ehcache开源缓存框架_动力节点Java学院整理
Ehcache是现在最流行的纯Java开源缓存框架,配置简单、结构清晰、功能强大,最初知道它,是从Hibernate的缓存开始的。网上中文的EhCache材料以简单介绍和配置方法居多,如果你有这方面的问题,请自行google;对于API,官网上介绍已经非常清楚,请参见官网;但是很少见到特性说明和对实现原理的分析,因此在这篇文章里面,我会详细介绍和分析EhCache的特性,加上一些自己的理解和思考,希望对缓存感兴趣的朋友有所收获。
一、特性一览,来自官网,简单翻译一下:
1、快速轻量
过去几年,诸多测试表明Ehcache是最快的Java缓存之一。
Ehcache的线程机制是为大型高并发系统设计的。
大量性能测试用例保证Ehcache在不同版本间性能表现得一致性。
很多用户都不知道他们正在用Ehcache,因为不需要什么特别的配置。
API易于使用,这就很容易部署上线和运行。
很小的jar包,Ehcache 2.2.3才668kb。
最小的依赖:唯一的依赖就是SLF4J了。
2、伸缩性
缓存在内存和磁盘存储可以伸缩到数G,Ehcache为大数据存储做过优化。
大内存的情况下,所有进程可以支持数百G的吞吐。
为高并发和大型多CPU服务器做优化。
线程安全和性能总是一对矛盾,Ehcache的线程机制设计采用了Doug Lea的想法来获得较高的性能。
单台虚拟机上支持多缓存管理器。
通过Terracotta服务器矩阵,可以伸缩到数百个节点。
3、灵活性
Ehcache 1.2具备对象API接口和可序列化API接口。
不能序列化的对象可以使用除磁盘存储外Ehcache的所有功能。
除了元素的返回方法以外,API都是统一的。只有这两个方法不一致:getObjectValue和getKeyValue。这就使得缓存对象、序列化对象来获取新的特性这个过程很简单。
支持基于Cache和基于Element的过期策略,每个Cache的存活时间都是可以设置和控制的。
提供了LRU、LFU和FIFO缓存淘汰算法,Ehcache 1.2引入了最少使用和先进先出缓存淘汰算法,构成了完整的缓存淘汰算法。
提供内存和磁盘存储,Ehcache和大多数缓存解决方案一样,提供高性能的内存和磁盘存储。
动态、运行时缓存配置,存活时间、空闲时间、内存和磁盘存放缓存的最大数目都是可以在运行时修改的。
4、标准支持
Ehcache提供了对JSR107 JCACHE API最完整的实现。因为JCACHE在发布以前,Ehcache的实现(如net.sf.jsr107cache)已经发布了。
实现JCACHE API有利于到未来其他缓存解决方案的可移植性。
Ehcache的维护者Greg Luck,正是JSR107的专家委员会委员。
5、可扩展性
监听器可以插件化。Ehcache 1.2提供了CacheManagerEventListener和CacheEventListener接口,实现可以插件化,并且可以在ehcache.xml里配置。
节点发现,冗余器和监听器都可以插件化。
分布式缓存,从Ehcache 1.2开始引入,包含了一些权衡的选项。Ehcache的团队相信没有什么是万能的配置。
实现者可以使用内建的机制或者完全自己实现,因为有完整的插件开发指南。
缓存的可扩展性可以插件化。创建你自己的缓存扩展,它可以持有一个缓存的引用,并且绑定在缓存的生命周期内。
缓存加载器可以插件化。创建你自己的缓存加载器,可以使用一些异步方法来加载数据到缓存里面。
缓存异常处理器可以插件化。创建一个异常处理器,在异常发生的时候,可以执行某些特定操作。
6、应用持久化
在VM重启后,持久化到磁盘的存储可以复原数据。
Ehcache是第一个引入缓存数据持久化存储的开源Java缓存框架。缓存的数据可以在机器重启后从磁盘上重新获得。
根据需要将缓存刷到磁盘。将缓存条目刷到磁盘的操作可以通过cache.flush()方法来执行,这大大方便了Ehcache的使用。
7、监听器
缓存管理器监听器。允许注册实现了CacheManagerEventListener接口的监听器:
