go语言中布隆过滤器低空间成本判断元素是否存在方式
目录
- 简介
- 原理
- 数据结构
- 添加
- 判断存在
- 哈希函数
- 布隆过滤器大小、哈希函数数量、误判率
- 应用场景
- 数据库
- 黑名单
- 实现
- 数据结构
- 初始化
- 添加元素
- 判断元素是否存在
简介
布隆过滤器(BloomFilter)是一种用于判断元素是否存在的方式,它的空间成本非常小,速度也很快。
但是由于它是基于概率的,因此它存在一定的误判率,它的Contains()操作如果返回true只是表示元素可能存在集合内,返回false则表示元素一定不存在集合内。因此适合用于能够容忍一定误判元素存在集合内的场景,比如缓存。
它一秒能够进行上百万次操作(主要取决于哈希函数的速度),并且1亿数据在误判率1%的情况下,只需要114MB内存。
原理
数据结构
布隆过滤器的数据结构是一个位向量,也就是一个由0、1所组成的向量(下面是一个初始向量):

添加
每个元素添加进布隆过滤器前,都会经过多个不同的哈希函数,计算出不同的哈希值,然后映射到位向量上,也就是对应的位上面置1:

判断存在
判断元素是否存在也是如上图流程,根据哈希函数映射的位置,判断所有映射位置是否都为1,如果是则元素可能存在,否则元素一定不存在。
由于不同的值通过哈希函数之后可能会映射到相同的位置,因此如果一个不存在的元素对应的位位置都被其他元素所设置位1,则查询时就会误判:
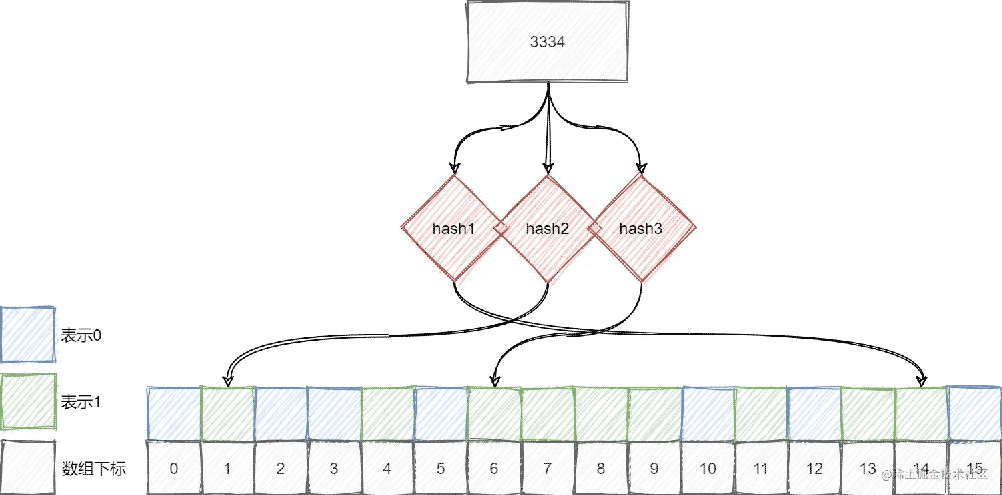
假设上图元素3334并没有加入集合,但是由于它映射的位置已经被其他元素所映射,则查询时会误判。
哈希函数
布隆过滤器里面的哈希函数需要是彼此独立且均匀分布(类似于哈希表的哈希函数),而且需要尽可能的快,比如murmur3就是一个很好的选择。
布隆过滤器的性能严重依赖于哈希函数的性能,而一般哈希函数的性能则依赖于输入串(一般为字节数组)的长度,因此为了提高布隆过滤器的性能建议减少输入串的长度。
下面是一个简单的性能测试,单位是字节,可以看到时间的消耗随着元素的增大基本是线性增长的:
cpu: Intel(R) Core(TM) i5-10210U CPU @ 1.60GHz
BenchmarkAddAndContains/1-8 1805840 659.6 ns/op 1.52 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/2-8 1824064 696.4 ns/op 2.87 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/4-8 1819742 649.5 ns/op 6.16 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/8-8 1828371 653.2 ns/op 12.25 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/16-8 1828426 642.0 ns/op 24.92 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/32-8 2106834 565.7 ns/op 56.57 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/64-8 2063895 579.3 ns/op 110.48 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/128-8 1767673 666.1 ns/op 192.17 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/256-8 1292918 916.9 ns/op 279.21 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/512-8 749666 1590 ns/op 322.11 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/1024-8 388015 2933 ns/op 349.12 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/2048-8 203404 5603 ns/op 365.51 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/4096-8 105134 11303 ns/op 362.38 MB/s 0 B/op 0 allocs/op
