Mongodb聚合函数count、distinct、group如何实现数据聚合操作
上篇文章给大家介绍了Mongodb中MapReduce实现数据聚合方法详解,我们提到过Mongodb中进行数据聚合操作的一种方式——MapReduce,但是在大多数日常使用过程中,我们并不需要使用MapReduce来进行操作。在这边文章中,我们就简单说说用自带的聚合函数进行数据聚合操作的实现。
MongoDB除了基本的查询功能之外,还提供了强大的聚合功能。Mongodb中自带的基本聚合函数有三种:count、distinct和group。下面我们分别来讲述一下这三个基本聚合函数。
(1)count
作用:简单统计集合中符合某种条件的文档数量。
使用方式:db.collection.count(<query>)或者db.collection.find(<query>).count()
参数说明:其中<query>是用于查询的目标条件。如果出了想限定查出来的最大文档数,或者想统计后跳过指定条数的文档,则还需要借助于limit,skip。
举例:
db.collection.find(<query>).limit();
db.collection.find(<query>).skip();
(2)distinct
作用:用于对集合中的文档针进行去重处理
使用方式:db,collection.distinct(field,query)
参数说明:field是去重字段,可以是单个的字段名,也可以是嵌套的字段名;query是查询条件,可以为空;
举例:
db.collection.distinct("user",{“age":{$gt:28}});//用于查询年龄age大于28岁的不同用户名
除了上面的用法外,还可以使用下面的另外一种方法:
db.runCommand({"distinct":"collectionname","key":"distinctfied","query":<query>})
collectionname:去重统计的集合名,distinctfield:去重字段,,<query>是可选的限制条件;
举例:
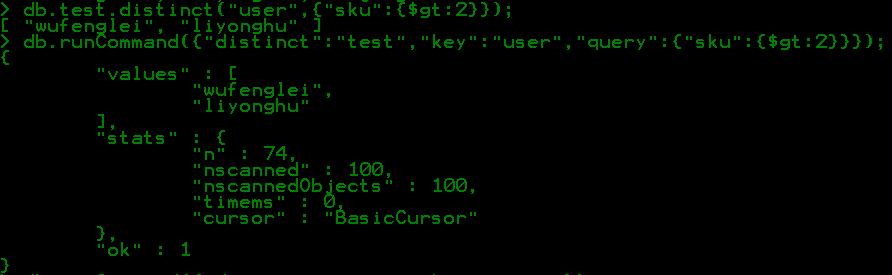
这两种方式的区别:第一种方法是对第二种方法的封装,第一种只返回去重统计后的字段值集合,但第二种方式既返回字段值集合也返回统计时的细节信息。
(3)group
作用:用于提供比count、distinct更丰富的统计需求,可以使用js函数控制统计逻辑
使用方式:db.collection.group(key,reduce,initial[,keyf][,cond][,finalize])
备注说明:在2.2版本之前,group操作最多只能返回10000条分组记录,但是从2.2版本之后到2.4版本,mongodb做了优化,能够支持返回20000条分组记录返回,如果分组记录的条数大于20000条,那么可能你就需要其他方式进行统计了,比如聚合管道或者MapReduce;
上面对Mongodb中自带的三种三种聚合函数进行了简单的描述,并对需要注意的地方进行了简单的说明,如果需要深入使用,可以进入Mongodb官网查看相关细节信息,谢谢。
相关推荐
-
MongoDB的聚合框架Aggregation Framework入门学习教程
1. 聚合框架 使用聚合框架对集合中的文档进行变换和组合,可以用多个构件创建一个管道(pipeline),用于对一连串的文档进行处理.这些构件包括筛选(filtering),投射(projecting),分组(grouping),排序(sorting),限制(limiting),跳过(skipping). 例如一个保存着动物类型的集合,希望找出最多的那种动物,假设每种动物被保存为一个mongodb文档,可以按照以下步骤创建管道. 1)将每个文档的动物名称映射出来. 2)安装名称排序,统计每个名称
-

mongodb聚合_动力节点Java学院整理
今天跟大家分享一下mongodb中比较好玩的知识,主要包括:聚合,游标. 一:聚合 常见的聚合操作跟sql server一样,有:count,distinct,group,mapReduce. <1> count count是最简单,最容易,也是最常用的聚合工具,它的使用跟我们C#里面的count使用简直一模一样. <2> distinct 这个操作相信大家也是非常熟悉的,指定了谁,谁就不能重复,直接上图. <3> group 在mongodb里面做group操作有点小
-
MongoDB教程之聚合(count、distinct和group)