notifyCacheAdded()
notifyCacheRemoved()
缓存事件监听器。允许注册实现了CacheEventListener接口的监听器,它提供了许多对缓存事件发生后的处理机制:
notifyElementRemoved/Put/Updated/Expired
8、开启JMX
Ehcache的JMX功能是默认开启的,你可以监控和管理如下的MBean:
CacheManager、Cache、CacheConfiguration、CacheStatistics
9、分布式缓存
从Ehcache 1.2开始,支持高性能的分布式缓存,兼具灵活性和扩展性。
分布式缓存的选项包括:
通过Terracotta的缓存集群:设定和使用Terracotta模式的Ehcache缓存。缓存发现是自动完成的,并且有很多选项可以用来调试缓存行为和性能。
使用RMI、JGroups或者JMS来冗余缓存数据:节点可以通过多播或发现者手动配置。状态更新可以通过RMI连接来异步或者同步完成。
Custom:一个综合的插件机制,支持发现和复制的能力。
可用的缓存复制选项。支持的通过RMI、JGroups或JMS进行的异步或同步的缓存复制。
可靠的分发:使用TCP的内建分发机制。
节点发现:节点可以手动配置或者使用多播自动发现,并且可以自动添加和移除节点。对于多播阻塞的情况下,手动配置可以很好地控制。
分布式缓存可以任意时间加入或者离开集群。缓存可以配置在初始化的时候执行引导程序员。
BootstrapCacheLoaderFactory抽象工厂,实现了BootstrapCacheLoader接口(RMI实现)。
缓存服务端。Ehcache提供了一个Cache Server,一个war包,为绝大多数web容器或者是独立的服务器提供支持。
缓存服务端有两组API:面向资源的RESTful,还有就是SOAP。客户端没有实现语言的限制。
RESTful缓存服务器:Ehcached的实现严格遵循RESTful面向资源的架构风格。
SOAP缓存服务端:Ehcache RESTFul Web Services API暴露了单例的CacheManager,他能在ehcache.xml或者IoC容器里面配置。
标准服务端包含了内嵌的Glassfish web容器。它被打成了war包,可以任意部署到支持Servlet 2.5的web容器内。Glassfish V2/3、Tomcat 6和Jetty 6都已经经过了测试。
10、搜索
标准分布式搜索使用了流式查询接口的方式,请参阅文档。
11、Java EE和应用缓存
为普通缓存场景和模式提供高质量的实现。
阻塞缓存:它的机制避免了复制进程并发操作的问题。
SelfPopulatingCache在缓存一些开销昂贵操作时显得特别有用,它是一种针对读优化的缓存。它不需要调用者知道缓存元素怎样被返回,也支持在不阻塞读的情况下刷新缓存条目。
CachingFilter:一个抽象、可扩展的cache filter。
SimplePageCachingFilter:用于缓存基于request URI和Query String的页面。它可以根据HTTP request header的值来选择采用或者不采用gzip压缩方式将页面发到浏览器端。你可以用它来缓存整个Servlet页面,无论你采用的是JSP、velocity,或者其他的页面渲染技术。
SimplePageFragmentCachingFilter:缓存页面片段,基于request URI和Query String。在JSP中使用jsp:include标签包含。
已经使用Orion和Tomcat测试过,兼容Servlet 2.3、Servlet 2.4规范。
Cacheable命令:这是一种老的命令行模式,支持异步行为、容错。
兼容Hibernate,兼容Google App Engine。
基于JTA的事务支持,支持事务资源管理,二阶段提交和回滚,以及本地事务。
12、开源协议
Apache 2.0 license
