK shr BLOCKING_SHIFT).toInt()
// 获取指定的状态的CPU令牌数量
public inline fun availableCpuPermits(state: Long): Int = (state and CPU_PERMITS_MASK shr CPU_PERMITS_SHIFT).toInt()
// 当前已经创建的线程数量加1
private inline fun incrementCreatedWorkers(): Int = createdWorkers(controlState.incrementAndGet())
// 当前已经创建的线程数量减1
private inline fun decrementCreatedWorkers(): Int = createdWorkers(controlState.getAndDecrement())
// 当前执行阻塞任务的线程数量加1
private inline fun incrementBlockingTasks() = controlState.addAndGet(1L shl BLOCKING_SHIFT)
// 当前执行阻塞任务的线程数量减1
private inline fun decrementBlockingTasks() {
controlState.addAndGet(-(1L shl BLOCKING_SHIFT))
}
// 尝试获取CPU令牌
private inline fun tryAcquireCpuPermit(): Boolean = controlState.loop { state ->
val available = availableCpuPermits(state)
if (available == 0) return false
val update = state - (1L shl CPU_PERMITS_SHIFT)
if (controlState.compareAndSet(state, update)) return true
}
// 释放CPU令牌
private inline fun releaseCpuPermit() = controlState.addAndGet(1L shl CPU_PERMITS_SHIFT)
// 表示当前线程池是否关闭
private val _isTerminated = atomic(false)
val isTerminated: Boolean get() = _isTerminated.value
companion object {
// 用于标记一个线程是否在parkedWorkersStack中(处于Parked状态)
@JvmField
val NOT_IN_STACK = Symbol("NOT_IN_STACK")
// 线程的三个状态
// CLAIMED表示线程可以执行任务
// PARKED表示线程暂停执行任务,一段时间后会自动进入终止状态
// TERMINATED表示线程处于终止状态
private const val PARKED = -1
private const val CLAIMED = 0
private const val TERMINATED = 1
// 以下五个常量为掩码
private const val BLOCKING_SHIFT = 21 // 2x1024x1024
// 1-21位
private const val CREATED_MASK: Long = (1L shl BLOCKING_SHIFT) - 1
// 22-42位
private const val BLOCKING_MASK: Long = CREATED_MASK shl BLOCKING_SHIFT
// 42
private const val CPU_PERMITS_SHIFT = BLOCKING_SHIFT * 2
// 43-63位
private const val CPU_PERMITS_MASK = CREATED_MASK shl CPU_PERMITS_SHIFT
// 以下两个常量用于require中参数判断
internal const val MIN_SUPPORTED_POOL_SIZE = 1
// 2x1024x1024-2
internal const val MAX_SUPPORTED_POOL_SIZE = (1 shl BLOCKING_SHIFT) - 2
// parkedWorkersStack的掩码
private const val PARKED_INDEX_MASK = CREATED_MASK
// inv表示01反转
private const val PARKED_VERSION_MASK = CREATED_MASK.inv()
private const val PARKED_VERSION_INC = 1L shl BLOCKING_SHIFT
}
CoroutineScheduler类中对线程的状态与权限控制:
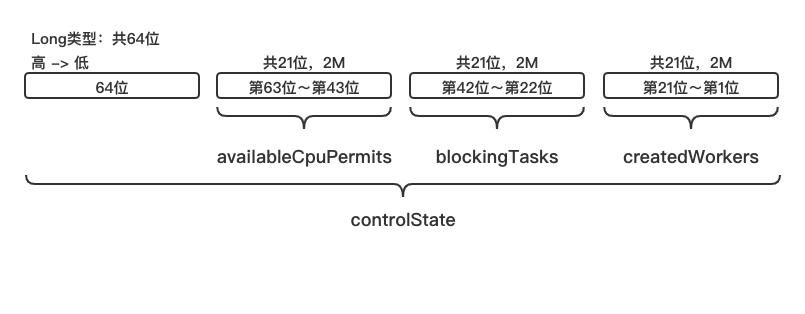
availableCpuPermits的初始值为参数中核心线程数corePoolSize的值,表示CoroutineScheduler类中最多只有corePoolSize个核心线程。执行纯CPU任务的线程每次执行任务之前需要在availableCpuPermits中进行记录与申请。blockingTasks表示执行非纯CPU任务的数量。这部分线程在执行时不需要CPU令牌。createdWorkers表示当前线程池中所有线程的数量,每个线程在创建或终止时都需要通过在这里进行记录。这些变量的具体关系如下:
createdWorkers = blockingTasks + corePoolSize - availableCpuPermits
CPU令牌是线程池自定义的概念,不代表时间片,只是为了保证核心线程的数量。
三.Worker类与WorkerState类
在分析CoroutineScheduler类的dispatch方法之前,还需要分析一下CoroutineScheduler类中的两个重要的内部类Worker类以及其对应的状态类WorkerState类。
Worker是一个线程池中任务的核心执行者,几乎在所有的线程池中都存在Worker的概念。
1.WorkerState类
首先分析一下WorkerState类,代码如下:
// 一个枚举类,表示Worker的状态
enum class WorkerState {
// 拥有了CPU令牌,可以执行纯CPU任务,也可以执行非纯CPU任务
CPU_ACQUIRED,
// 可以执行非纯CPU任务
BLOCKING,
// 当前已经暂停,一段时间后将终止,也有可能被再次使用
PARKING,
// 休眠状态,用于初始状态,只能执行自己本地任务
DORMANT,
// 终止状态,将不再被使用
TERMINATED
}
2.Worker类的继承关系与全局变量
接下来对Worker类的继承关系以及其中重要的全局变量进行分析,代码如下:
// 继承自Thread类
// 私有化无参的构造方法
internal inner class Worker private constructor() : Thread() {
init {
// 标记为守护线程
isDaemon = true
}
// 当前线程在存储线程池线程的数组workers中的索引位置
@Volatile
var indexInArray = 0
set(index) {
// 设置线程名
name = "$schedulerName-worker-${if (index == 0) "TERMINATED" else index.toString()}"
field = index
}
// 构造方法
