MySQL性能之count* count1 count列对比示例
目录
- 正文
- count() 性能与啥相关?
- MVCC 简介
- MySQL 对 count() 的优化
- 查询性能 PK 大起底
- count(主键id)
- count(1)
- count(字段)
- count(*)
- count(1) 和 count(*) 对比
- 总结
正文
最近的工作中,我听到组内两名研发同学在交流数据统计性能的时候,聊到了以下内容:
数据统计你怎么能用 count(*) 统计数据呢,count(*) 太慢了,要是把数据库搞垮了那不就完了么,赶紧改用 count(1),这样比较快......
有点儿好奇,难道 count(1) 的性能真的就比 count(*) 要好吗?
印象中网上有很多的文章都有过类似问题的讨论,那 MySQL 统计数据总数 count(*) 、count(1)和count(列名) 哪个性能更优呢?今天我们就来聊一聊这个问题。
count() 性能与啥相关?
在讨论问题之前,我们需要先搞明白一件事:MySQL 中 count() 的性能到底与什么相关呢?
一件东西,我们知道如何取,必定需要提前知道如何存放才行,那我们可以初步判定,count() 性能应该与存储引擎相关!
我们都知道,MySQL 常见的存储引擎有两种:MyISAM 和 InnoDB。
在这两种存储引擎下,MySQL 对于使用 count() 返回结果的流程是不一样的:
- **MyISAM引擎:**每张表的总行数是存储在磁盘上,所以当执行 count() 时,是直接从磁盘拿到这个值返回,能够快速返回。
但要是在后面加了where查询条件时,统计总数也没有像想象中那么快了。
- **InnoDB 引擎:**执行 count(),需要将数据一行一行地读,再统计总数。
看到这里,可能你会有这样的疑问:
Q:为什么 InnoDB 引擎不像 MyISAM 引擎一样,把表总记录存储起来呢?
这个问题非常好,在回答这个问题之前,我们先来了解一下 MVCC 是个什么东东。
MVCC 简介
所谓MVCC,全称:Multi-Version Concurrency Control,即多版本并发控制。
MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
MVCC 在 MySQL InnoDB 中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读。
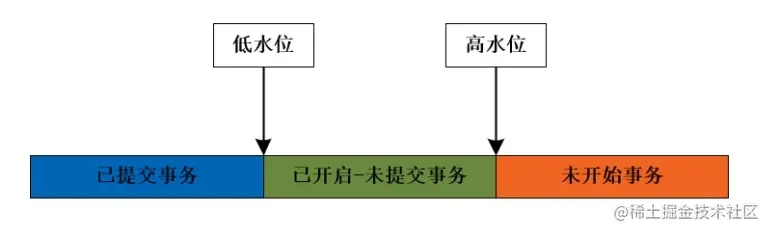
就是因为要实现多版本并发控制,所以才导致 InnoDB 引擎不能直接存储表总记录数。因为每个事务获取到的一致性视图都是不一样的,所以返回的数据总记录也是不一致的。
到这里,相信你已经知道 InnoDB 引擎为什么不像 MyISAM 引擎一样把表总记录存储起来了,简单理解原因就是:InnoDB 支持事务,MyISAM 不支持事务。
MySQL 对 count() 的优化
我们知道了count() 性能与存储引擎相关,那 MySQL 在执行 count() 操作的时候有没有对其性能做些优化呢?
答案是肯定有的!
InnoDB 是索引组织表,主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。因此,普通索引树比主键索引树小很多。对于count(*)这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL优化器会找到最小的那棵树来遍历。
如果你使用过 show table status 命令的话,就会发现这个命令的输出结果里面也有一个 rows 值用于显示这个表当前有多少行。
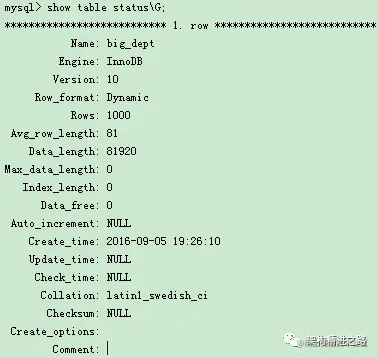
相信有人肯定会问,是不是这个 rows 值就能代替 count() 了吗?
其实不能,rows 这个是从从采样估算得来的,因此它也是不是准确。
官方文档说是在40%到50%,所以此行数 rows 是不能直接使用的,如下所示:

查询性能 PK 大起底
基于 MySQL 的 Innodb 存储引擎,统计表的总记录数下面这几种做法,到底哪种效率最高?
count(主键id)
InnoDB引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
count(1)
会统计表中的所有的记录数,包含字段为 null 的记录。
同样遍历整张表,但不取值,server 层对返回的每一行,放一个数字1进去,判断是不可能为空的,按行累加。
count(字段)
分为两种情况,字段定义为 not null 和 null:
1)为 not null 时:逐行从记录里面读出这个字段,判断不为 null,累加;
2)为 null 时:执行时,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
count(*)
需要注意的是,并不是带了 * 就把所有值取出来,而是 MySQL 做了专门的优化,count(*) 肯定不是null,按行累加。
count(1) 和 count(*) 对比
当表的数据量大些时,对表作分析之后,使用 count(1)还要比使用 count(*)用时多了!
