浅析SQL Server中的执行计划缓存(上)
简介
我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径。当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse)、绑定(Bind)、查询优化(Optimization,有时候也被称为简化)、执行(Execution)。除去执行步骤外,前三个步骤之后就生成了执行计划,也就是SQL Server按照该计划获取物理数据方式,最后执行步骤按照执行计划执行查询从而获得结果。但查询优化器不是本篇的重点,本篇文章主要讲述查询优化器在生成执行计划之后,缓存执行计划的相关机制以及常见问题。
为什么需要执行计划缓存
从简介中我们知道,生成执行计划的过程步骤所占的比例众多,会消耗掉各CPU和内存资源。而实际上,查询优化器生成执行计划要做更多的工作,大概分为3部分:
首先,根据传入的查询语句文本,解析表名称、存储过程名称、视图名称等。然后基于逻辑数据操作生成代表查询文本的树。
第二步是优化和简化,比如说将子查询转换成对等的连接、优先应用过滤条件、删除不必要的连接(比如说有索引,可能不需要引用原表)等。
第三步根据数据库中的统计信息,进行基于成本(Cost-based)的评估。
上面三个步骤完成之后,才会生成多个候选执行计划。虽然我们的SQL语句逻辑上只有一个,但是符合这个逻辑顺序的物理获取数据的顺序却可以有多条,打个比方,你希望从北京到上海,即可以做高铁,也可以做飞机,但从北京到上海这个描述是逻辑描述,具体怎么实现路径有多条。那让我们再看一个SQL Server中的举例,比如代码清单1中的查询。
SELECT * FROM A INNER JOIN B ON a.a=b.b INNER JOIN C ON c.c=a.a
代码清单1.
对于该查询来说,无论A先Inner join B还是B先Inner Join C,结果都是一样的,因此可以生成多个执行计划,但一个基本原则是SQL Server不一定会选择最好的执行计划,而是选择足够好的计划,这是由于评估所有的执行计划的成本所消耗的成本不应该过大。最终,SQL Server会根据数据的基数和每一步所消耗的CPU和IO的成本来评估执行计划的成本,所以执行计划的选择重度依赖于统计信息,关于统计信息的相关内容,我就不细说了。
对于前面查询分析器生成执行计划的过程不难看出,该步骤消耗的资源成本也是惊人的。因此当同样的查询执行一次以后,将其缓存起来将会大大减少执行计划的编译,从而提高效率,这就是执行计划缓存存在的初衷。
执行计划所缓存的对象
执行计划所缓存的对象分为4类,分别是:
编译后的计划:编译的执行计划和执行计划的关系就和MSIL和C#的关系一样。
执行上下文:在执行编译的计划时,会有上下文环境。因为编译的计划可以被多个用户共享,但查询需要存储SET信息以及本地变量的值等,因此上下文环境需要对应执行计划进行关联。执行上下文也被称为Executable Plan。