constructor(index: Int) : this() {
indexInArray = index
}
// 获取当前线程的调度器
inline val scheduler get() = this@CoroutineScheduler
// 线程存储任务的本地队列
@JvmField
val localQueue: WorkQueue = WorkQueue()
// 线程的状态 (内部转换)
@JvmField
var state = WorkerState.DORMANT
// 线程的控制状态(外部赋予)
val workerCtl = atomic(CLAIMED)
// 终止截止时间,表示处于PARKING状态的线程,在terminationDeadline毫秒后终止
private var terminationDeadline = 0L
// 表示当线程处于PARKING状态,进入parkedWorkersStack后,
// 下一个处于PARKING状态并进入parkedWorkersStack的线程的引用
@Volatile
var nextParkedWorker: Any? = NOT_IN_STACK
// 偷取其他线程的本地队列的任务的冷却时间,后面会解释
private var minDelayUntilStealableTaskNs = 0L
// 生成随机数,配合算法,用于任务寻找
private var rngState = Random.nextInt()
...
// 表示当前线程的本地队列是否有任务
@JvmField
var mayHaveLocalTasks = false
...
}
3.Worker类的run方法
接下来分析Worker类的核心方法——run方法的实现,代码入下:
override fun run() = runWorker()
private fun runWorker() {
// 用于配合minDelayUntilStealableTaskNs自旋
var rescanned = false
// 线程池未关闭,线程没有终止,则循环
while (!isTerminated && state != WorkerState.TERMINATED) {
// 寻找并获取任务
val task = findTask(mayHaveLocalTasks)
// 如果找到了任务
if (task != null) {
// 重制两个变量
rescanned = false
minDelayUntilStealableTaskNs = 0L
// 执行任务
executeTask(task)
// 继续循环
continue
} else { // 如果没有找到任务,说明本地队列肯定没有任务,因为本地队列优先查找
// 设置标志位
mayHaveLocalTasks = false
}
// 走到这里,说明没有找到任务
// 如果偷取任务的冷却时间不为0,说明之前偷到过任务
if (minDelayUntilStealableTaskNs != 0L) {
// 这里通过rescanned,首次minDelayUntilStealableTaskNs不为0,
// 不会立刻进入PARKING状态,而是再次去寻找任务
// 因为当过多的线程进入PARKING状态,再次唤起大量的线程很难控制
if (!rescanned) {
rescanned = true
} else {// 再次扫描,仍然没有找到任务
// 置位
rescanned = false
// 尝试释放CPU令牌,并进入WorkerState.PARKING状态
tryReleaseCpu(WorkerState.PARKING)
// 清除中断标志位
interrupted()
// 阻塞minDelayUntilStealableTaskNs毫秒
LockSupport.parkNanos(minDelayUntilStealableTaskNs)
// 清零
minDelayUntilStealableTaskNs = 0L
}
// 阻塞完成后继续执行
continue
}
// 走到这里,说明线程可能很长时间都没有执行任务了,则对其进行暂停处理
// tryPark比tryReleaseCpu要严格的多,会被线程会被计入到parkedWorkersStack,
// 同时会修改workerCtl状态
tryPark()
}
// 退出循环
// 尝试释放CPU令牌,并进入终止状态
tryReleaseCpu(WorkerState.TERMINATED)
}
4.Worker类的任务寻找机制
接下来分析Worker线程如何寻找任务,代码如下:
// 寻找任务
fun findTask(scanLocalQueue: Boolean): Task? {
// 尝试获取CPU令牌,如果获取到了,则调用findAnyTask方法,寻找任务
if (tryAcquireCpuPermit()) return findAnyTask(scanLocalQueue)
// 如果没有获取到CPU令牌,只能去找非纯CPU任务了
// 如果允许扫描本地的任务队列,则优先在本地队列中寻找,
// 找不到则在全局队列中寻找,从队首中获取
val task = if (scanLocalQueue) {
localQueue.poll() ?: globalBlockingQueue.removeFirstOrNull()
} else {
globalBlockingQueue.removeFirstOrNull()
}
// 如果在本地队列和全局队列中都找不到,则尝试去其他线程的队列里偷一个任务
return task ?: trySteal(blockingOnly = true)
}
// 寻找CPU任务
private fun findAnyTask(scanLocalQueue: Boolean): Task? {
// 如果允许扫描本地的任务队列,则在本地队列和全局队列中随机二选一,
// 找不到则在全局队列中寻找,从队首中获取
if (scanLocalQueue) {
// 随机确定本地队列和全局队列的优先顺序
val globalFirst = nextInt(2 * corePoolSize) == 0
// 获取任务
if (globalFirst) pollGlobalQueues()?.let { return it }
localQueue.poll()?.let { return it }
if (!globalFirst) pollGlobalQueues()?.let { return it }
} else {
// 只能从全局获取
pollGlobalQueues()?.let { return it }
}
// 走到这里,说明本地队列和全局队列中都找不到
// 那么就尝试去其他线程的队列里偷一个任务
return trySteal(blockingOnly = false)
}
// 从全局队列获取任务
private fun pollGlobalQueues(): Task? {
// 随机获取CPU任务或者非CPU任务
if (nextInt(2) == 0) {
// 优先获取CPU任务
globalCpuQueue.removeFirstOrNull()?.let { return it }
return globalBlockingQueue.removeFirstOrNull()
} else {
// 优先获取非CPU任务
globalBlockingQueue.removeFirstOrNull()?.let { return it }
return globalCpuQueue.removeFirstOrNull()
}
}
// 偷取其他线程的本地队列的任务
// blockingOnly表示是否只偷取阻塞任务