二、Ehcache的加载模块列表,他们都是独立的库,每个都为Ehcache添加新的功能,可以在此下载:
ehcache-core:API,标准缓存引擎,RMI复制和Hibernate支持
ehcache:分布式Ehcache,包括Ehcache的核心和Terracotta的库
ehcache-monitor:企业级监控和管理
ehcache-web:为Java Servlet Container提供缓存、gzip压缩支持的filters
ehcache-jcache:JSR107 JCACHE的实现
ehcache-jgroupsreplication:使用JGroup的复制
ehcache-jmsreplication:使用JMS的复制
ehcache-openjpa:OpenJPA插件
ehcache-server:war内部署或者单独部署的RESTful cache server
ehcache-unlockedreadsview:允许Terracotta cache的无锁读
ehcache-debugger:记录RMI分布式调用事件
Ehcache for Ruby:Jruby and Rails支持
Ehcache的结构设计概览:
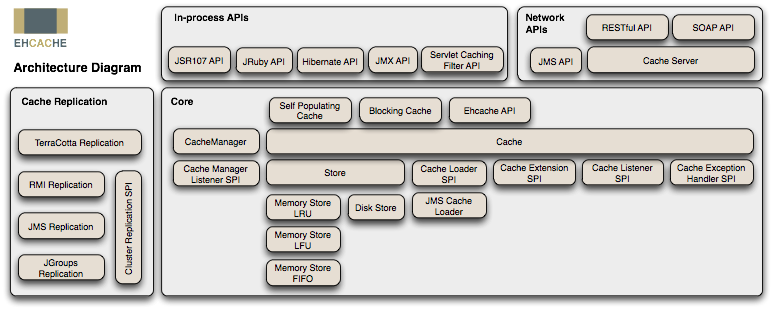
三、核心定义:
cache manager:缓存管理器,以前是只允许单例的,不过现在也可以多实例了
cache:缓存管理器内可以放置若干cache,存放数据的实质,所有cache都实现了Ehcache接口
element:单条缓存数据的组成单位
system of record(SOR):可以取到真实数据的组件,可以是真正的业务逻辑、外部接口调用、存放真实数据的数据库等等,缓存就是从SOR中读取或者写入到SOR中去的。
代码示例:
CacheManager manager = CacheManager.newInstance("src/config/ehcache.xml");
manager.addCache("testCache");
Cache test = singletonManager.getCache("testCache");
test.put(new Element("key1", "value1"));
manager.shutdown();
当然,也支持这种类似DSL的配置方式,配置都是可以在运行时动态修改的:
Cache testCache = new Cache(
new CacheConfiguration("testCache", maxElements)
.memoryStoreEvictionPolicy(MemoryStoreEvictionPolicy.LFU)
.overflowToDisk(true)
.eternal(false)
.timeToLiveSeconds(60)
.timeToIdleSeconds(30)
.diskPersistent(false)
.diskExpiryThreadIntervalSeconds(0));
事务的例子:
Ehcache cache = cacheManager.getEhcache("xaCache");
transactionManager.begin();
try {
Element e = cache.get(key);
Object result = complexService.doStuff(element.getValue());
cache.put(new Element(key, result));
complexService.doMoreStuff(result);
transactionManager.commit();
} catch (Exception e) {
transactionManager.rollback();
}
四、一致性模型:
说到一致性,数据库的一致性是怎样的?不妨先来回顾一下数据库的几个隔离级别:
未提交读(Read Uncommitted):在读数据时不会检查或使用任何锁。因此,在这种隔离级别中可能读取到没有提交的数据。会出现脏读、不可重复读、幻象读。