游标:存储的游标状态类似于执行上下文和编译的计划的关系。游标本身只能被某个连接使用,但游标关联的执行计划可以被多个用户共享。
代数树:代数树(也被称为解析树)代表着查询文本。正如我们之前所说,查询分析器不会直接引用查询文本,而是代数树。这里或许你会有疑问,代数树用于生成执行计划,这里还缓存代数树干毛啊?这是因为视图、Default、约束可能会被不同查询重复使用,将这些对象的代数树缓存起来省去了解析的过程。
比如说我们可以通过dm_exec_cached_plans这个DMV找到被缓存的执行计划,如图1所示。
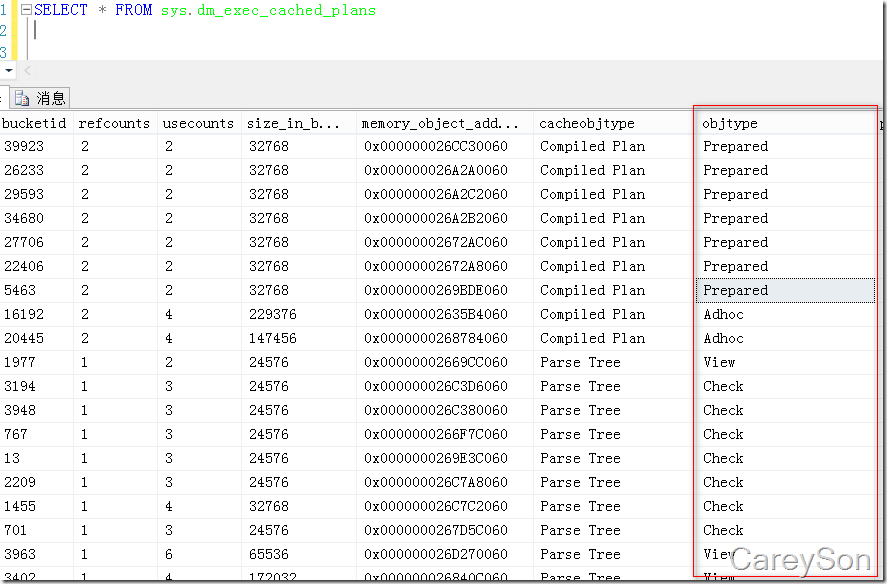
图1.被缓存的执行计划
那究竟这几类对象缓存所占用的内存相关信息该怎么看呢?我们可以通过dm_os_memory_cache_counters这个DMV看到,上述几类被缓存的对象如图2所示。
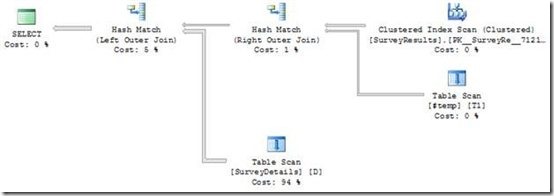
图2.在内存中这几类对象缓存所占用的内存
另外,执行计划缓存是一种缓存。而缓存中的对象会根据算法被替换掉。对于执行计划缓存来说,被替换的算法主要是基于内存压力。而内存压力会被分为两种,既内部压力和外部压力。外部压力是由于Buffer Pool的可用空间降到某一临界值(该临界值会根据物理内存的大小而不同,如果设置了最大内存则根据最大内存来)。内部压力是由于执行计划缓存中的对象超过某一个阈值,比如说32位的SQL Server该阈值为40000,而64位中该值被提升到了160000。
这里重点说一下,缓存的标识符是查询语句本身,因此select * from SchemaName.TableName和Select * from TableName虽然效果一致,但需要缓存两份执行计划,所以一个Best Practice是在引用表名称和以及其他对象的名称时,请带上架构名称。
基于被缓存的执行计划对语句进行调优
被缓存的执行计划所存储的内容非常丰富,不仅仅包括被缓存的执行计划、语句,还包括被缓存执行计划的统计信息,比如说CPU的使用、等待时间等。但这里值得注意的是,这里的统计只算执行时间,而不算编译时间。比如说我们可以利用代码清单2中的代码根据被缓存的执行计划找到数据库中耗时最长的20个查询语句。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT TOP 20
CAST(qs.total_elapsed_time / 1000000.0 AS DECIMAL(28, 2))
AS [Total Duration (s)]
, CAST(qs.total_worker_time * 100.0 / qs.total_elapsed_time
AS DECIMAL(28, 2)) AS [% CPU]
, CAST((qs.total_elapsed_time - qs.total_worker_time)* 100.0 /
qs.total_elapsed_time AS DECIMAL(28, 2)) AS [% Waiting]