private fun trySteal(blockingOnly: Boolean): Task? {
// 只有当前线程的本地队列为空的时候,才能偷其他线程的本地队列
assert { localQueue.size == 0 }
// 获取已经存在的线程的数量
val created = createdWorkers
// 如果线程总数为0或1,则不偷取,直接返回
// 0:需要等待初始化
// 1:避免在单线程机器上过度偷取
if (created < 2) {
return null
}
// 随机生成一个存在的线程索引
var currentIndex = nextInt(created)
// 默认的偷取冷却时间
var minDelay = Long.MAX_VALUE
// 循环遍历
repeat(created) {
// 每次循环索引自增,带着下一行代码表示,从位置currentIndex开始偷
++currentIndex
// 如果超出了,则从头继续
if (currentIndex > created) currentIndex = 1
// 从数组中获取线程
val worker = workers[currentIndex]
// 如果线程不为空,并且不是自己
if (worker !== null && worker !== this) {
assert { localQueue.size == 0 }
// 根据偷取的类型进行偷取
val stealResult = if (blockingOnly) {
// 偷取非CPU任务到本地队列中
localQueue.tryStealBlockingFrom(victim = worker.localQueue)
} else {
// 偷取任务到本地队列中
localQueue.tryStealFrom(victim = worker.localQueue)
}
// 如果返回值为TASK_STOLEN,说明偷到了
// 如果返回值为NOTHING_TO_STEAL,说明要偷的线程的本地队列是空的
if (stealResult == TASK_STOLEN) {
// 从队列的队首拿出来返回
return localQueue.poll()
// 如果返回值大于零,表示偷取的冷却时间,说明没有偷到
} else if (stealResult > 0) { // 说明至少还要等待stealResult时间才能偷取这个任务
// 计算偷取冷却时间
minDelay = min(minDelay, stealResult)
}
}
}
// 设置偷取等待时间
minDelayUntilStealableTaskNs = if (minDelay != Long.MAX_VALUE) minDelay else 0
// 返回空
return null
}
// 基于Marsaglia xorshift RNG算法
// 用于在2^32-1范围内计算偷取目标
internal fun nextInt(upperBound: Int): Int {
var r = rngState
r = r xor (r shl 13)
r = r xor (r shr 17)
r = r xor (r shl 5)
rngState = r
val mask = upperBound - 1
// Fast path for power of two bound
if (mask and upperBound == 0) {
return r and mask
}
return (r and Int.MAX_VALUE) % upperBound
}
通过对这部分代码的分析,可以知道线程在寻找任务时,首先会尝试获取CPU令牌,成为核心线程。如果线程成为了核心线程,则随机从本地或全局的两个队列中获取一个任务,获取不到则去随机偷取一个任务。如果没有获取到CPU令牌,则优先在本地获取任务,获取不到则在全局非CPU任务队列中获取任务,获取不到则去偷取一个非CPU任务。
如果偷取的任务没有达到最小的可偷取时间,则返回需要等待的时间。如果偷取任务成功,则直接加入到本地队列中。偷取的核心过程,会在后面进行分析。
5.Worker类的任务执行机制
接下来分析任务被获取到后如何被执行,代码如下:
// 执行任务
private fun executeTask(task: Task) {
// 获取任务类型,类型为纯CPU或可能阻塞
val taskMode = task.mode
// 重置线程闲置状态
idleReset(taskMode)
// 任务执行前
beforeTask(taskMode)
// 执行任务
runSafely(task)
// 任务执行后
afterTask(taskMode)
}
// 重置线程闲置状态
private fun idleReset(mode: Int) {
// 重置从PARKING状态到TERMINATED状态的时间
terminationDeadline = 0L
// 如果当前状态为PARKING,说明寻找任务时没有获取到CPU令牌
if (state == WorkerState.PARKING) {
assert { mode == TASK_PROBABLY_BLOCKING }
// 设置状态为BLOCKING
state = WorkerState.BLOCKING
}
}
// 任务执行前
private fun beforeTask(taskMode: Int) {
// 如果执行的任务为纯CPU任务,说明当前线程获取到了CPU令牌,是核心线程,直接返回
if (taskMode == TASK_NON_BLOCKING) return
// 走到这里,说明线程执行的是非纯CPU任务,
// 没有CPU令牌也可以执行,因此尝试释放CPU令牌,进入WorkerState.BLOCKING
if (tryReleaseCpu(WorkerState.BLOCKING)) {
// 如果释放CPU令牌成功,则唤起一个线程去申请CPU令牌
signalCpuWork()
}
}
// 执行任务
fun runSafely(task: Task) {
try {
task.run()
} catch (e: Throwable) {
// 异常发生时,通知当前线程的异常处理Handler
val thread = Thread.currentThread()
thread.uncaughtExceptionHandler.uncaughtException(thread, e)
} finally {
unTrackTask()
}
}
// 任务执行后
private fun afterTask(taskMode: Int) {
// 如果执行的任务为纯CPU任务,说明当前线程获取到了CPU令牌,是核心线程,直接返回
if (taskMode == TASK_NON_BLOCKING) return
// 如果执行的是非CPU任务
// 当前执行的非CPU任务数量减一
decrementBlockingTasks()
// 获取当前线程状态
val currentState = state
// 如果线程当前不是终止状态
if (currentState !== WorkerState.TERMINATED) {
assert { currentState == WorkerState.BLOCKING }
// 设置为休眠状态
state = WorkerState.DORMANT
}
}
四.CoroutineScheduler类的dispatch方法
了解Worker类的工作机制后,接下来分析CoroutineScheduler类的dispatch方法,代码如下:
// block表示要执行的任务
// taskContext表示任务执行的上下文,里面包含任务的类型,和执行完成后的回调
// tailDispatch表示当前任务是否进行队列尾部调度,