已提交读(Read Committed):只读取提交的数据并等待其他事务释放排他锁。读数据的共享锁在读操作完成后立即释放。已提交读是数据库的默认隔离级别。会出现不可重复读、幻象读。
可重复读(Repeatable Read):像已提交读级别那样读数据,但会保持共享锁直到事务结束。会出现幻象读。
可序列化(Serializable):工作方式类似于可重复读。但它不仅会锁定受影响的数据,还会锁定这个范围,这就阻止了新数据插入查询所涉及的范围。
基于以上,再来对比思考下面的一致性模型:
1、强一致性模型:系统中的某个数据被成功更新(事务成功返回)后,后续任何对该数据的读取操作都得到更新后的值。这是传统关系数据库提供的一致性模型,也是关系数据库深受人们喜爱的原因之一。强一致性模型下的性能消耗通常是最大的。
2、弱一致性模型:系统中的某个数据被更新后,后续对该数据的读取操作得到的不一定是更新后的值,这种情况下通常有个“不一致性时间窗口”存在:即数据更新完成后在经过这个时间窗口,后续读取操作就能够得到更新后的值。
3、最终一致性模型:属于弱一致性的一种,即某个数据被更新后,如果该数据后续没有被再次更新,那么最终所有的读取操作都会返回更新后的值。
最终一致性模型包含如下几个必要属性,都比较好理解:
读写一致:某线程A,更新某条数据以后,后续的访问全部都能取得更新后的数据。
会话内一致:它本质上和上面那一条是一致的,某用户更改了数据,只要会话还存在,后续他取得的所有数据都必须是更改后的数据。
单调读一致:如果一个进程可以看到当前的值,那么后续的访问不能返回之前的值。
单调写一致:对同一进程内的写行为必须是保序的,否则,写完毕的结果就是不可预期的了。
4、Bulk Load:这种模型是基于批量加载数据到缓存里面的场景而优化的,没有引入锁和常规的淘汰算法这些降低性能的东西,它和最终一致性模型很像,但是有批量、高速写和弱一致性保证的机制。
这样几个API也会影响到一致性的结果:
1、显式锁(Explicit Locking):如果我们本身就配置为强一致性,那么自然所有的缓存操作都具备事务性质。而如果我们配置成最终一致性时,再在外部使用显式锁API,也可以达到事务的效果。当然这样的锁可以控制得更细粒度,但是依然可能存在竞争和线程阻塞。
2、无锁可读取视图(UnlockedReadsView):一个允许脏读的decorator,它只能用在强一致性的配置下,它通过申请一个特殊的写锁来比完全的强一致性配置提升性能。
举例如下,xml配置为强一致性模型:
<cache name="myCache" maxElementsInMemory="500" eternal="false" overflowToDisk="false" <terracotta clustered="true" consistency="strong" /> </cache>
但是使用UnlockedReadsView:
Cache cache = cacheManager.getEhcache("myCache");
UnlockedReadsView unlockedReadsView = new UnlockedReadsView(cache, "myUnlockedCache");
3、原子方法(Atomic methods):方法执行是原子化的,即CAS操作(Compare and Swap)。CAS最终也实现了强一致性的效果,但不同的是,它是采用乐观锁而不是悲观锁来实现的。在乐观锁机制下,更新的操作可能不成功,因为在这过程中可能会有其他线程对同一条数据进行变更,那么在失败后需要重新执行更新操作。现代的CPU都支持CAS原语了。
cache.putIfAbsent(Element element); cache.replace(Element oldOne, Element newOne); cache.remove(Element);
五、缓存拓扑类型:
1、独立缓存(Standalone Ehcache):这样的缓存应用节点都是独立的,互相不通信。
