关于数据处理包dplyr的函数用法总结
dplyr专注处理dataframe对象, 并提供更稳健的与其它数据库对象间的接口。
一、5个关键的数据处理函数:
select() 返回列的子集
filter() 返回行的子集
arrange() 根据一个或多个变量对行排序。
mutate() 使用已有数据创建新的列
summarise() 对各个群组汇总计算并返回一维结果。
Tips:
1、select()
Dplyr包有下列辅助函数,用于在select()中选择变量:
starts_with("X"): 以 "X"开头的变量名
ends_with("X"): 以 "X"结束的变量名
contains("X"): 包含 "X"的变量名
matches("X"): 匹配正则表达式“x"的变量名
num_range("x", 1:5): 变量名为 x01, x02, x03, x04 and x05
one_of(x): 出现在字符向量x中的所有变量名
在select()中直接使用列时不需要引用"",但使用上述辅助函数时必须引用""。
2、filter()
R 有一系列逻辑表达式可用于filter()中:
x < y;x <= y;x == y;x != y;x >= y;x > y;x %in% c(a, b, c)
示例:
filter(df, a > 0, b > 0)
filter(df, !is.na(x))
3、arrange()
arrange()默认从小到大排序,在arrange()中使用desc()作用于变量可以使之从大到小排序.
4、mutate()
mutate()允许在同一次调用中使用新变量来创建下一个变量,例如:
mutate(my_df, x = a + b, y = x + c)
5、 summarise()
R的下列聚合函数可用于 summarise()中
- min(x) - 最小值.
- max(x) - 最大值
- mean(x) - 平均值
- median(x) - 中位数
- quantile(x, p) - x的第P个分位数
- sd(x) -标准差
- var(x) - 方差
- IQR(x) - 四分位数
- diff(range(x)) - x值的范围
dplyr包自身提供了一些有用的聚合函数:
- first(x) - 向量x中的第1个元素
- last(x) - 向量x中的最后1个元素
- nth(x, n) - 向量x中的第n个元素
- n() - data.frame中的行数或 summarise() 描述的观测组的数量
- n_distinct(x) - 向量x中唯一值的数量
二、管道函数%>%
dplyr包中特有的管道函数%>%,将上一个函数的输出作为下一个函数的输入。
%>%运算符允许从参数列表中提取函数的第一个参数,并放置在%>%前面。
下面两条指令相等:
mean(c(1, 2, 3, NA), na.rm = TRUE)
c(1, 2, 3, NA) %>% mean(na.rm = TRUE)
三、分组函数group_by()
对数据集定义群组。然后可对各个群组分别进行汇总统计。
通过 group_by() 添加了分组信息后,mutate(), arrange() 和 summarise() 函数会自动对这些 tbl 类数据执行分组操作。
group_by(dataframe,colnames1,colnames2,…)
四、连接数据(joins)
1、6种连接函数如下:
left_join(dataset1,dataset2)
right_join(dataset1,dataset2)
inner_join(dataset1,dataset2,by=c(“”))
full_join(dataset1,dataset2, by = c("first", "last"))
semi_join(dataset1,dataset2, by = c("first", "last"))
anti_join(dataset1,dataset2, by = c("first", "last"))
前4种属于变形连接(mutating joins),后2种属于过滤连接(filtering joins)。
semi-joins基于第二个数据集的信息来过滤第一个数据集的数据。anti-joins找出合并时哪些行不能匹配第二个数据集

2、key值
R语言的 data frames可在 row.names属性中存储重要信息,虽然不是存储数据的好方式却很常见。如果数据集的主关键字在row.names中,将难以与其他数据集连接。一种解决方法是使用tibble包(tibble:a data frame with class tbl_df)中的rownames_to_column()函数,返回该数据集的副本,并且行名作为一列增加到该数据中。
library(tibble)
rownames_to_column(data, var="name")
如果两个数据集有相同的列名,但代表的事物不同,并且by参数不包含这些重复的列名,dplyr会忽略这些列名,并对相同的列名增加.x和 .y来帮助区分列。
当两个数据集中相同的事物有不同的列名,要完成合并,将by设置为一个命名向量。向量的名字为主数据集中的列名,向量的值为第二个数据集中的列名。例如:
x %>% left_join(y, by = c("x.name" = "y.name"))
完成连接后保留主数据集中的列名。
3、多个数据集的连接
Purrr包中的 reduce()函数对多个数据集重复应用某函数,可用于连接多个数据集,与dplyr的join类函数配合使用,例如:
library(purrr)
list(data1,data2,data3) %>% reduce(left_join,by = c("first","last"))
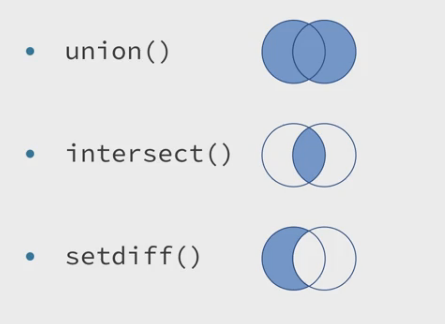
五、集合操作(set operations)
dplyr提供了intersection、union和setdiff用于获得数据集的交集、并集和差集。
六、组装数据assembling data
使用如下函数:
bind_rows()
bind_cols() :将多个data frame合成单个data frame
data_frame() : 将一系列列向量组合成data frame
as_data_frame() :将list转换成data frame