// 当tailDispatch为true时,当前block会在当前线程的本地队列里的任务全部执行完后再执行
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
// 上报时间,TimeSource相关,无需关注
trackTask()
// 创建任务
val task = createTask(block, taskContext)
// 获取当前的Worker,可能获取不到
val currentWorker = currentWorker()
// 将当前的任务添加到当前线程的本地队列中
val notAdded = currentWorker.submitToLocalQueue(task, tailDispatch)
// 不为空,说明没有添加进去,说明当前的线程不是Worker
if (notAdded != null) {
// 将任务添加到全局队列中,如果添加失败了
if (!addToGlobalQueue(notAdded)) {
// 说明线程池正在关闭,抛出异常
throw RejectedExecutionException("$schedulerName was terminated")
}
}
// skipUnpark表示是否跳过唤起状态,取决于这下面两个参数
val skipUnpark = tailDispatch && currentWorker != null
// 如果当前类型为纯CPU任务
if (task.mode == TASK_NON_BLOCKING) {
// 如果跳过唤醒,则直接返回
if (skipUnpark) return
// 唤醒一个执行纯CPU任务的线程
signalCpuWork()
} else {
// 唤醒一个执行非CPU任务的线程
signalBlockingWork(skipUnpark = skipUnpark)
}
}
// 创建任务
internal fun createTask(block: Runnable, taskContext: TaskContext): Task {
// 获取当前时间
val nanoTime = schedulerTimeSource.nanoTime()
// 如果当前的block是Task类型的
if (block is Task) {
// 重新设置提交时间和任务上下文
block.submissionTime = nanoTime
block.taskContext = taskContext
// 返回
return block
}
// 封装成TaskImpl,返回
return TaskImpl(block, nanoTime, taskContext)
}
// 任务模型
// block表示执行的任务
// submissionTime表示任务提交时间
// taskContext表示任务执行的上下文
internal class TaskImpl(
@JvmField val block: Runnable,
submissionTime: Long,
taskContext: TaskContext
) : Task(submissionTime, taskContext) {
override fun run() {
try {
block.run()
} finally {
// 任务执行完毕后,会在同一个Worker线程中回调afterTask方法
taskContext.afterTask()
}
}
override fun toString(): String =
"Task[${block.classSimpleName}@${block.hexAddress}, $submissionTime, $taskContext]"
}
// 将任务添加到本地队列
private fun Worker?.submitToLocalQueue(task: Task, tailDispatch: Boolean): Task? {
// 如果当前线程为空,则返回任务
if (this == null) return task
// 如果线程处于终止状态,则返回任务
if (state === WorkerState.TERMINATED) return task
// 如果任务为纯CPU任务,但是线程没有CPU令牌
if (task.mode == TASK_NON_BLOCKING && state === WorkerState.BLOCKING) {
// 则返回任务
return task
}
// 标记本地队列有任务
mayHaveLocalTasks = true
// 添加到队列
return localQueue.add(task, fair = tailDispatch)
}
// 添加到全局队列
private fun addToGlobalQueue(task: Task): Boolean {
// 根据任务的类型,添加到全局队列的队尾
return if (task.isBlocking) {
globalBlockingQueue.addLast(task)
} else {
globalCpuQueue.addLast(task)
}
}
// 对当前线程进行强制转换,如果调度器也是当前的调度器则返回Worker对象
private fun currentWorker(): Worker? = (Thread.currentThread() as? Worker)?.takeIf { it.scheduler == this }
// 唤起一个执行非纯CPU任务的线程
private fun signalBlockingWork(skipUnpark: Boolean) {
// 当前执行阻塞任务的线程数量加1,并获取当前的控制状态
val stateSnapshot = incrementBlockingTasks()
// 如果跳过唤起,则返回
if (skipUnpark) return
// 尝试唤起,唤起成功,则返回
if (tryUnpark()) return
// 唤起失败,则根据当前的控制状态,尝试创建新线程,成功则返回
if (tryCreateWorker(stateSnapshot)) return
// 再次尝试唤起,防止多线程竞争情况下,上面的tryUnpark方法正好卡在线程释放CPU令牌与进入PARKING状态之间
// 因为线程先释放CPU令牌,后进入PARKING状态
tryUnpark()
}
// 唤起一个执行纯CPU任务的线程
internal fun signalCpuWork() {
// 尝试唤起,唤起成功,则返回
if (tryUnpark()) return
// 唤起失败,则尝试创建新线程,成功则返回
if (tryCreateWorker()) return
// 再次尝试唤起,防止多线程竞争情况下,上面的tryUnpark方法正好卡在线程释放CPU令牌与进入PARKING状态之间
// 因为线程先释放CPU令牌,后进入PARKING状态
tryUnpark()
}
通过对上面的代码进行分析,可以知道CoroutineScheduler类的dispatch方法,首先会对任务进行封装。正常情况下,任务都会根据类型添加到全局队列中,接着根据任务类型,随机唤起一个执行对应类型任务的线程去执行任务。
当任务执行完毕后,会回调任务中自带的afterTask方法。根据之前对LimitingDispatcher的分析,可以知道,此时tailDispatch参数为true,同时当前的线程也是Worker线程,因此会被直接添加到线程的本地队列中,由于任务有对应的线程执行,因此跳过了唤起其他线程执行任务的阶段。这里我们可以称这个机制为尾调机制。
为什么CoroutineScheduler类中要设计一个尾调机制呢?