, qs.execution_count
, CAST(qs.total_elapsed_time / 1000000.0 / qs.execution_count
AS DECIMAL(28, 2)) AS [Average Duration (s)]
, SUBSTRING (qt.text,(qs.statement_start_offset/2) + 1,
((CASE WHEN qs.statement_end_offset = -1
THEN LEN(CONVERT(NVARCHAR(MAX), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS [Individual Query
, qt.text AS [Parent Query]
, DB_NAME(qt.dbid) AS DatabaseName
, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
WHERE qs.total_elapsed_time > 0
ORDER BY qs.total_elapsed_time DESC
代码清单2.通过执行计划缓存找到数据库总耗时最长的20个查询语句
上面的语句您可以修改Order By来根据不同的条件找到你希望找到的语句,这里就不再细说了。
相比较于无论是服务端Trace还是客户端的Profiler,该方法有一定优势,如果通过捕捉Trace再分析的话,不仅费时费力,还会给服务器带来额外的开销,通过该方法找到耗时的查询语句就会简单很多。但是该统计仅仅基于上次实例重启或者没有运行DBCC FreeProcCache之后。但该方法也有一些弊端,比如说:
类似索引重建、更新统计信息这类语句是不缓存的,而这些语句成本会非常高。
缓存可能随时会被替换掉,因此该方法无法看到不再缓存中的语句。
该统计信息只能看到执行成本,无法看到编译成本。
没有参数化的缓存可能同一个语句呈现不同的执行计划,因此出现不同的缓存,在这种情况下统计信息无法累计,可能造成不是很准确。
执行计划缓存和查询优化器的矛盾
还记得我们之前所说的吗,执行计划的编译和选择分为三步,其中前两步仅仅根据查询语句和表等对象的metadata,在执行计划选择的阶段要重度依赖于统计信息,因此同一个语句仅仅是参数的不同,查询优化器就会产生不同的执行计划,比如说我们来看一个简单的例子,如图3所示。
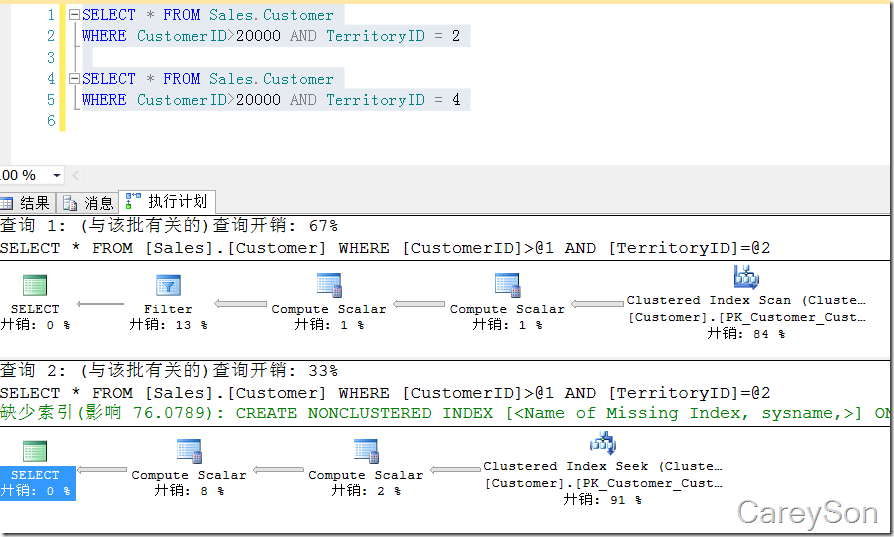
图3.仅仅是由于不同的参数,查询优化器选择不同的执行计划
大家可能会觉得,这不是挺好的嘛,根据参数产生不同的执行计划。那让我们再考虑一个问题,如果将上面的查询放到一个存储过程中,参数不能被直接嗅探到,当第一个执行计划被缓存后,第二次执行会复用第一次的执行计划!虽然免去了编译时间,但不好的执行计划所消耗的成本会更高!让我们来看这个例子,如图4所示。
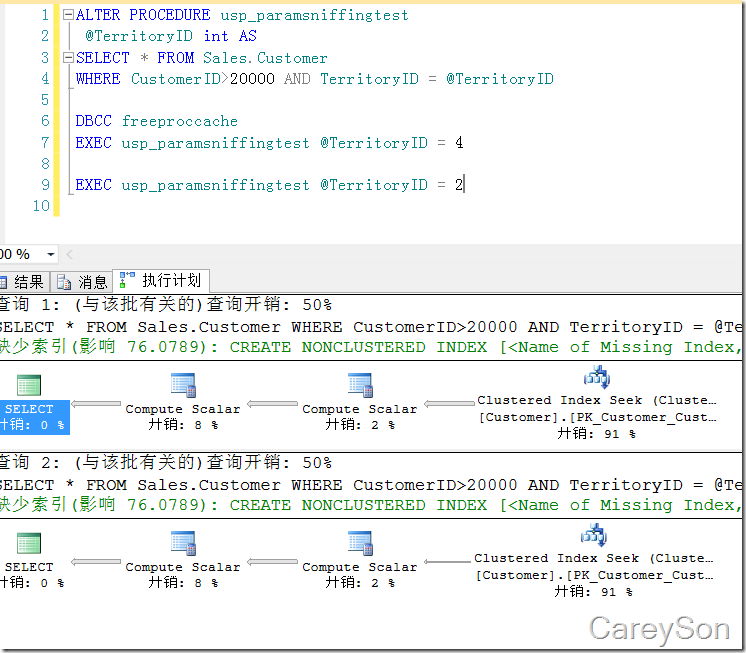
图4.不同的参数,却是完全一样的执行计划!
