java多线程抓取铃声多多官网的铃声数据
一直想练习下java多线程抓取数据。
有天被我发现,铃声多多的官网(http://www.shoujiduoduo.com/main/)有大量的数据。
通过观察他们前端获取铃声数据的ajax
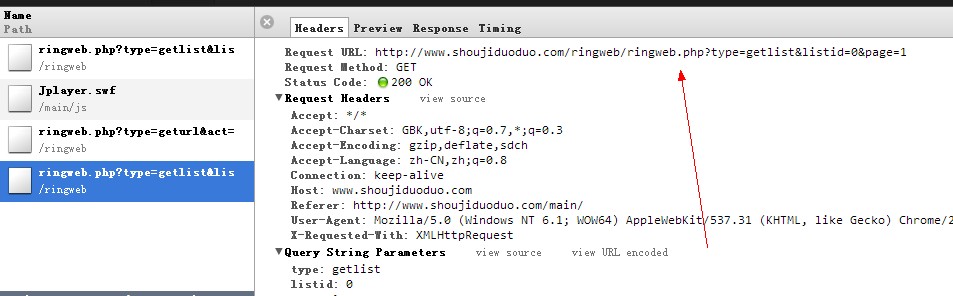
http://www.shoujiduoduo.com/ringweb/ringweb.php?type=getlist&listid={类别ID}&page={分页页码}
很容易就能发现通过改变 listId和page就能从服务器获取铃声的json数据, 通过解析json数据,
可以看到都带有{"hasmore":1,"curpage":1}这样子的指示,通过判断hasmore的值,决定是否进行下一页的抓取。
但是通过上面这个链接返回的json中不带有铃声的下载地址
很快就可以发现,点击页面的“下载”会看到
通过下面的请求,就可以获取铃声的下载地址了
http://www.shoujiduoduo.com/ringweb/ringweb.php?type=geturl&act=down&rid={铃声ID}

所以,他们的数据是很容易被偷的。于是我就开始...
源码已经发在github上。如果感兴趣的童鞋可以查看
github:https://github.com/yongbo000/DuoduoAudioRobot
上代码:
package me.yongbo.DuoduoRingRobot;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonParser;
/* * @author yongbo_ * @created 2013/4/16 * * */
public class DuoduoRingRobotClient implements Runnable {
public static String GET_RINGINFO_URL = "http://www.shoujiduoduo.com/ringweb/ringweb.php?type=getlist&listid=%1$d&page=%2$d";
public static String GET_DOWN_URL = "http://www.shoujiduoduo.com/ringweb/ringweb.php?type=geturl&act=down&rid=%1$d";
public static String ERROR_MSG = "listId为 %1$d 的Robot发生错误,已自动停止。当前page为 %2$d";public static String STATUS_MSG = "开始抓取数据,当前listId: %1$d,当前page: %2$d";
public static String FILE_DIR = "E:/RingData/";public static String FILE_NAME = "listId=%1$d.txt";private boolean errorFlag = false;private int listId;private int page;
private int endPage = -1;private int hasMore = 1;
private DbHelper dbHelper;
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * @param endPage 结束页码 * */
public DuoduoRingRobotClient(int listId, int beginPage, int endPage)
{this.listId = listId;this.page = beginPage;this.endPage = endPage;this.dbHelper = new DbHelper();}
/** * 构造函数 * @param listId 菜单ID * @param page 开始页码 * */
public DuoduoRingRobotClient(int listId, int page) {this(listId, page, -1);}
/** * 获取铃声 * */public void getRings() {String url = String.format(GET_RINGINFO_URL, listId, page);String responseStr = httpGet(url);hasMore = getHasmore(responseStr);
page = getNextPage(responseStr);
ringParse(responseStr.replaceAll("\\{\"hasmore\":[0-9]*,\"curpage\":[0-9]*\\},", "").replaceAll(",]", "]"));}/** * 发起http请求 * @param webUrl 请求连接地址 * */public String httpGet(String webUrl){URL url;URLConnection conn;StringBuilder sb = new StringBuilder();String resultStr = "";try {url = new URL(webUrl);conn = url.openConnection();conn.connect();InputStream is = conn.getInputStream();InputStreamReader isr = new InputStreamReader(is);BufferedReader bufReader = new BufferedReader(isr);String