BenchmarkAddAndContains/8192-8 52305 22067 ns/op 371.23 MB/s 0 B/op 0 allocs/op
布隆过滤器大小、哈希函数数量、误判率
布隆过滤器的大小、哈希函数数量和误判率之间是互相影响的,如果我们想减少误判率,则需要更大的布隆过滤器和更多的哈希函数。但是我们很难直观的计算出这些参数,还好有两个公式可以帮助我们计算出准确的数值:
在我们可以确定我们的元素数量和能够容忍的错误率的情况下,我们可以根据下面公式计算布隆过滤器大小和哈希函数数量:
n = 元素数量
m = 布隆过滤器大小(位数)
k = 哈希函数数量
fpr = 错误率(falsePositiveRate,假阳性率)
m = n*(-ln(fpr)/(ln2*ln2))
k = ln2 * m / n
应用场景
数据库
布隆过滤器可以提前过滤所查询数据并不存在的请求,避免对磁盘访问的耗时。比如LevelDB就使用了布隆过滤器过滤请求github.com/google/leve… 。
黑名单
假设有10亿个黑名单URL,每个URL大小为64字节。使用Bloom Filter,如果错误率为0.1%,只需要1.4GB内存,如果错误率为0.0001%,也只需要2.9GB内存。
实现
这里简单的介绍一下Golang的实现方式。
数据结构
由于我们没办法直接申请一个bit组成的数组,因此我们使用uint64表示64个bit。
type Filter struct {
bits []uint64 // bit数组
bitsCnt uint64 // bit位数
hashs []*hash.Hash // 不同哈希函数
}
初始化
在初始化的时候,我们需要根据上面提到的两个公式,计算布隆过滤器的大小和哈希函数的数量。
// capacity:容量
// falsePositiveRate:误判率
func New(capacity uint64, falsePositiveRate float64) *Filter {
// bit数量
ln2 := math.Log(2.0)
factor := -math.Log(falsePositiveRate) / (ln2 * ln2)
bitsCnt := mmath.Max(1, uint64(float64(capacity)*factor))
// 哈希函数数量
hashsCnt := mmath.Max(1, int(ln2*float64(bitsCnt)/float64(capacity)))
hashs := make([]*hash.Hash, hashsCnt)
for i := 0; i < hashsCnt; i++ {
hashs[i] = hash.New()
}
return &Filter{
bits: make([]uint64, (bitsCnt+63)/64),
bitsCnt: bitsCnt,
hashs: hashs,
}
}
添加元素
添加元素的时候,把每个哈希函数映射的位置都设置为1。这里需要注意,因为是用的uint64的数组,因此需要把按照bit计算的偏移,转换为按照64位计算的数组下标和对应下标元素里面的偏移。
// 添加元素
func (f *Filter) Add(b []byte) {
for _, h := range f.hashs {
index, offset := f.pos(h, b)
f.bits[index] |= 1 << offset
}
}
// 获取对应元素下标和偏移
func (f *Filter) pos(h *hash.Hash, b []byte) (uint64, uint64) {
hashValue := h.Sum64(b)
// 按照位计算的偏移
bitsIndex := hashValue % f.bitsCnt
// 因为一个元素64位,因此需要转换
index := bitsIndex / uint64Bits
// 在一个元素里面的偏移
offset := bitsIndex % uint64Bits
return index, offset
}
判断元素是否存在
同理,只是这里我们如果发现某一位不为1则可以直接返回false。
// 元素是否存在
// true表示可能存在
func (f *Filter) Contains(b []byte) bool {
for _, h := range f.hashs {
index, offset := f.pos(h, b)
mask := uint64(1) << offset
// 判断这一位是否位1
if (f.bits[index] & mask) != mask {
return false
}
}
return true
}
参考
以上就是go语言中布隆过滤器低空间成本判断元素是否存在方式的详细内容,更多关于go 布隆过滤器判断元素的资料请关注我们其它相关文章!