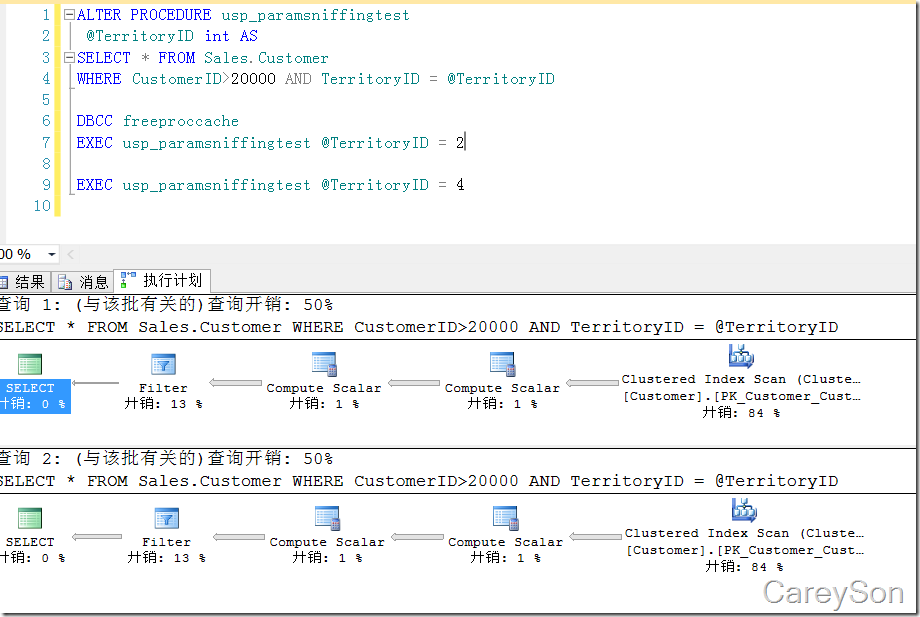
再让我们看同一个例子,把执行顺序颠倒后,如图5所示。
图5.执行计划完全变了
我们看到,第二次执行的语句,完全复用了第一次的执行计划。那总会有一个查询牺牲。比如说当参数为4时会有5000多条,此时索引扫描应该最高效,但图4却复用了上一个执行计划,使用了5000多次查找!!!这无疑是低效率的。而且这种情况出现会非常让DBA迷茫,因为在缓存中的执行计划不可控,缓存中的对象随时可能被删除,谁先执行谁后执行产生的性能问题往往也让DBA头疼。
由这个例子我们看出,查询优化器希望尽可能选择高效的执行计划,而执行计划缓存却希望尽可能的重用缓存,这两种机制在某些情况会产生冲突。
在下篇文章中,我们将会继续来看由于执行计划缓存和查询分析器的冲突,以及编译执行计划所带来的常见问题和解决方案。
小结
本篇文章中,我们简单讲述了查询优化器生成执行计划的过程,以及执行计划缓存的机制。当查询优化器和执行计划缓存以某种不好的情况交汇时,将产生一些问题。在下篇文章中,我们会继续探索SQL Server中的执行计划缓存。
以上内容是小编给大家介绍的SQL Server中的执行计划缓存(上)的全部叙述,希望大家喜欢。
相关推荐
-

SqlServer 执行计划及Sql查询优化初探
网上的SQL优化的文章实在是很多,说实在的,我也曾经到处找这样的文章,什么不要使用IN了,什么OR了,什么AND了,很多很多,还有很多人拿出仅几S甚至几MS的时间差的例子来证明着什么(有点可笑),让许多人不知道其是对还是错.而SQL优化又是每个要与数据库打交道的程序员的必修课,所以写了此文,与朋友们共勉. 谈到优化就必然要涉及索引,就像要讲锁必然要说事务一样,所以你需要了解一下索引,仅仅是索引,就能讲半天了,所以索引我就不说了(打很多字是很累的,况且我也知之甚少),可以去参考相关的文章,这个网上
-
浅析SQL Server中的执行计划缓存(下)
在上篇文章给大家介绍了SQL Server中的执行计划缓存(上),本文继续给大家介绍sqlserver执行计划缓存相关知识,小伙伴们一起学习吧. 简介 在上篇文章中我们谈到了查询优化器和执行计划缓存的关系,以及其二者之间的冲突.本篇文章中,我们会主要阐述执行计划缓存常见的问题以及一些解决办法. 将执行缓存考虑在内时的流程 上篇文章中提到了查询优化器解析语句的过程,当将计划缓存考虑在内时,首先需要查看计划缓存中是否已经有语句的缓存,如果没有,才会执行编译过程,如果存在则直接利用编译好的执行计划.因
-
浅析SQL Server的聚焦使用索引和查询执行计划
前言 上一篇<浅析SQL Server 聚焦索引对非聚集索引的影响>我们讲了聚集索引对非聚集索引的影响,对数据库一直在强调的性能优化,所以这一节我们统筹讲讲利用索引来看看查询执行计划是怎样的,简短的内容,深入的理解. 透过索引来看查询执行计划 我们首先来看看第一个例子 1.默认使用索引 USE TSQL2012 GO SELECT orderid FROM Sales.Orders SELECT * FROM Sales.Orders 上述我们看到第2个查询的所需要的开销是第1个查询开销的3倍
-
SQL Server中参数化SQL写法遇到parameter sniff ,导致不合理执行计划重用的快速解决方法
parameter sniff问题是重用其他参数生成的执行计划,导致当前参数采用该执行计划非最优化的现象.想必熟悉数据的同学都应该知道,产生parameter sniff最典型的问题就是使用了参数化的SQL(或者存储过程中使用了参数化)写法,如果存在数据分布不均匀的情况下,正常情况下生成的执行计划,在传入在分布数据较多的参数的情况下,重用了正常参数生成的执行计划,而这种缓存的执行计划并非适合当前参数的一种情况. 这种情况,在实际业务中,出现的频率还是比较高的,因为存储过程一般都是采用参数化的写法
