解决MySQL Sending data导致查询很慢问题的方法与思路
最近帮忙定位一个mysql查询很慢的问题,定位过程综合各种方法、理论、工具,很有代表性,分享给大家。
【问题现象】
使用sphinx支持倒排索引,但sphinx从mysql查询源数据的时候,查询的记录数才几万条,但查询的速度非常慢,大概要4~5分钟左右
【处理过程】
1)explain
首先怀疑索引没有建好,于是使用explain查看查询计划,结果如下:

从explain的结果来看,整个语句的索引设计是没有问题的,除了第一个表因为业务需要进行整表扫描外,其它的表都是通过索引访问
2)show processlist;
explain看不出问题,那到底慢在哪里呢?
于是想到了使用 show processlist查看sql语句执行状态,查询结果如下:

发现很长一段时间,查询都处在 “Sending data”状态
查询一下“Sending data”状态的含义,原来这个状态的名称很具有误导性,所谓的“Sending data”并不是单纯的发送数据,而是包括“收集 + 发送 数据”。
这里的关键是为什么要收集数据,原因在于:mysql使用“索引”完成查询结束后,mysql得到了一堆的行id,如果有的列并不在索引中,mysql需要重新到“数据行”上将需要返回的数据读取出来返回个客户端。
3)show profile
为了进一步验证查询的时间分布,于是使用了show profile命令来查看详细的时间分布
首先打开配置:set profiling=on;
执行完查询后,使用show profiles查看query id;
使用show profile for query query_id查看详细信息;
结果如下:
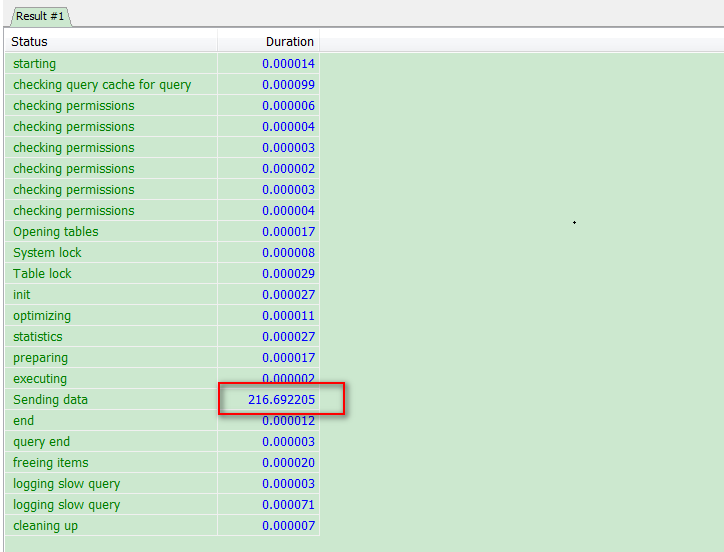
从结果可以看出,Sending data的状态执行了216s
4)排查对比
经过以上步骤,已经确定查询慢是因为大量的时间耗费在了Sending data状态上,结合Sending data的定义,将目标聚焦在查询语句的返回列上面
经过一 一排查,最后定为到一个description的列上,这个列的设计为:`description`varchar(8000) DEFAULT NULL COMMENT '游戏描述',
于是采取了对比的方法,看看“不返回description的结果”如何。show profile的结果如下:
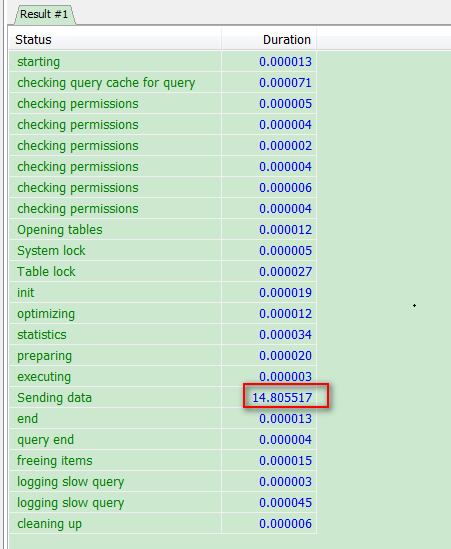
可以看出,不返回description的时候,查询时间只需要15s,返回的时候,需要216s,两者相差15倍
【原理研究】
至此问题已经明确,但原理上我们还需要继续探究。
这篇淘宝的文章很好的解释了相关原理:innodb使用大字段text,blob的一些优化建议
这里的关键信息是:当Innodb的存储格式是 ROW_FORMAT=COMPACT (or ROW_FORMAT=REDUNDANT)的时候,Innodb只会存储前768字节的长度,剩余的数据存放到“溢出页”中。
我们使用show table status来查看表的相关信息:

可以看到,平均一行大约1.5K,也就说大约1/10行会使用“溢出存储”,一旦采用了这种方式存储,返回数据的时候本来是顺序读取的数据,就变成了随机读取了,所以导致性能急剧下降。
另外,在测试过程中还发现,无论这条语句执行多少次,甚至将整个表select *几次,语句的执行速度都没有明显变化。这个表的数据和索引加起来才150M左右,而整个Innodb buffer pool有5G,缓存整张表绰绰有余,如果缓存了溢出页,性能应该大幅提高才对。
但实测结果却并没有提高,因此从这个测试可以推论Innodb并没有将溢出页(overflow page)缓存到内存里面。