相关推荐
-
Go语言框架快速集成限流中间件详解
目录 前言 分布式版 简介 算法 实现 注意 单机版 简介 算法 实现 结语 前言 在我们的日常开发中, 常用的中间件有很多, 今天来讲一下怎么集成限流中间件, 它可以很好地用限制并发访问数来保护系统服务, 避免系统服务崩溃, 资源占用过大甚至服务器崩溃进而影响到其他应用! 分布式版 简介 通常我们的服务会同时存在多个进程, 也就是负载来保证服务的性能和稳定性, 那么就需要走一个统一的限流, 这个时候就需要借助我们的老朋友-redis, 来进行分布式限流; 算法 漏桶算法 即一个水桶, 进水(接
-

go 分布式锁简单实现实例详解
目录 正文 案例 资源加锁 使用redis来实现分布式锁 redis lua保证原子性 正文 其实锁这种东西,都能能不加就不加,锁会导致程序一定程度上退回到串行化,进而降低效率. 案例 首先,看一个案例,如果要实现一个计数器,并且是多个协程共同进行的,就会出现以下的情况: package main import ( "fmt" "sync" ) func main() { numberFlag := 0 wg := new(sync.WaitGroup) for i
-
go语言Pflag Viper Cobra 核心功能使用介绍
目录 1.如何构建应用框架 2.命令行参数解析工具:Pflag 2.1 Pflag 包 Flag 定义 2.2 Pflag 包 FlagSet 定义 2.3 Pflag 使用方法 3.配置解析神器:Viper 3.1读入配置 3.2 读取配置 4.现代化的命令行框架:Cobra 4.1 使用 Cobra 库创建命令 4.2使用标志 5.总结 1.如何构建应用框架 一般来说构建应用框架包含3个部分: 命令行参数解析 配置文件解析 应用的命令行框架:需要具备 Help 功能.需要能够解析命令行参数和
-
Django中Migrate和Makemigrations实操详解
目录 一.前言 二.migrate和makemigrations详解和实操 1. makemigrations 2. 在协同开发的情况下,有冲突的迁移文件时如何解决? 3. migrate 4. 迁移报错怎么办? 三.迁移生成的外键约束有必要吗 四.反向迁移-inspectdb 一.前言 当我们在django中添加或修改了数据库model后,一般需要执行makemigrations.migrate把我们的model类生成相应的数据库表,或修改对应的表结构.这是非常方便的. 但我们在实际使用中执行
-
go语言中布隆过滤器低空间成本判断元素是否存在方式
目录 简介 原理 数据结构 添加 判断存在 哈希函数 布隆过滤器大小.哈希函数数量.误判率 应用场景 数据库 黑名单 实现 数据结构 初始化 添加元素 判断元素是否存在 简介 布隆过滤器(BloomFilter)是一种用于判断元素是否存在的方式,它的空间成本非常小,速度也很快. 但是由于它是基于概率的,因此它存在一定的误判率,它的Contains()操作如果返回true只是表示元素可能存在集合内,返回false则表示元素一定不存在集合内.因此适合用于能够容忍一定误判元素存在集合内的场景,比如缓存
-
布隆过滤器面试如何快速判断元素是否在集合里
目录 1.什么叫布隆过滤器 2.实现原理 3.作用 4.具体实现 5.代码的实现 6.实战 7.小结 如何快速判断一个元素是不是在一个集合里?这个题目是我最近面试的时候常问的一个问题,这个问题不同人都有很多不同的回答. 今天想介绍一个很少有人会提及到的方案,那就是借助布隆过滤器. 1.什么叫布隆过滤器 布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的. 实际上可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构. 它的
-
C语言中斐波那契数列的三种实现方式(递归、循环、矩阵)
目录 一.递归 二.循环 三.矩阵 <剑指offer>里讲到了一种斐波那契数列的 O(logN) 时间复杂度的实现,觉得挺有意思的,三种方法都记录一下. 一.递归 一般来说递归实现的代码都要比循环要简洁,但是效率不高,比如递归计算斐波那契数列第n个元素. long long Fibonacci_Solution1(unsigned int n) { // printf("%d ", n); if (n <= 0) return 0; if (n == 1) retur