2、分布式缓存(Distributed Ehcache):数据存储在Terracotta的服务器阵列(Terracotta Server Array,TSA)中,但是最近使用的数据,可以存储在各个应用节点中。
逻辑视角:

L1缓存就在各个应用节点上,而L2缓存则放在Cache Server阵列中。
组网视角:

模型存储视角:
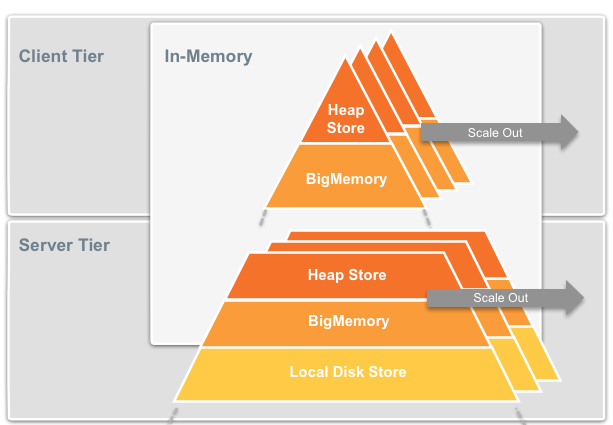
L1级缓存是没有持久化存储的。另外,从缓存数据量上看,server端远大于应用节点。
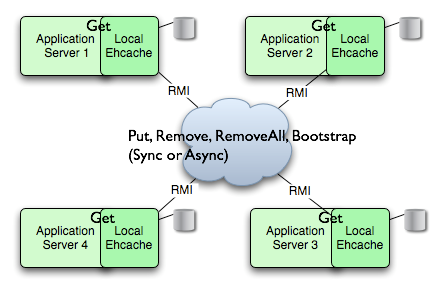
3、复制式缓存(Replicated Ehcache):缓存数据时同时存放在多个应用节点的,数据复制和失效的事件以同步或者异步的形式在各个集群节点间传播。上述事件到来时,会阻塞写线程的操作。在这种模式下,只有弱一致性模型。
它有如下几种事件传播机制:RMI、JGroups、JMS和Cache Server。
RMI模式下,所有节点全部对等:
JGroup模式:可以配置单播或者多播,协议栈和配置都非常灵活。
<cacheManagerPeerProviderFactory class="net.sf.ehcache.distribution.jgroups.JGroupsCacheManagerPeerProviderFactory" properties="connect=UDP(mcast_addr=231.12.21.132;mcast_port=45566;):PING: MERGE2:FD_SOCK:VERIFY_SUSPECT:pbcast.NAKACK:UNICAST:pbcast.STABLE:FRAG:pbcast.GMS" propertySeparator="::" />
JMS模式:这种模式的核心就是一个消息队列,每个应用节点都订阅预先定义好的主题,同时,节点有元素更新时,也会发布更新元素到主题中去。JMS规范实现者上,Open MQ和Active MQ这两个,Ehcache的兼容性都已经测试过。
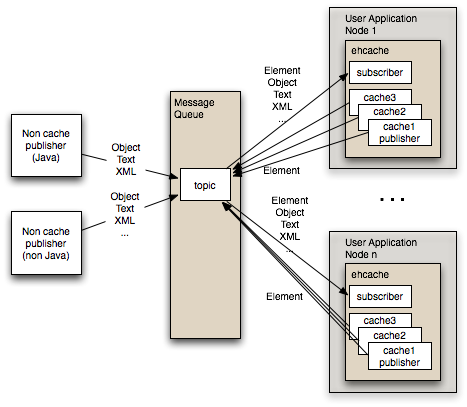
Cache Server模式:这种模式下存在主从节点,通信可以通过RESTful的API或者SOAP。
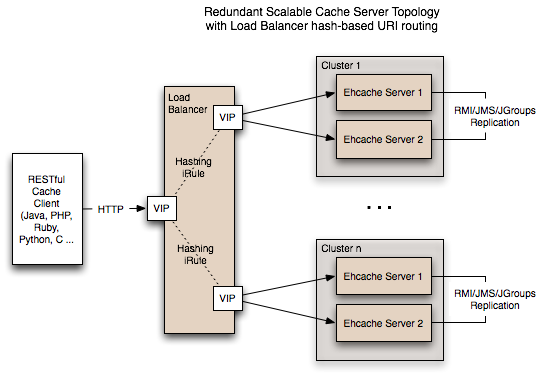
无论上面哪个模式,更新事件又可以分为updateViaCopy或updateViaInvalidate,后者只是发送一个过期消息,效率要高得多。
复制式缓存容易出现数据不一致的问题,如果这成为一个问题,可以考虑使用数据同步分发的机制。
即便不采用分布式缓存和复制式缓存,依然会出现一些不好的行为,比如:
缓存漂移(Cache Drift):每个应用节点只管理自己的缓存,在更新某个节点的时候,不会影响到其他的节点,这样数据之间可能就不同步了。这在web会话数据缓存中情况尤甚。
数据库瓶颈(Database Bottlenecks ):对于单实例的应用来说,缓存可以保护数据库的读风暴;但是,在集群的环境下,每一个应用节点都要定期保持数据最新,节点越多,要维持这样的情况对数据库的开销也越大。
六、存储方式:
1、堆内存储:速度快,但是容量有限。
2、堆外(OffHeapStore)存储:被称为BigMemory,只在企业版本的Ehcache中提供,原理是利用nio的DirectByteBuffers实现,比存储到磁盘上快,而且完全不受GC的影响,可以保证响应时间的稳定性;但是direct buffer的在分配上的开销要比heap buffer大,而且要求必须以字节数组方式存储,因此对象必须在存储过程中进行序列化,读取则进行反序列化操作,它的速度大约比堆内存储慢一个数量级。
(注:direct buffer不受GC影响,但是direct buffer归属的的JAVA对象是在堆上且能够被GC回收的,一旦它被回收,JVM将释放direct buffer的堆外空间。)