这样的设计也是符合逻辑的,因为overflow page本来就是存放大数据的,如果也放在缓存里面,就会出现一次大数据列(blob、text、varchar)查询,可能就将所有的缓存都更新了,这样会导致其它普通的查询性能急剧下降。
【解决方法】
找到了问题的根本原因,解决方法也就不难了。有几种方法:
1)查询时去掉description的查询,但这受限于业务的实现,可能需要业务做较大调整
2)表结构优化,将descripion拆分到另外的表,这个改动较大,需要已有业务配合修改,且如果业务还是要继续查询这个description的信息,则优化后的性能也不会有很大提升。
以上就是本文的全部内容,希望对大家的学习有所帮助。
相关推荐
-
mysql正确安全清空在线慢查询日志slow log的流程分享
1, see the slow log status; mysql> show variables like '%slow%';+---------------------+------------------------------------------+| Variable_name | Value |+---------------------+-------------------------------
-
深入mysql慢查询设置的详解
在web开发中,我们经常会写出一些SQL语句,一条糟糕的SQL语句可能让你的整个程序都非常慢,超过10秒一般用户就会选择关闭网页,如何优化SQL语句将那些运行时间 比较长的SQL语句找出呢?MySQL给我们提供了一个很好的功能,那就是慢查询!所谓的慢查询就是通过设置来记录超过一定时间的SQL语句!那么如何应用慢查询呢? 1.开启MySQL的慢查询日志功能默认情况下,MySQL是不会记录超过一定执行时间的SQL语句的.要开启这个功能,我们需要修改MySQL的配置文件,windows下修改my.in
-
MySQL慢查询查找和调优测试
编辑 my.cnf或者my.ini文件,去除下面这几行代码的注释: 复制代码 代码如下: log_slow_queries = /var/log/mysql/mysql-slow.log long_query_time = 2 log-queries-not-using-indexes 这将使得慢查询和没有使用索引的查询被记录下来. 这样做之后,对mysql-slow.log文件执行tail -f命令,将能看到其中记录的慢查询和未使用索引的查询. 随便提取一个慢查询,执行explain: 复制代
-
mysqlsla慢查询分析工具使用笔记
且该工具自带相似SQL语句去重的功能,能按照指定方式进行排序(比如分析慢查询日志的时候,让其按照SQL语句执行时间逆排序,就能很方便的定位出问题所在) + ------------- 安装mysqlsla慢查询日志分析工具 ------------- + 复制代码 代码如下: yum -y install perl-ExtUtils-CBuilder perl-ExtUtils-MakeMakeryum -y install perl-DBI perl-DBD-MySQLyum -y insta
-
mysql服务器查询慢原因分析与解决方法小结
会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影响,例如一个几千万条记录的大表要全部扫描,或者是不停的做filesort,对数据库和服务器造成io影响等.这是镜像库上面的情况. 而到了线上库,除了出现没有索引的语句,没有用limit的语句,还多了一个情况,mysql连接数过多的问题.说到这里,先来看看以前我们的监控做法 1. 部署zabbix等开源分布式监控系统,获取每天的数据库的io,cpu,连接数 2. 部署每周性能统计,包含数据增加量,i
-
mysql 开启慢查询 如何打开mysql的慢查询日志记录