从执行计划来看, count(1) 和 count(*)的效果是一样的。但是在表做过分析之后, count(1) 会比 count(*)的用时少些(1w以内数据量),不过差不了多少。
如果 count(1)是聚索引,那肯定是 count(1)快,但是差的很小。因为 count(*)自动会优化指定到那一个字段,所以没必要去 count(1),用 count(*) sql会帮你完成优化的,因此:count(1) 和 count(*)基本没有差别!
总结
基于 MySQL 的 InnoDB 存储引擎,统计表的总记录数按照效率排序:
count(字段) < count(主键id) < count(1)≈count(*)
效率最高是 count(*),并不是count(1),所以建议尽量使用 count(*)。
执行效果上:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为null
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为null
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null 的计数,即某个字段值为null 时,不统计。
执行效率上:
- 列名为主键,
count(列名)会比count(1)快 - 列名不为主键,
count(1)会比count(列名)快 - 如果表多个列并且没有主键,则
count(1)的执行效率优于count(*) - 如果有主键,则
select count(主键)的执行效率是最优的 - 如果表只有一个字段,则
select count(*)最优。
希望今天的讲解对大家有所帮助,谢谢!
更多关于MySQL count性能对比的资料请关注我们其它相关文章!
相关推荐
-

MySql统计函数COUNT的具体使用详解
目录 1. COUNT()函数概述 2. COUNT()参数说明 3. COUNT()判断存在 4. COUNT()阿里开发规范 1. COUNT()函数概述 COUNT() 是一个聚合函数,返回指定匹配条件的行数.开发中常用来统计表中数据,全部数据,不为NULL数据,或者去重数据. 2. COUNT()参数说明 COUNT(1):统计不为NULL 的记录.COUNT(*):统计所有的记录(包括NULL). COUNT(字段):统计该"字段"不为NULL 的记录.1.如果这个字段是定义
-
一文解答为什么MySQL的count()方法这么慢
目录 前言 count()的原理 各种count()方法的原理 允许粗略估计行数的场景 必须精确估计行数的场景 总结 前言 mysql用count方法查全表数据,在不同的存储引擎里实现不同,myisam有专门字段记录全表的行数,直接读这个字段就好了.而innodb则需要一行行去算. 比如说,你有一张短信表(sms),里面放了各种需要发送的短信信息. sms建表sql: sms表; 需要注意的是state字段,为0的时候说明这时候短信还未发送. 此时还会有一个异步线程不断的捞起未发送(state=
-
MySQL中count(*)执行慢的解决方案
目录 一. count(*) 的实现方式 1.实现方式比较 2.为什么InnoDB不像MyISAM一样,也把数字存起来 3.小结 二.计数方法 1.用缓存系统保存计数 2.在数据库保存计数 三.不同的 count 用法 1. count(主键 id) 2.count(1) 3.count(字段) 4.count(*) 前言: 在开发工作中,经常需要计算一个表的行数,比如一个内容系统审核记录总数.这时候我们最先想到是一条 select count(*) from my_table;语句.但是,随着
-
Mysql中count(*)、count(1)、count(主键id)与count(字段)的区别
目录 count()函数 count(*).count(1) .count(主键id) 和 count(字段) 区别 count(主键id) 与 count(1) count(字段) count(非空字段) count(可空字段) count(*) 执行效率 执行效果上: 执行效率上: 实例分析 count()函数 count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加.最后返回累计值. count(*).count(
-
Mysql中使用count加条件统计的实现示例
目录 前言 测试环境 准备工作 条件统计 总结 前言 最近发现在处理Mysql问题时,count()函数频繁上镜,常常出现在分组统计的情景下,但是有时候并不是使用group by分好组就可以直接统计了,比如说一个常见的需求,统计每个班级男生所占的比例,这种情况一般会按照班级分组,但是分组内不但要统计班级的人数,还要统计男生的人数,也就是说统计是有条件的,之前确实没有考虑过怎样实心,后来查询了资料,总结在这里,方便日后查找使用. Mysql中count()函数的一般用法是统计字段非空的记录数,所以
-
MySQL select count(*)计数很慢优化方案
目录 前言 1. MyISAM存储引擎计数为什么这么快? 2. 能不能手动实现统计总行数 3. InnoDB引擎能否实现快速计数 4. 四种计数方式的性能差别 前言 在日常开发工作中,我经常会遇到需要统计总数的场景,比如:统计订单总数.统计用户总数等.一般我们会使用MySQL 的count函数进行统计,但是随着数据量逐渐增大,统计耗时也越来越长,最后竟然出现慢查询的情况,这究竟是什么原因呢?本篇文章带你一下学习一下. 1. MyISAM存储引擎计数为什么这么快? 我们总有个错觉,就是感觉MyIS
-
MySQL性能之count* count1 count列对比示例
目录 正文 count() 性能与啥相关? MVCC 简介 MySQL 对 count() 的优化 查询性能 PK 大起底 count(主键id) count(1) count(字段) count(*) count(1) 和 count(*) 对比 总结 正文 最近的工作中,我听到组内两名研发同学在交流数据统计性能的时候,聊到了以下内容: 数据统计你怎么能用 count(*) 统计数据呢,count(*) 太慢了,要是把数据库搞垮了那不就完了么,赶紧改用 count(1),这样比较快......