3、磁盘存储。
七、缓存使用模式:
cache-aside:直接操作。先询问cache某条缓存数据是否存在,存在的话直接从cache中返回数据,绕过SOR;如果不存在,从SOR中取得数据,然后再放入cache中。
public V readSomeData(K key)
{
Element element;
if ((element = cache.get(key)) != null) {
return element.getValue();
}
if (value = readDataFromDataStore(key)) != null) {
cache.put(new Element(key, value));
}
return value;
}
cache-as-sor:结合了read-through、write-through或write-behind操作,通过给SOR增加了一层代理,对外部应用访问来说,它不用区别数据是从缓存中还是从SOR中取得的。
read-through。
write-through。
write-behind(write-back):既将写的过程变为异步的,又进一步延迟写入数据的过程。
Copy Cache的两个模式:CopyOnRead和CopyOnWrite。
CopyOnRead指的是在读缓存数据的请求到达时,如果发现数据已经过期,需要重新从源处获取,发起的copy element的操作(pull);
CopyOnWrite则是发生在真实数据写入缓存时,发起的更新其他节点的copy element的操作(push)。
前者适合在不允许多个线程访问同一个element的时候使用,后者则允许你自由控制缓存更新通知的时机。
更多push和pull的变化和不同,也可参见这里。
八、多种配置方式:
包括配置文件、声明式配置、编程式配置,甚至通过指定构造器的参数来完成配置,配置设计的原则包括:
所有配置要放到一起
缓存的配置可以很容易在开发阶段、运行时修改
错误的配置能够在程序启动时发现,在运行时修改出错则需要抛出运行时异常
提供默认配置,几乎所有的配置都是可选的,都有默认值
九、自动资源控制(Automatic Resource Control,ARC):
它是提供了一种智能途径来控制缓存,调优性能。特性包括:
内存内缓存对象大小的控制,避免OOM出现
池化(cache manager级别)的缓存大小获取,避免单独计算缓存大小的消耗
灵活的独立基于层的大小计算能力,下图中可以看到,不同层的大小都是可以单独控制的
可以统计字节大小、缓存条目数和百分比
优化高命中数据的获取,以提升性能,参见下面对缓存数据在不同层之间的流转的介绍

缓存数据的流转包括了这样几种行为:
Flush:缓存条目向低层次移动。
Fault:从低层拷贝一个对象到高层。在获取缓存的过程中,某一层发现自己的该缓存条目已经失效,就触发了Fault行为。
Eviction:把缓存条目除去。
Expiration:失效状态。
Pinning:强制缓存条目保持在某一层。
下面的图反映了数据在各个层之间的流转,也反映了数据的生命周期:
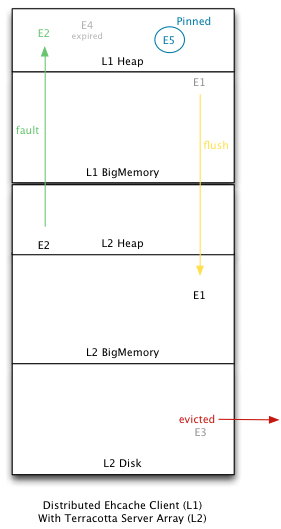
十、监控功能:
监控的拓扑:

每个应用节点部署一个监控探针,通过TCP协议与监控服务器联系,最终将数据提供给富文本客户端或者监控操作服务器。
十一、广域网复制:
缓存数据复制方面,Ehcache允许两个地理位置各异的节点在广域网下维持数据一致性,同时它提供了这样几种方案(注:下面的示例都只绘制了两个节点的情形,实际可以推广到N个节点):
第一种方案:Terracotta Active/Mirror Replication。

这种方案下,服务端包含一个活跃节点,一个备份节点;各个应用节点全部靠该活跃节点提供读写服务。这种方式最简单,管理容易;但是,需要寄希望于理想的网络状况,服务器之间和客户端到服务器之间都存在走WAN的情况,这样的方案其实最不稳定。
第二种方案:Transactional Cache Manager Replication。