-
浅析SQL Server 聚焦索引对非聚集索引的影响
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一个思考的过程,无论是独立思考也好还是查资料也罢都是思考而非走马观花,要不然过一段时间又会健忘.简短的内容,深入的理解. 话题 非聚集索引定义:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.你真的理解了吗??你能举出例子吗?
-
强制SQL Server执行计划使用并行提升在复杂查询语句下的性能
通过观察执行计划,发现之前的执行计划在很多大表连接的部分使用了Hash Join,由于涉及的表中数据众多,因此查询优化器选择使用并行执行,速度较快.而我们优化完的执行计划由于索引的存在,且表内数据非常大,过滤条件的值在一个很宽的统计信息步长范围内,导致估计行数出现较大偏差(过滤条件实际为15000行,步长内估计的平均行数为800行左右),因此查询优化器选择了Loop Join,且没有选择并行执行,因此执行时间不降反升. 由于语句是在存储过程中实现,因此我们直接对该语句使用一个undocument
-
SQLSERVER中得到执行计划的两种方式
得到执行计划的方式有两种: 1.一种是在指令的前面打开一些开关,让执行计划信息打在结果集里,这种方法比较适合在一个测试环境里对单个语句调优. 这些开关最常用的有 复制代码 代码如下: SET SHOWPLAN_ALL ON SET SHOWPLAN_ALL ON --(是不是reuse了一个执行计划,SQSERVERL有没有觉得缺少索引),只能在XML的输出里看到 SET STATISTICS PROFILE ON 还有如果使用SSMS的话,可以用快捷键:Ctrl+L 小写L 他会执行你的语句并
-
MySQL中主键索引与聚焦索引之概念的学习教程
主键索引 主键索引,简称主键,原文是PRIMARY KEY,由一个或多个列组成,用于唯一性标识数据表中的某一条记录.一个表可以没有主键,但最多只能有一个主键,并且主键值不能包含NULL. 在MySQL中,InnoDB数据表的主键设计我们通常遵循几个原则: 采用一个没有业务用途的自增属性列作为主键: 主键字段值总是不更新,只有新增或者删除两种操作: 不选择会动态更新的类型,比如当前时间戳等. 这么做的好处有几点: 新增数据时,由于主键值是顺序增长的,innodb page发生分裂的概率降低了:可以
-
浅析SQL Server中的执行计划缓存(上)
简介 我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径.当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse).绑定(Bind).查询优化(Optimization,有时候也被称为简化).执行(Execution).除去执行步骤外,前三个步骤之后就生成了执行计划,也就是SQL Server按照该计划获取物理数据方式,最后执行步骤按照执行计划执行查询从而获得结果.但查询优化器不是本篇的重点,本篇文章主要讲述查询优化器在生成执行计划之
-
SQL Server中的执行引擎入门 图解