lineText;while ((lineText = bufReader.readLine()) != null) {sb.append(lineText);}resultStr = sb.toString();} catch (Exception e) {errorFlag = true;//将错误写入txtwriteToFile(String.format(ERROR_MSG, listId, page));}return resultStr;}/** * 将json字符串转化成Ring对象,并存入txt中 * @param json Json字符串 * */public void ringParse(String json) {Ring ring = null;JsonElement element = new JsonParser().parse(json);JsonArray array = element.getAsJsonArray();// 遍历数组Iterator<JsonElement> it = array.iterator();
Gson gson = new Gson();while (it.hasNext() && !errorFlag) {JsonElement e = it.next();// JsonElement转换为JavaBean对象ring = gson.fromJson(e, Ring.class);ring.setDownUrl(getRingDownUrl(ring.getId()));if(isAvailableRing(ring)) {System.out.println(ring.toString());
//可选择写入数据库还是写入文本//writeToFile(ring.toString());writeToDatabase(ring);}}}
/** * 写入txt * @param data 字符串 * */public void writeToFile(String data)
{String path = FILE_DIR + String.format(FILE_NAME, listId);File dir = new File(FILE_DIR);File file = new File(path);FileWriter fw = null;if(!dir.exists()){dir.mkdirs();
}try {if(!file.exists()){file.createNewFile();}fw = new FileWriter(file, true);
fw.write(data);fw.write("\r\n");fw.flush();} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();
}finally {try {if(fw != null){fw.close();}} catch (IOException e) {
// TODO Auto-generated catch blocke.printStackTrace();}}}/** * 写入数据库 * @param ring 一个Ring的实例 * */
public void writeToDatabase(Ring ring) {dbHelper.execute("addRing", ring);}
@Overridepublic void run() {while(hasMore == 1 && !errorFlag){if(endPage != -1){if(page > endPage) { break; }}System.out.println(String.format(STATUS_MSG, listId, page));
getRings();System.out.println(String.format("该页数据写入完成"));}System.out.println("ending...");}
private int getHasmore(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");
Matcher match = p.matcher(resultStr);
if (match.find()) { return Integer.parseInt(match.group(1));
} return 0;
}
private int getNextPage(String resultStr){Pattern p = Pattern.compile("\"hasmore\":([0-9]*),\"curpage\":([0-9]*)");Matcher match = p.matcher(resultStr);if (match.find()) {return Integer.parseInt(match.group(2));}return 0;}
/** * 判断当前Ring是否满足条件。当Ring的name大于50个字符或是duration为小数则不符合条件,将被剔除。 * @param ring 当前Ring对象实例 * */private boolean isAvailableRing(Ring ring){Pattern p = Pattern.compile("^[1-9][0-9]*$");
Matcher match = p.matcher(ring.getDuration());
if(!match.find()){return false;}if(ring.getName().length() > 50 || ring.getArtist().length() > 50 || ring.getDownUrl().length() == 0){return false;}return true;}