在传统的线程池的线程充足情况下,一个任务到来时,会被分配一个线程。假设前后两个任务A与B有依赖关系,需要在执行A再执行B,这时如果两个任务同时到来,执行A任务的线程会直接执行,而执行B线程的任务可能需要被阻塞。而一旦线程阻塞会造成线程资源的浪费。而协程本质上就是多个小段程序的相互协作,因此这种场景会非常多,通过这种机制可以保证任务的执行顺序,同时减少资源浪费,而且可以最大限度的保证一个连续的任务执行在同一个线程中。
至此,Dispatchers.IO线程池的工作原理全部分析完毕。
五.浅谈WorkQueue类
1.add方法
接下来分析一些更加细节的过程。首先分析一下Worker线程本地队列调用的add方法是如何添加任务的,代码如下:
// 本地队列中存储最后一次尾调的任务
private val lastScheduledTask = atomic<Task?>(null)
// fair表示是否公平的执行任务,FIFO,默认为false
fun add(task: Task, fair: Boolean = false): Task? {
// fair为true,则添加到队尾
if (fair) return addLast(task)
// 如果fair为false,则从lastScheduledTask中取出上一个尾调的任务,
// 并把这次的新尾调任务保存到lastScheduledTask
val previous = lastScheduledTask.getAndSet(task) ?: return null
// 如果获取上一次的尾调任务不为空,则添加到队尾
return addLast(previous)
}
2.任务偷取机制
根据之前对Worker类的分析,任务偷取的核心代码锁定在了WorkQueue类的两个方法上:一个是偷取非纯CPU任务的tryStealBlockingFrom方法,另一个可以偷所有类型任务的tryStealFrom方法,代码如下:
internal const val BUFFER_CAPACITY_BASE = 7
internal const val BUFFER_CAPACITY = 1 shl BUFFER_CAPACITY_BASE // 1000 0000
internal const val MASK = BUFFER_CAPACITY - 1 // 0111 1111
// 存储任务的数组,最多存储128
private val buffer: AtomicReferenceArray<Task?> = AtomicReferenceArray(BUFFER_CAPACITY)
// producerIndex表示上一次向任务数组中添加任务的索引
// consumerIndex表示上一次消费的任务索引
// producerIndex永远大于等于consumerIndex
// 二者差值就是当前任务数组中任务的数量
private val producerIndex = atomic(0)
private val consumerIndex = atomic(0)
// buffer中非纯CPU任务的数量(避免遍历扫描)
private val blockingTasksInBuffer = atomic(0)
// 偷所有类型任务
fun tryStealFrom(victim: WorkQueue): Long {
assert { bufferSize == 0 }
// 从要偷取线程的本地队列中轮训获取一个任务
val task = victim.pollBuffer()
// 如果获取到了任务
if (task != null) {
// 将它添加到自己的本地队列中
val notAdded = add(task)
assert { notAdded == null }
// 返回偷取成功的标识
return TASK_STOLEN
}
// 如果偷取失败,尝试偷取指定线程的尾调任务
return tryStealLastScheduled(victim, blockingOnly = false)
}
// 轮训获取任务
private fun pollBuffer(): Task? {
// 死循环
while (true) {
// 获取上一次消费的任务索引
val tailLocal = consumerIndex.value
// 如果当前任务数组中没有多处的任务,则返回空
if (tailLocal - producerIndex.value == 0) return null
// 计算偷取位置,防止数组过界
val index = tailLocal and MASK
// 通过CAS方式,将consumerIndex加一,表示下一次要从tailLocal + 1处开始偷取
if (consumerIndex.compareAndSet(tailLocal, tailLocal + 1)) {
// 从偷取位置初取出任务,如果偷取的任务为空,则继续循环
val value = buffer.getAndSet(index, null) ?: continue
// 偷取成功
// 若任务为阻塞任务,blockingTasksInBuffer的值减一
value.decrementIfBlocking()
// 返回任务
return value
}
}
}
// 偷取非纯CPU任务
fun tryStealBlockingFrom(victim: WorkQueue): Long {
assert { bufferSize == 0 }