mysql慢查询日志对于跟踪有问题的查询非常有用,可以分析出当前程序里有很耗费资源的sql语句,那如何打开mysql的慢查询日志记录呢? 其实打开mysql的慢查询日志很简单,只需要在mysql的配置文件里(windows系统是my.ini,linux系统是my.cnf)的[mysqld]下面加上如下代码: 复制代码 代码如下: log-slow-queries=/var/lib/mysql/slowquery.log long_query_time=2 注: log-slow-queries
-

mysql 卡死 大部分线程长时间处于sending data的状态
有台服务器,访问量挺大,每天近250w动态pv,数据库查询平均每秒近600次 另一台服务器,跑的程序跟这台一样,不过只有每天约40w动态pv 前段时间连续卡死过几次,当时的状态是 服务器没崩溃,数据库可正常登陆.只是所有的查询都卡在"sending data"状态,长时间无法执行完,这些简单的sql语句,有时候集中在A表上,有时候集中在B表上,同时还有一些卡死在locked状态或update状态 看mysql的说明,sending data状态表示两种情况,一种是mysql已经查询了数
-
MySQL前缀索引导致的慢查询分析总结
前端时间跟一个DB相关的项目,alanc反馈有一个查询,使用索引比不使用索引慢很多倍,有点毁三观.所以跟进了一下,用explain,看了看2个查询不同的结果. 不用索引的查询的时候结果如下,实际查询中速度比较块. 复制代码 代码如下: mysql> explain select * from rosterusers limit 10000,3 ; +----+-------------+-------------+------+---------------+------+---------+-
-
解决MySQL Sending data导致查询很慢问题的方法与思路
最近帮忙定位一个mysql查询很慢的问题,定位过程综合各种方法.理论.工具,很有代表性,分享给大家. [问题现象] 使用sphinx支持倒排索引,但sphinx从mysql查询源数据的时候,查询的记录数才几万条,但查询的速度非常慢,大概要4~5分钟左右 [处理过程] 1)explain 首先怀疑索引没有建好,于是使用explain查看查询计划,结果如下: 从explain的结果来看,整个语句的索引设计是没有问题的,除了第一个表因为业务需要进行整表扫描外,其它的表都是通过索引访问 2)show p
-
深入分析MySQL Sending data查询慢问题
通过一个实例给大家分享了MySQL Sending data表查询慢问题解决办法. 最近在代码优化中,发现了一条sql语句非常的慢,于是就用各种方法进行排查,最后终于找到了原因. 一.事故现场 SELECT og.goods_barcode, og.color_id, og.size_id, SUM(og.goods_number) AS sold_number FROM order o LEFT JOIN order_goods og ON o.order_id = og.order_id W
-
解决MySQL读写分离导致insert后select不到数据的问题
MySQL设置独写分离,在代码中按照如下写法,可能会出现问题 // 先录入 this.insert(obj); // 再查询 Object res = this.selectById(obj.getId()); res: null; 线上的一个坑,做了读写分离以后,有一个场景因为想方法复用,只传入一个ID就好,直接去库里查出一个对象再做后续处理,结果查不出来,事务隔离级别各种也都排查了,最后发现是读写分离的问题,所以换个思路去实现吧. 补充知识:MySQL INSERT插入条件判断:如果不存在则
-