/** * 获取铃声的下载地址 * @param rid 铃声的id * */
public String getRingDownUrl(String rid){String url = String.format(GET_DOWN_URL, rid);
String responseStr = httpGet(url);return responseStr;}}
相关推荐
-
java在网页上面抓取邮件地址的方法
本文实例讲述了java在网页上面抓取邮件地址的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.URL; import java.util.regex.Matcher; import java.util.regex.Pattern; public class h1 { public stati
-

java利用url实现网页内容的抓取
闲来无事,刚学会把git部署到远程服务器,没事做,所以简单做了一个抓取网页信息的小工具,里面的一些数值如果设成参数的话可能扩展性能会更好!希望这是一个好的开始把,也让我对字符串的读取掌握的更加熟练了,值得注意的是JAVA1.8 里面在使用String拼接字符串的时候,会自动把你要拼接的字符串用StringBulider来处理,大大优化了String 的性能,闲话不多说,show my XXX code- 运行效果: 首先打开百度百科,搜索词条,比如"演员",再按F12查看源码 然后抓取
-
JAVA使用爬虫抓取网站网页内容的方法
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法.分享给大家供大家参考.具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下: // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar
-
java抓取网页数据示例
下面举例说明: 抓取百度首页的内容: 复制代码 代码如下: URL url = new URL("http://www.baidu.com");HttpURLConnection urlCon=(HttpURLConnection)url.openConnection();urlCon.setConnectTimeout(50000);urlCon.setReadTimeout(300000);DataInputStream fIn;byte[] content = new byte[
-
Java模拟新浪微博登陆抓取数据
前言: 兄弟们来了来了,最近有人在问如何模拟新浪微博登陆抓取数据,我听后默默地抽了一口老烟,暗暗的对自己说,老汉是时候该你出场了,所以今天有时间就整理整理,浅谈一二. 首先: 要想登陆新浪微博需要预登陆,即是将账号base64加密,密码rsa加密以及请求http://login.sina.com.cn/sso/prelogin.php链接获取一些登陆需要参数,返回的接送字符串如: {"retcode":0,"servertime":1487292003,"
-
java 抓取网页内容实现代码
复制代码 代码如下: package test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.Authenticator; import java.net.HttpURLConnection; import java.net.PasswordAuthentication
-
java简单网页抓取的实现方法
本文实例讲述了java简单网页抓取的实现方法.分享给大家供大家参考.具体分析如下: 背景介绍 一 tcp简介 1 tcp 实现网络中点对点的传输 2 传输是通过ports和sockets ports提供了不同类型的传输(例如 http的port是80) 1)sockets可以绑定在特定端口上,并且提供传输功能 2)一个port可以连接多个socket 二 URL简介 URL 是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址. 互联网上的每个文件都有一个唯一的
-
java抓取网页数据获取网页中所有的链接实例分享
效果图 复制代码 代码如下: import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.URL;import java.util.ArrayList;import java.util.regex.Matcher;import java.util.regex.Pattern; p
-
详解Java实现多种方式的http数据抓取
前言: 时下互联网第一波的浪潮已消逝,随着而来的基于万千数据的物联网时代,因而数据成为企业的重要战略资源之一.基于数据抓取技术,本文介绍了java相关抓取工具,并附上demo源码供感兴趣的朋友测试! 1)JDK自带HTTP连接,获取页面或Json 2) JDK自带URL连接,获取页面或Json 3)HttpClient Get工具,获取页面或Json 4)commons-io工具,获取页面或Json 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式] -------
-
java多线程抓取铃声多多官网的铃声数据
一直想练习下java多线程抓取数据. 有天被我发现,铃声多多的官网(http://www.shoujiduoduo.com/main/)有大量的数据. 通过观察他们前端获取铃声数据的ajax http://www.shoujiduoduo.com/ringweb/ringweb.php?type=getlist&listid={类别ID}&page={分页页码} 很容易就能发现通过改变 listId和page就能从服务器获取铃声的json数据, 通过解析json数据, 可以看到都带有{&q