// 从consumerIndex位置开始偷
var start = victim.consumerIndex.value
// 偷到producerIndex处截止
val end = victim.producerIndex.value
// 获取任务数组
val buffer = victim.buffer
// 循环偷取
while (start != end) {
// 计算偷取位置,防止数组过界
val index = start and MASK
// 如果非纯CPU任务数为0,则直接退出循环
if (victim.blockingTasksInBuffer.value == 0) break
// 获取index处的任务
val value = buffer[index]
// 如果任务存在,而且是非纯CPU任务,同时成功的通过CAS设置为空
if (value != null && value.isBlocking && buffer.compareAndSet(index, value, null)) {
// blockingTasksInBuffer的值减一
victim.blockingTasksInBuffer.decrementAndGet()
// 将偷取的任务添加到当前线程的本地队列中
add(value)
// 返回偷取成功标识
return TASK_STOLEN
} else {
// 如果偷取失败,自增再次循环,从下一个位置开始偷
++start
}
}
// 如果从任务数组中偷取失败,尝试偷取指定线程的尾调任务
return tryStealLastScheduled(victim, blockingOnly = true)
}
// 偷取指定线程的尾调任务
private fun tryStealLastScheduled(victim: WorkQueue, blockingOnly: Boolean): Long {
// 死循环
while (true) {
// 获取指定线程的尾调任务,如果任务不存在,则返回偷取失败标识符
val lastScheduled = victim.lastScheduledTask.value ?: return NOTHING_TO_STEAL
// 如果要偷取的是非纯CPU任务,但是任务类型为纯CPU任务,说明只有核心线程才能偷
// 返回偷取失败标识符
if (blockingOnly && !lastScheduled.isBlocking) return NOTHING_TO_STEAL
// 获取当前时间
val time = schedulerTimeSource.nanoTime()
//计算任务从添加开始到现在经过的时长
val staleness = time - lastScheduled.submissionTime
// 如果时长小于偷取冷却时间
if (staleness < WORK_STEALING_TIME_RESOLUTION_NS) {
// 返回当前线程需要等待的时间
return WORK_STEALING_TIME_RESOLUTION_NS - staleness
}
// 通过CAS,将lastScheduledTask设置为空,防止被其他线程执行
if (victim.lastScheduledTask.compareAndSet(lastScheduled, null)) {
// 偷取成功,加入到当前线程的队列中
add(lastScheduled)
// 返回偷取成功表示
return TASK_STOLEN
}
// 继续循环
continue
}
}
// 偷取冷却时间,尾调任务从添加开始,
// 最少经过WORK_STEALING_TIME_RESOLUTION_NS时间才可以被偷
@JvmField
internal val WORK_STEALING_TIME_RESOLUTION_NS = systemProp(
"kotlinx.coroutines.scheduler.resolution.ns", 100000L
)
六.总结
1.两个线程池
CoroutineScheduler类是核心的线程池,用于任务的执行。LimitingDispatcher类对CoroutineScheduler类进行代理,是CoroutineScheduler类尾调机制的使用者,对任务进行初步排队。
2.四种队列
LimitingDispatcher类中的任务队列。CoroutineScheduler类中的两个全局队列。Worker类中的本地队列。
3.尾调机制
一个任务执行完,可以通过回调,在同一个Worker线程中再存储一个待执行任务,该任务将在Worker线程本地队列目前已存在的任务,执行完毕后再执行。
4.任务分类与权限控制
所有任务分成纯CPU任务和非纯CPU任务两种,对应着核心线程和非核心线程。
所有线程在执行前都先尝试成为核心线程,核心线程可以从两种任务中任意选择执行,非核心线程只能执行非纯CPU任务。核心线程如果选择执行非纯CPU任务会变成非核心线程
5.任务偷取机制
WorkQueue类根据随机算法提供任务偷取机制,一个Worker线程可以从其他Worker线程的本地队列中偷取任务。
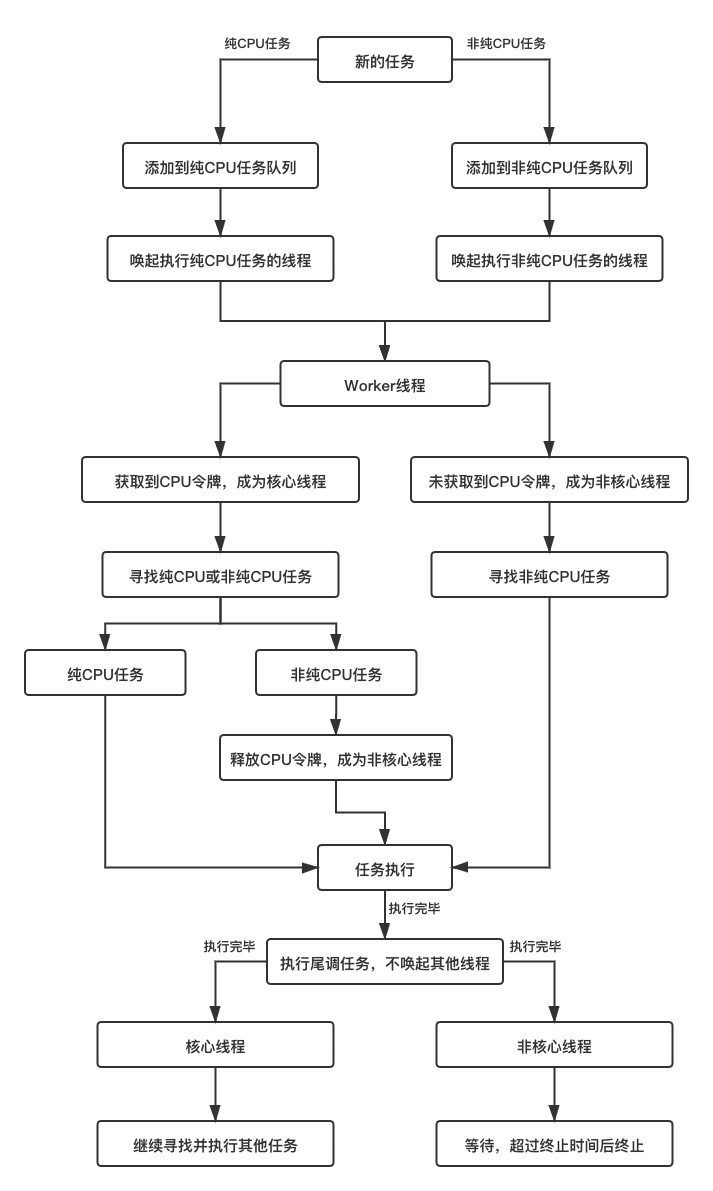
6.执行梳理图
到此这篇关于Android Dispatchers.IO线程池深入刨析的文章就介绍到这了,更多相关Android Dispatchers.IO内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈Android 的线程和线程池的使用