-
C语言中结构体偏移及结构体成员变量访问方式的问题讨论
c语言结构体偏移 示例1 我们先来定义一下需求: 已知结构体类型定义如下: struct node_t{ char a; int b; int c; }; 且结构体1Byte对齐 #pragma pack(1) 求: 结构体struct node_t中成员变量c的偏移. 注:这里的偏移量指的是相对于结构体起始位置的偏移量. 看到这个问题的时候,我相信不同的人脑中浮现的解决方法可能会有所差异,下面我们分析以下几种可能的解法: 方法1 如果你对c语言的库函数比较熟悉的话,那么你第一个想到的肯定是of
-
Vue watch中监听值的变化,判断后修改值方式
目录 watch监听值的变化,判断后修改值 watch监听data函数中数据改变的三种方式 1.常用型(浅层监听) 2.深层监听(利用deep属性) 3.深层监听某一个特定属性(用字符串表示对象属性的调用) watch监听值的变化,判断后修改值 计数器有最小值与最大值的限制,且中间的文本输入框可自己输入值. 实现方式是在watch中监听文本输入框绑定的v-model,跟最大最小值比较后,如果有需要,则改变值. <mu-text-field v-model.number="weightNum
-
浅析python实现布隆过滤器及Redis中的缓存穿透原理
目录 布隆过滤器的原理 在 Python 中使用布隆过滤器 1.标准布隆过滤器. 2.计数布隆过滤器. 3.标准扩容布隆过滤器. 4.计数扩容布隆过滤器. Redis 中使用布隆过滤器 最后的话 在开发软件时,我们经常需要判断一个元素是否在一个集合中,比如,如何判断单词的拼写是否错误(判断单词是否在已知的字典中):在网络爬虫里,如何确认一个网址是否已经爬取过:反垃圾邮件系统中,如何判断一个邮件地址是否为垃圾邮件地址等等. 如果这些作为面试题那就很有区分度了,初级工程师就会说,把全部的元素都存在
-
Redis 中的布隆过滤器的实现
什么是『布隆过滤器』 布隆过滤器是一个神奇的数据结构,可以用来判断一个元素是否在一个集合中.很常用的一个功能是用来去重.在爬虫中常见的一个需求:目标网站 URL 千千万,怎么判断某个 URL 爬虫是否宠幸过?简单点可以爬虫每采集过一个 URL,就把这个 URL 存入数据库中,每次一个新的 URL 过来就到数据库查询下是否访问过. select id from table where url = 'https://jaychen.cc' 但是随着爬虫爬过的 URL 越来越多,每次请求前都要访问数据
-
Python+Redis实现布隆过滤器
布隆过滤器是什么 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难. 布隆过滤器的基本思想 通过一种叫作散列表(又叫哈希表,Hash table)的数据结构.它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点.这样一来,我们只要看看这个点是不是1就可以知道集合中有没
-
C++ 数据结构之布隆过滤器
布隆过滤器 一.历史背景知识 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都远超过一般的算法,缺点是有一定的误识别率和删除错误.而这个缺点是不可避免的.但是绝对不会出现识别错误的情况出现(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在集合中的,所以不会漏报) 在 FBI,一个
-
JAVA实现较完善的布隆过滤器的示例代码
布隆过滤器是可以用于判断一个元素是不是在一个集合里,并且相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势.布隆过滤器存储空间和插入/查询时间都是常数.但是它也是拥有一定的缺点:布隆过滤器是有一定的误识别率以及删除困难的.本文中给出的布隆过滤器的实现,基本满足了日常使用所需要的功能. 0 0 0 0 0 0 0 0 0 0 先简单来说一下布隆过滤器.其实现方法就是:利用内存中一个长度为M的位数组B并初始化里面的所有位都为0,如下面的表格所示: 然后我们根据H个不同的散列函数,对传进来