以上这篇关于数据处理包dplyr的函数用法总结就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

关于数据处理包dplyr的函数用法总结
dplyr专注处理dataframe对象, 并提供更稳健的与其它数据库对象间的接口. 一.5个关键的数据处理函数: select() 返回列的子集 filter() 返回行的子集 arrange() 根据一个或多个变量对行排序. mutate() 使用已有数据创建新的列 summarise() 对各个群组汇总计算并返回一维结果. Tips: 1.select() Dplyr包有下列辅助函数,用于在select()中选择变量: starts_with("X"): 以 "X&qu
-
Python3基础之函数用法
一般来说,函数(function)是组织好的.可重复使用的.具有一定功能的代码段.函数能提高应用的模块性和代码的重复利用率,在Python中已经提供了很多的内建函数,比如print(),同时Python还允许用户自定义函数. 本文就来实例总结一下Python3的函数用法,具体内容如下: 一.定义 定义函数使用关键字def,后接函数名和放在圆括号( )中的可选参数列表,函数内容以冒号起始并且缩进.一般格式如下: def 函数名(参数列表): """文档字符串"&quo
-
php中Ctype函数用法详解
本文实例分析了php中Ctype函数用法.分享给大家供大家参考.具体分析如下: Ctype函数是Php的Ctype扩展函数提供了一组函数用于校验字符串中的字符是否是正确的格式,这里我们主要介绍一下这些字符串验证函数的语法.有什么特殊的函数,如何去验证等. Ctype函数是PHP内置的字符串体测函数,主要有以下几种: ctype_alnum -- Check for alphanumeric character(s):检测是否是只包含[A-Za-z0-9] ctype_alpha -- Check
-
Python模块、包(Package)概念与用法分析
本文实例讲述了Python模块.包(Package)概念与用法.分享给大家供大家参考,具体如下: Python中"模块"的概念 在开发中,我们会有很多函数,我们可以把这些函数都放到一个文件. 比如function.py中: #定义函数 def show(): print("jack") #定义变量 name = "tom" 在其他地方要使用其中的函数怎么办呢? 第一步:需要先引入 import funtions 第二步:通过文件名.函数名/变量名
-
python yield和Generator函数用法详解
这篇文章主要介绍了python yield和Generator函数用法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 首先我们从一个小程序导入,各定一个list,找出其中的素数,我们会这样写 import math def is_Prims(number): if number == 2: return True //除2以外的所有偶数都不是素数 elif number % 2 == 0: return False //如果一个数能被除1和
-
python数据处理67个pandas函数总结看完就用
目录 导⼊数据 导出数据 查看数据 数据选取 数据处理 数据分组.排序.透视 数据合并 不管是业务数据分析 ,还是数据建模.数据处理都是及其重要的一个步骤,它对于最终的结果来说,至关重要. 今天,就为大家总结一下 "Pandas数据处理" 几个方面重要的知识,拿来即用,随查随查. 导⼊数据 导出数据 查看数据 数据选取 数据处理 数据分组和排序 数据合并 # 在使用之前,需要导入pandas库 import pandas as pd 导⼊数据 这里我为大家总结7个常见用法. pd.Da
-
利用Python的pandas数据处理包将宽表变成窄表
目录 前言 1.引入包 3.关键操作,将宽表转换为窄表 4.对空值进行处理 5.导出存储到Excel中 前言 工作中经常会使用到将宽表变成窄表,例如这样的形式 编号 编码 单位1 单位2 单位3 单位4 ... ... ... ... ... ... 1 编码1... 数量... 数量... 数量... 数量... ... ... ... ... ... ... 2 编码2... 数量... 数量... 数量... 数量... ... ... ... ... ... ..
-
SeaJS中use函数用法实例分析
本文实例讲述了SeaJS中use函数用法.分享给大家供大家参考,具体如下: 有了 define 等模块定义规范的实现,我们可以开发出很多模块.但光有一堆模块不管用,我们还得让它们能跑起来.在 SeaJS 里,要启动模块系统很简单: <script src="path/to/sea.js"></script> <script> seajs.use('./main'); </script> seajs.use 用来在页面中加载模块.通过 us
-
Oracle 中 decode 函数用法
含义解释: decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值) 该函数的含义如下: IF 条件=值1 THEN RETURN(翻译值1) ELSIF 条件=值2 THEN RETURN(翻译值2) ...... ELSIF 条件=值n THEN RETURN(翻译值n) ELSE RETURN(缺省值) END IF decode(字段或字段的运算,值1,值2,值3) 这个函数运行的结果是,当字段或字段的运算的值等于值1时,该函数返回值2,否则返回值3 当然值1
-
oracle中length、lengthb、substr、substrb函数用法介绍
我记得我曾经在开发form的时候犯过这样一个错误,对于form中的某个字段,对应于数据库中某张表的字段,假设在数据库中这个字段一般也就用到20个汉字的长度,后来我在开发form的时候,设置item类型长度的时候,我惯性的设置成了50byte,想着就算是20个汉字,最多也就占40个byte长度嘛.可是,就因为这一个想当然,结果出现错误了,后来发现数据库字符集编码是utf8,那么应该设置为60.从那以后,每次涉及到给字段设置长度的时候,我都会特别注意下,到底是啥编码. 在oracle中,比较常见的可