-
java代码抓取网页邮箱的实现方法
实现思路: 1.使用java.net.URL对象,绑定网络上某一个网页的地址 2.通过java.net.URL对象的openConnection()方法获得一个HttpConnection对象 3.通过HttpConnection对象的getInputStream()方法获得该网络文件的输入流对象InputStream 4.循环读取流中的每一行数据,并由Pattern对象编译的正则表达式区配每一行字符,取得email地址 package cn.sdhzzl; import java.io.Buf
-
php结合curl实现多线程抓取
php结合curl实现多线程抓取 <?php /* curl 多线程抓取 */ /** * curl 多线程 * * @param array $array 并行网址 * @param int $timeout 超时时间 * @return array */ function Curl_http($array,$timeout){ $res = array(); $mh = curl_multi_init();//创建多个curl语柄 $startime = getmicrotime(); fo
-
python多线程抓取天涯帖子内容示例
使用re, urllib, threading 多线程抓取天涯帖子内容,设置url为需抓取的天涯帖子的第一页,设置file_name为下载后的文件名 复制代码 代码如下: #coding:utf-8 import urllibimport reimport threadingimport os, time class Down_Tianya(threading.Thread): """多线程下载""" def __init__(sel
-
Python实现多线程抓取网页功能实例详解
本文实例讲述了Python实现多线程抓取网页功能.分享给大家供大家参考,具体如下: 最近,一直在做网络爬虫相关的东西. 看了一下开源C++写的larbin爬虫,仔细阅读了里面的设计思想和一些关键技术的实现. 1.larbin的URL去重用的很高效的bloom filter算法: 2.DNS处理,使用的adns异步的开源组件: 3.对于url队列的处理,则是用部分缓存到内存,部分写入文件的策略. 4.larbin对文件的相关操作做了很多工作 5.在larbin里有连接池,通过创建套接字,向目标站点
-
python爬虫开发之使用Python爬虫库requests多线程抓取猫眼电影TOP100实例
使用Python爬虫库requests多线程抓取猫眼电影TOP100思路: 查看网页源代码 抓取单页内容 正则表达式提取信息 猫眼TOP100所有信息写入文件 多线程抓取 运行平台:windows Python版本:Python 3.7. IDE:Sublime Text 浏览器:Chrome浏览器 1.查看猫眼电影TOP100网页原代码 按F12查看网页源代码发现每一个电影的信息都在"<dd></dd>"标签之中. 点开之后,信息如下: 2.抓取单页内容 在浏
-
Python爬取肯德基官网ajax的post请求实现过程
目录 准备工作 分析 程序入口 url组成数据定位 构造url 参数 post请求 标头获取(防止反爬的一种手段) 请求对象定制 获取网页源码 获取响应中的页面的源码,下载数据 全部代码 爬取后结果 准备工作 查看肯德基官网的请求方法:post请求. X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求 通过这两个准备步骤,明确本次爬虫目标: ajax的post请求肯德基官网 获取上海肯德基地点前10页. 分析 获取上海肯德基地点前10页,那就需要先对
-
使用java技术抓取网站上彩票双色球信息详解
前言 现在很多web应用,做过web项目的童鞋都知道,web结果由html+js+css组成,html结构都有一定的规范,数据动态交互可以通过js实现. 有些时候,需要抓取某一个你感兴趣的网站信息,一个网站信息肯定是通过某一个url,发送http请求,根据地址定位的,当知道这个地址,可以获取到很多的网络响应,需要认真分析,找到你那一个合适的地址,最后通过这个地址返回一个html给你,我们可以得到这个html,分析结构,解析这个结构获取你要的数据.Html的结构解析往往是复杂繁琐的,我们可以使用j
-
Java爬虫抓取视频网站下载链接
本篇文章抓取目标网站的链接的基础上,进一步提高难度,抓取目标页面上我们所需要的内容并保存在数据库中.这里的测试案例选用了一个我常用的电影下载网站(http://www.80s.la/).本来是想抓取网站上的所有电影的下载链接,后来感觉需要的时间太长,因此改成了抓取2015年电影的下载链接. 一 原理简介 其实原理都跟第一篇文章差不多,不同的是鉴于这个网站的分类列表实在太多,如果不对这些标签加以取舍的话,需要花费的时间难以想象. 分类链接和标签链接都不要,不通过这些链接去爬取其他页面,只通过页底的
-
Java中抓取 Thread Dumps 的方式汇总
Thread dumps(线程转储)能帮助我们判断 CPU 峰值.死锁.内存异常.应用反应迟钝.响应时间变长和其他系统问题.一些在线的分析工具比如 http://fastthread.io/ 也能帮助我们分析和定位问题,但是这些工具都要求有一个 dump 文件.因此在这篇文章当中,我总结了7中抓取 Java Thread Dumps 文件的方式. 1. jstack jstack 是一个抓取 thread dump 文件的有效的命令行工具,它位于 JDK 目录里的 bin 文件夹下(JDK_HO