1. count: 复制代码 代码如下: --在空集合中,count返回的数量为0. > db.test.count() 0 --测试插入一个文档后count的返回值. > db.test.insert({"test":1}) > db.test.count() 1 > db.test.insert({"test":2}) > db.test.count() 2
-
Mongodb中MapReduce实现数据聚合方法详解
Mongodb是针对大数据量环境下诞生的用于保存大数据量的非关系型数据库,针对大量的数据,如何进行统计操作至关重要,那么如何从Mongodb中统计一些数据呢? 在Mongodb中,给我们提供了三种用于数据聚合的方式: (1)简单的用户聚合函数: (2)使用aggregate进行统计: (3)使用mapReduce进行统计: 今天我们首先来讲讲mapReduce是如何统计,在后续的文章中,将另起文章进行相关说明. MapReduce是啥呢?以我的理解,其实就是对集合中的各个满足条件的文档进行预处理
-
MongoDB聚合功能浅析
MongoDB数据库功能强大!除了基本的查询功能之外,还提供了强大的聚合功能.这里简单介绍一下count.distinct和group. 1.count: --在空集合中,count返回的数量为0. > db.test.count() 0 --测试插入一个文档后count的返回值. > db.test.insert({"test":1}) > db.test.count() 1 > db.test.insert({"test":2}) >
-
MongoDB入门教程之聚合和游标操作介绍
今天跟大家分享一下mongodb中比较好玩的知识,主要包括:聚合,游标. 一: 聚合 常见的聚合操作跟sql server一样,有:count,distinct,group,mapReduce. <1> count count是最简单,最容易,也是最常用的聚合工具,它的使用跟我们C#里面的count使用简直一模一样. <2> distinct 这个操作相信大家也是非常熟悉的,指定了谁,谁就不能重复,直接上图. <3> group 在mongodb里面做group操作
-
SQL分组函数group by和聚合函数(COUNT、MAX、MIN、AVG、SUM)的几点说明
1 分组聚合的原因 SQL中分组函数和聚合函数之前的文章已经介绍过,单说这两个函数有可能比较好理解,分组函数就是group by,聚合函数就是COUNT.MAX.MIN.AVG.SUM. 拿上图中的数据进行解释,假设按照product_type这个字段进行分组,分组之后结果如下图. SELECT product_type from productgroup by product_type 从图中可以看出被分为了三组,分别为厨房用具.衣服和办公用品,就相当于对product_type这个字段进行了
-
Mongodb聚合函数count、distinct、group如何实现数据聚合操作
上篇文章给大家介绍了Mongodb中MapReduce实现数据聚合方法详解,我们提到过Mongodb中进行数据聚合操作的一种方式--MapReduce,但是在大多数日常使用过程中,我们并不需要使用MapReduce来进行操作.在这边文章中,我们就简单说说用自带的聚合函数进行数据聚合操作的实现. MongoDB除了基本的查询功能之外,还提供了强大的聚合功能.Mongodb中自带的基本聚合函数有三种:count.distinct和group.下面我们分别来讲述一下这三个基本聚合函数. (1)coun
-
MySQL中聚合函数count的使用和性能优化技巧
本文的环境是Windows 10,MySQL版本是5.7.12-log 一. 基本使用 count的基本作用是有两个: 统计某个列的数据的数量: 统计结果集的行数: 用来获取满足条件的数据的数量.但是其中有一些与使用中印象不同的情况,比如当count作用一列.多列.以及使用*来表达整行产生的效果是不同的. 示例表如下: CREATE TABLE `NewTable` ( `id` int(11) NULL DEFAULT NULL , `name` varchar(30) NULL DEFAUL
-
Django 聚合函数的具体使用
前言 orm模型中的聚合函数跟MySQL中的聚合函数作用是一致的,也有像Sum.Avg.Count.Max.Min,接下来我们逐个介绍 聚合函数 所有的聚合函数都是放在django.db.models下面.并且聚合函数不能够单独的执行,聚合函数是通过aggregate方法来实现的.在说明聚合函数的用法的时候,都是基于以下的模型对象来实现的. class Author(models.Model): """作者模型""" name = models.