Android 的线程和线程池 从用途上分,线程分为主线程和子线程:主线程主要处理和界面相关的事情,子线程则往往用于耗时操作. 主线程和子线程 主线程是指进程所拥有的线程.Android 中主线程交 UI 线程,主要作用是运行四大组件以及处理它们和用户的交互:子线程的作业则是执行耗时任务. Android 中的线程形态 1.AsyncTask AsyncTask 是一种轻量级的异步任务类,可以在线程池中执行后台任务,然后把执行的进度和最终结果传递给主线程并在主线程中更新 UI, AsyncTas
-

Android开发中线程池源码解析
线程池(英语:thread pool):一种线程使用模式.线程过多会带来调度开销,进而影响缓存局部性和整体性能.而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务.这避免了在处理短时间任务时创建与销毁线程的代价.线程池不仅能够保证内核的充分利用,还能防止过分调度.可用线程数量应该取决于可用的并发处理器.处理器内核.内存.网络sockets等的数量. 例如,线程数一般取cpu数量+2比较合适,线程数过多会导致额外的线程切换开销.----摘自维基百科 我们在Android或者Java开发中
-
分析Android中线程和线程池
目录 前言 HandlerThread IntentService 线程池的好处 ThreadPoolExecutor 线程池的分类 FixedThreadPool CachedThreadPool ScheduledThreadPool SingleThreadExecutor 前言 由于内容过多,所以将分为上下两部分,第一部分主要和大家谈谈Android中的线程,以及在Android中的常用的线程池.第二部分我们一起来了解一下AsyncTask的使用和工作原理. HandlerThread
-
Android线程池控制并发数多线程下载
多线程下载并不是并发下载线程越多越好,因为当用户开启太多的并发线程之后,应用程序需要维护每条线程的开销,线程同步的开销. 这些开销反而会导致下载速度降低.因此需要避免在代码中直接开启大量线程执行下载. 主要实现步奏: 1.定义一个DownUtil类,下载工作基本在此类完成,在构造器中初始化UI线程的Handler.用于子线程和UI线程传递下载进度值. 2.所有的下载任务都保存在LinkedList.在init()方法中开启一个后台线程,不断地从LinkedList中取任务交给线程池中的空闲线程执
-
浅谈Android中线程池的管理
说到线程就要说说线程机制 Handler,Looper,MessageQueue 可以说是三座大山了 Handler Handler 其实就是一个处理者,或者说一个发送者,它会把消息发送给消息队列,也就是Looper,然后在一个无限循环队列中进行取出消息的操作 mMyHandler.sendMessage(mMessage); 这句话就是我耗时操作处理完了,我发送过去了! 然后在接受的地方处理!简单理解是不是很简单. 一般我们在项目中异步操作都是怎么做的呢? // 这里开启一个子线程进行耗时操作
-
Android线程池源码阅读记录介绍
今天面试被问到线程池如何复用线程的?当场就懵掉了...于是面试完毕就赶紧打开源码看了看,在此记录下: 我们都知道线程池的用法,一般就是先new一个ThreadPoolExecutor对象,再调用execute(Runnable runnable)传入我们的Runnable,剩下的交给线程池处理就行了,于是这次我就从ThreadPoolExecutor的execute方法看起: public void execute(Runnable command) { if (command == null)
-
Android之线程池ThreadPoolExecutor的简介
Android中的线程池ThreadPoolExecutor解决了单线程下载数据的效率慢和线程阻塞的的问题,它的应用也是优化实现的方式.所以它的重要性不言而喻,但是它的复杂性也大,理解上可能会有问题,不过作为安卓工程师,了解这个也是必然的. ThreadPoolExecutor有几个构造函数,最多参数的构造函数最常用,下面会详细介绍各个参数的含义及其几个参数之间的关系: <span style="font-size:18px;">ThreadPoolExecutor(cor
-
Android Dispatchers.IO线程池深入刨析
目录 一. Dispatchers.IO 1.Dispatchers.IO 2.DefaultScheduler类 3.LimitingDispatcher类 4.ExperimentalCoroutineDispatcher类 二.CoroutineScheduler类 1.CoroutineScheduler类的继承关系 2.CoroutineScheduler类的全局变量 三.Worker类与WorkerState类 1.WorkerState类 2.Worker类的继承关系与全局变量 3
-
Android Activity启动流程刨析