-
MySQL中count()和count(1)有何区别以及哪个性能最好详解
目录 前言 哪种 count 性能最好? 为什么要通过遍历的方式来计数? 如何优化 count(*)? *第一种,近似值* 第二种,额外表保存计数值 总结 前言 当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1).count(*).count(字段) 等. 到底哪种效率是最好的呢?是不是 count(*) 效率最差? 我曾经以为 count(*) 是效率最差的,因为认知上 selete * from t
-
一文搞清楚MySQL count(*)、count(1)、count(col)区别
目录 count作用 测试 count(*) count(1) count(col) count(id):统计id count(indexcol):统计带索引的字段 count(normalcol):统计不带索引的字段 count(1)和count(*)取舍 总结 在工作中遇到count(*).count(1).count(col) ,可能会让你分不清楚,都是计数,干嘛这么搞这么多东西. count 作用 COUNT(expression):返回查询的记录总数,expression 参数是一个字
-
Select count(*)、Count(1)和Count(列)的区别及执行方式
在SQL Server中Count(*)或者Count(1)或者Count([列])或许是最常用的聚合函数.很多人其实对这三者之间是区分不清的.本文会阐述这三者的作用,关系以及背后的原理. 往常我经常会看到一些所谓的优化建议不使用Count(* )而是使用Count(1),从而可以提升性能,给出的理由是Count( *)会带来全表扫描.而实际上如何写Count并没有区别. Count(1)和Count(*)实际上的意思是,评估Count()中的表达式是否为NULL,如果为NULL则不计数,而非N
-
浅谈MySQL 统计行数的 count
MySQL count() 函数我们并不陌生,用来统计每张表的行数.但如果你的表越来越大,且是 InnoDB 引擎的话,会发现计算的速度会越来越慢.在这篇文章里,会先介绍 count() 实现的原理及原因,然后是 count 不同用法的性能分析,最后给出需要频繁改变并需要统计表行数的解决方案. Count() 的实现 InnoDB 和 MyISAM 是 MySQL 常用的数据引擎,由于两者实现的不同,导致 count() 操作计算的效率也不同. 对于 MyISAM 来说,它把每个表的总行数都存在
-
MySQL count(1)、count(*)、count(字段)的区别
目录 1.初识COUNT 2.COUNT(字段).COUNT(常量)和COUNT(*)之间的区别 3.COUNT(*)的优化 MyISAM InnoDB 4.COUNT(*)和COUNT(1) 5.COUNT(字段) 6.总结 关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT. 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐.不信的话请尝试回答下以下问题: > 1.COUNT有几种用法? > 2.COUN
-
MySQL 中的count(*) 与 count(1) 谁更快一些?
目录 1.实践 2.explain分析 3.原理分析 3.1主键索引与普通索引 3.2原理分析 4.MyISAM呢? 先说结论:这两个性能差别不大. 1.实践 我准备了一张有 100W 条数据的表,表结构如下: CREATE TABLE `user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `address` varchar(255) DEFAULT
-
MySQL中count(*)、count(1)和count(col)的区别汇总
前言 count函数是用来统计表中或数组中记录的一个函数,count(*) 它返回检索行的数目, 不论其是否包含 NULL值.最近感觉大家都在讨论count的区别,那么我也写下吧:欢迎留言讨论,话不多说了,来一起看看详细的介绍吧. 1.表结构: dba_jingjing@3306>[rds_test]>CREATE TABLE `test_count` ( -> `c1` varchar(10) DEFAULT NULL, -> `c2` varchar(10) DEFAULT N
-
MySQL性能优化的一些技巧帮助你的数据库
你完成了你的品牌新的应用程序,一切工作就像一个魅力.用户来使用你的网络.每个人是幸福的. 然后,突然间,一个大爆发的用户杀死你的MySQL服务器,您的网站已关闭.出了什么问题?你怎么能阻止它吗? 以下是MySQL性能优化的一些技巧,将帮助你,帮助你的数据库. 大处着眼 在早期的发展阶段,你应该知道预期到您的应用程序的用户数.如果你希望很多用户来说,你应该想想大,从一开始,计划进行复制,可扩展性和性能. 但是,如果你优化你的SQL代码,架构和索引策略,也许你不会需要大环境.你必须总是三思而后行的性