-
SQL学习笔记四 聚合函数、排序方法
聚合函数 count,max,min,avg,sum... select count (*) from T_Employee select Max(FSalary) from T_Employee 排序 ASC升序 DESC降序 select * from T_Employee order by Fage 先按年龄降序排列.如果年龄相同,则按薪水升序排列 select * from T_Employee order by FAge DESC,FSalary ASC order by 要放在 wh
-
Sequelize中用group by进行分组聚合查询
一.SQL与Sequelize中的分组查询 1.1 SQL中的分组查询 SQL查询中,通GROUP BY语名实现分组查询.GROUP BY子句要和聚合函数配合使用才能完成分组查询,在SELECT查询的字段中,如果没有使用聚合函数就必须出现在ORDER BY子句中.分组查询后,查询结果为一个或多个列分组后的结果集. GROUP BY语法 SELECT 列名, 聚合函数(列名) FROM 表名 WHERE 列名 operator value GROUP BY 列名 [HAVING 条件表达式] [W
-
深入了解MySQL中聚合函数的使用
目录 什么是聚合函数 SUM 函数 MAX 函数 MIN 函数 AVG 函数 COUNT 函数 聚合函数综合小练习 聚合函数综合练习 -1 聚合函数综合练习 -2 今天的章节我们将要来学习一下 “聚合函数” :首先我们需要学习聚合函数对数据进行统计分析,比如说求最大值.最小值.平均值之类的场景.但是单纯的使用聚合函数,只能做全表范围的统计分析.如果想要把记录分组分别统计,需要使用 “GROUP BY” 和 “HAVING” 这样的分组子句了.关于分组查询的应用,将在下一章节为大家进行讲解.当前章
-
Django Model层F,Q对象和聚合函数原理解析
一.F对象: 作用:用于处理类属性(即model的某个列数据),类属性之间的比较. 使用之前需要先导入: from django.db.models import F 例1:查询图书阅读量大于评论量图书信息. BookInfo.objects.filter(bread__gt=F('bcomment')) **例2:**查询图书 阅读量大于2倍评论 量图书信息. BookInfo.objects.filter(bread__gt=F('bcomment')*2) 二.Q对象: 作用:用于查询时条
-
Mysql聚合函数的使用介绍
目录 前言 什么是聚合函数 SUM 函数 count max与min sum avg 总结 前言 聚合函数用来对表中的数据进行统计和计算.users表结构如下: 什么是聚合函数 聚合函数是用来做简单的数据统计的,比如说统计一下 “员工表” 中的平均工龄是多少年啊,员工表中一共有多少条记录等等… 这些都需要使用到聚合函数. 聚合函数也被称为 “汇总函数” ,在数据的查询分析中,应用的十分广泛.可以帮助我们实现对数据的求和.求最大值.求最小值.求平均值等等. 如果不指定统计的范围,那么聚合函数统计的
-
Python Pandas聚合函数的应用示例
目录 Python Pandas聚合函数 应用聚合函数 1) 对整体聚合 2) 对任意某一列聚合 3) 对多列数据聚合 4) 对单列应用多个函数 5) 对不同列应用多个函数 6) 对不同列应用不同函数 总结 Python Pandas聚合函数 在前一节,我们重点介绍了窗口函数.我们知道,窗口函数可以与聚合函数一起使用,聚合函数指的是对一组数据求总和.最大值.最小值以及平均值的操作,本节重点讲解聚合函数的应用. 应用聚合函数 首先让我们创建一个 DataFrame 对象,然后对聚合函数进行应用.