目录 前言 一.Binder的基本理解 二.Activity启动的双向IPC过程 三.AMS服务注册 前言 上篇文章写到 Service 的启动过程: 相对来说Activity的启动过程比Service的启动过程更为复杂,其一Activity的生命周期方法比Service多,其二Activity具有启动模式和返回栈: 写本文的目的在于更清晰的梳理Activity的启动过程,加强自己的内功修炼,力在以最简单的方式让大家理解,跟大家一起学习 一.Binder的基本理解 Activity的启动有多次I
-
Android Service启动流程刨析
强调一下阅读系统源码,起码要对进程间通信要了解,对binder机制非常非常清楚,binder就是指南针,要不然你会晕头转向:强行阅读,就容易睡着. Service启动先来一张图感受一下 这张图能够说明一个大致的流程,但是服务的启动肯定不是这么简单,但是我们先简单的总结一下,逐渐深入.服务的启动形式有两种,startService()和 binderService(),我们看startService()这一种.startService是ContextWrapper里面的方法. ContextWra
-
Android Activity View加载与绘制流程深入刨析源码
1.App的启动流程,从startActivity到Activity被创建. 这个流程主要是ActivityThread和ActivityManagerService之间通过binder进行通信来完成. ActivityThread可以拿到AMS 的BinderProxy.AMS可以拿到ActivityThread的BinderProxy ApplicationThread.这样双方就可以互相通讯了. 当ApplicationThread 接收到AMS的Binder调用后,会通过handler机
-
Android广播事件流程与广播ANR原理深入刨析
目录 序言 一.基本流程和概念 二.无序广播流程 注册广播接收者流程 广播通知流程 三.有序广播流程 四.广播ANR流程 五.总结 六.扩展问题 序言 本想写广播流程中ANR是如何触发的,但是如果想讲清楚ANR的流程,就不得不提整个广播事件的流程,所以就把两块内容合并在一起讲了. 本文会讲内容如下: 1.动态注册广播的整个分发流程,从广播发出,一直到广播注册者接收. 2.广播类型ANR的判断流程和原理. PS:本文基于android13的源码进行讲解. 一.基本流程和概念 动态广播的流程其实是很
-
Spring数据库连接池实现原理深入刨析
目录 Spring事务管理 环境搭建 标准配置 声明式事务 总结 SqlSessionFactory XML中构建SqlSessionFactory 获得SqlSession的实例 代码实现 作用域(Scope)和生命周期 SqlSessionFactoryBuilder(构造器) SqlSessionFactory(工厂) SqlSession(会话) Spring事务管理 事务(Transaction),一般是指要做的或所做的事情.在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序
-
JavaScript 关于事件循环机制的刨析
目录 前言: 一.事件循环和任务队列产生的原因: 二.事件循环机制: 三.任务队列: 3.1 任务队列的类型: 3.2 两者区别: 3.3 更细致的事件循环过程 四.强大的异步专家 process.nextTick() 4.1 process.nextTick()在何时调用? 前言: 这次主要整理一下自己对 Js事件循环机制,同步,异步任务,宏任务,微任务的理解,大概率暂时还有些偏差或者错误.如果有,十分欢迎各位纠正我的错误! 一.事件循环和任务队列产生的原因: 首先,JS是单线程,这样设计也是
-
Java集合框架之List ArrayList LinkedList使用详解刨析
目录 1. List 1.1 List 的常见方法 1.2 代码示例 2. ArrayList 2.1 介绍 2.2 ArrayList 的构造方法 2.3 ArrayList 底层数组的大小 3. LinkedList 3.1 介绍 3.2 LinkedList 的构造方法 4. 练习题 5. 扑克牌小游戏 1. List 1.1 List 的常见方法 方法 描述 boolean add(E e) 尾插 e void add(int index, E element) 将 e 插入到 inde
-
Java集合框架之Stack Queue Deque使用详解刨析
目录 1. Stack 1.1 介绍 1.2 常见方法 2. Queue 2.1 介绍 2.2 常见方法 3. Deque 3.1 介绍 3.2 常见方法 1. Stack 1.1 介绍 Stack 栈是 Vector 的一个子类,它实现了一个标准的后进先出的栈.它的底层是一个数组. 堆栈只定义了默认构造函数,用来创建一个空栈.堆栈除了包括由 Vector 定义的所有方法,也定义了自己的一些方法. 1.2 常见方法 方法 描述 E push(E item) 压栈 E pop() 出栈 E pee
-
C语言数据结构经典10大排序算法刨析
1.冒泡排序 // 冒泡排序 #include <stdlib.h> #include <stdio.h> // 采用两层循环实现的方法. // 参数arr是待排序数组的首地址,len是数组元素的个数. void bubblesort1(int *arr,unsigned int len) { if (len<2) return; // 数组小于2个元素不需要排序. int ii; // 排序的趟数的计数器. int jj; // 每趟排序的元素位置计数器. int itmp