解决MySQL中IN子查询会导致无法使用索引问题
今天看到一篇关于MySQL的IN子查询优化的案例, 一开始感觉有点半信半疑(如果是换做在SQL Server中,这种情况是绝对不可能的,后面会做一个简单的测试.) 随后动手按照他说的做了一个表来测试验证,发现MySQL的IN子查询做的不好,确实会导致无法使用索引的情况(IN子查询无法使用所以,场景是MySQL,截止的版本是5.7.18) MySQL的测试环境 测试表如下 create table test_table2 ( id int auto_increment primary key, p
-
解决Mysql多行子查询的使用及空值问题
目录 1 定义 2 多行比较操作符 3 空值问题 3.1 问题 3.2 解决 1 定义 也称为集合比较子查询 内查询返回多行 使用多行比较操作符 2 多行比较操作符 -- 多行子查询 -- IN SELECT employee_id, manager_id, department_id FROM employees WHERE manager_id IN ( -- 在返回集合中查找有没有相同的manager_id在里面 SELECT manager_id FROM employees WHERE
-
解决mysql安装时出现error Nr.1045问题的方法
我们在windows下安装MySQL时会出现Access denied for user 'root'@localhost'(using password:No)的问题,这个问题是因为你的机器上之前安装过mysql,或者这 一次安装配置了新密码,进入应用的最后一步时候由于某些原因卡出了或者由于服务未启动等原因导致无法配置成功,最终结果是,配置未成功,密码设置已经保存 进去了.这样我们调整好了服务等原因后,进行重新配置的时候,会发现在设置密码的时候,多了一个旧密码输入框.其实这也没什么,在密码知道
-
MySQL中SQL分页查询的几种实现方法及优缺点
[SQL]SQL分页查询总结 开发过程中经常遇到分页的需求,今天在此总结一下吧. 简单说来方法有两种,一种在源上控制,一种在端上控制.源上控制把分页逻辑放在SQL层:端上控制一次性获取所有数据,把分页逻辑放在UI上(如GridView).显然,端上控制开发难度低,适于小规模数据,但数据量增大时性能和IO消耗无法接受:源上控制在性能和开发难度上较为平衡,适应大多数业务场景:除此之外,还可以根据客观情况(性能要求,源与端的资源占用等)在源和端之间加一层,应用特殊算法和技术进行处理.以下主要讨论源上,
-
spring data jpa查询一个实体类的部分属性方式
目录 springdatajpa查询一个实体类的部分属性 首先我们定义两个实体类 然后创建person实体类的repository 返回结果只包含firstName和lastName两个属性 springdatajpa查询部分字段.多余附加字段 第一种方法:使用model查询时转化 第二种方法:在service里边转换成JSON 第三种方法:select语句部分字段使用默认值 spring data jpa查询一个实体类的部分属性 使用Spring Data Repository查询时候,通常情
-
Mysql查询很慢卡在sending data的原因及解决思路讲解
因为编写了一个Python程序,密集的操作了一个Mysql库,之前数据量不大时,没发现很慢,后来越来越慢,以为只是数据量大了的原因,但是后来慢到不能忍受了,查了半天,索引能用的都用上了,执行一次还是要3到4秒,不能忍受了. 于是把一些可以缓存的查询全部用redis缓存了起来,大大加速了应用. 但是还是有一些没办法缓存的,或者说,每次查询都是不一样的结果的就没办法了.用navicat的查询概况可以看到卡住的地方是在:Sending data一段,用时3.5秒,占了99%的查询时间. 在网上查了一些