本文旨在分类讲述执行计划中每一种操作的相关信息. 数据访问操作 首先最基本的操作就是访问数据.这既可以通过直接访问表,也可以通过访问索引来进行.表内数据的组织方式分为堆(Heap)和B树,其中表中没有建立聚集索引时数据是通过堆进行组织的,这个是无序的,表中建立聚集索引后和非聚集索引的数据都是以B树方式进行组织,这种方式数据是有序存储的.通常来说,非聚集索引仅仅包含整个表的部分列,对于过滤索引,还仅仅包含部分行. 除去数据的组织方式不同外,访问数据也分为两种方式,扫描(Scan)和查找(Seek)
-
浅析SQL Server中包含事务的存储过程
先来看一个概念: 数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作,要么完整地执行,要么完全地不执行.那么在存储过程里添加事务,则可以保证该事务里的所有sql代码要么完全执行要么完全不执行. 举个简单的带事务的存储过程: Begin Set NOCOUNT ON; --不返回影响行数 Set XACT_ABORT ON; --使用存储过程执行事务需要开启XACT_ABORT参数(默认为OFF) delete from table1 where n
-
SQL SERVER 中构建执行动态SQL语句的方法
1 :普通SQL语句可以用exec执行 Select * from tableName exec('select * from tableName') exec sp_executesql N'select * from tableName' -- 请注意字符串前一定要加N 2:字段名,表名,数据库名之类作为变量时,必须用动态SQL declare @fname varchar(20) set @fname = 'FiledName' --Select @fname from tableName
-
SQL Server中的文件和文件组介绍
文件和文件组简介 在SQL Server中,数据库在硬盘上的存储方式和普通文件在Windows中的存储方式没有什么不同,仅仅是几个文件而已.SQL Server通过管理逻辑上的文件组的方式来管理文件. SQL Server通过文件组对数据文件进行管理.我们看到的逻辑数据库由一个或者多个文件组构成. 结构图如下: 文件组管理着磁盘上的文件,文件中存放的就是SQL Server的实际数据. 为什么通过文件组来管理文件 从用户的角度来说,创建对象时需要指定存储文件组的只有三种数据对象:表,索引和大对象
-
sql server中Select count(*)和Count(1)的区别和执行方式
在SQL Server中Count(*)或者Count(1)或者Count([列])或许是最常用的聚合函数.很多人其实对这三者之间是区分不清的.本文会阐述这三者的作用,关系以及背后的原理. 往常我经常会看到一些所谓的优化建议不使用Count(* )而是使用Count(1),从而可以提升性能,给出的理由是Count( *)会带来全表扫描.而实际上如何写Count并没有区别. Count(1)和Count(*)实际上的意思是,评估Count()中的表达式是否为NULL,如果为NULL则不计数,而非N
-
浅析SQL Server的嵌套存储过程中使用同名的临时表怪像
SQL Server的嵌套存储过程,外层存储过程和内层存储过程(被嵌套调用的存储过程)中可以存在相同名称的本地临时表吗?如果可以的话,那么有没有什么问题或限制呢? 在嵌套存储过程中,调用的是外层存储过程的临时表还是自己定义的临时表呢? 是否类似高级语言的变量一样,本地临时表有没有"作用域"范围呢? 注意:也可以称呼为父存储过程和子存储过程,外层存储过程和内层存储过程.这些只是不同的称呼或叫法而已.我们这里统一使用外层存储过程和内层存储过程.后续文章部分不再述说. 我们先来看一个例子,如