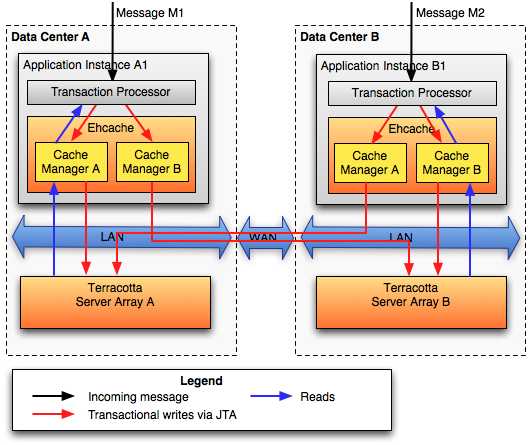
这种方案下,数据读取不需要经过WAN,写入数据时写入两份,分别由两个cache manager处理,一份在本地Server,一份到其他Server去。这种方案下读的吞吐量较高而且延迟较低;但是需要引入一个XA事务管理器,两个cache manager写两份数据导致写开销较大,而且过WAN的写延迟依然可能导致系统响应的瓶颈。
第三种方案:Messaging based (AMQ) replication。

这种方案下,引入了批量处理和队列,用以减缓WAN的瓶颈出现,同时,把处理读请求和复制逻辑从Server Array物理上就剥离开,避免了WAN情况恶化对节点读取业务的影响。这种方案要较高的吞吐量和较低的延迟,读/复制的分离保证了可以提供完备的消息分发保证、冲突处理等特性;但是它较为复杂,而且还需要一个消息总线。
有一些Ehcache特性应用较少或者比较边缘化,没有提到,例如对于JMX的支持;还有一些则是有类似的特性和介绍了,例如对于WEB的支持,请参见我这篇关于OSCache的解读,其中的“web支持”一节有详细的原理分析。
最后,关于Ehcache的性能比对,下面这张图来自Ehcache的创始人Greg Luck的blog:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Java Ehcache缓存框架入门级使用实例
前言 JAVA缓存实现方案有很多,最基本的自己使用Map去构建缓存,或者使用memcached或Redis,但是上述两种缓存框架都要搭建服务器,而Map自行构建的缓存可能没有很高的使用效率,那么我们可以尝试一下使用Ehcache缓存框架. Ehcache主要基于内存缓存,磁盘缓存为辅的,使用起来方便.下面介绍如何在项目中使用Ehcache 入门使用教程 1.maven引用 <dependency> <groupId>net.sf.ehcache</groupId> &l
-

ehcache开源缓存框架_动力节点Java学院整理
Ehcache是现在最流行的纯Java开源缓存框架,配置简单.结构清晰.功能强大,最初知道它,是从Hibernate的缓存开始的.网上中文的EhCache材料以简单介绍和配置方法居多,如果你有这方面的问题,请自行google:对于API,官网上介绍已经非常清楚,请参见官网:但是很少见到特性说明和对实现原理的分析,因此在这篇文章里面,我会详细介绍和分析EhCache的特性,加上一些自己的理解和思考,希望对缓存感兴趣的朋友有所收获. 一.特性一览,来自官网,简单翻译一下: 1.快速轻量 过去几年,
-
Nginx简介_动力节点Java学院整理
1.什么是Nginx Nginx来自俄罗斯的Igor Sysoev在为Rambler Media(http://www.rambler.ru/)工作期间,使用C语言开发了Nginx.Nginx作为Web服务器,一直为俄罗斯著名的门户网站Rambler Media提供着出色.稳定的服务. Igor Sysoev将Nginx的代码开源,并且赋予其最自由的2-clause BSD-like license许可证.由于Nginx使用基于事件驱动的架构能够并发处理百万级别的TCP连接,高度模块化的设计和自
-
web压力测试工具_动力节点Java 学院整理
0. Grinder – Grinder是一个开源的JVM负载测试框架,它通过很多负载注射器来为分布式测试提供了便利. 支持用于执行测试脚本的Jython脚本引擎HTTP测试可通过HTTP代理进行管理.根据项目网站的说法,Grinder的 主要目标用户是"理解他们所测代码的人--Grinder不仅仅是带有一组相关响应时间的'黑盒'测试.由于测试过程可以进行编码--而不是简单地脚本 化,所以程序员能测试应用中内部的各个层次,而不仅仅是通过用户界面测试响应时间. 1. Pylot -Pylot 是
-
深入理解Java中的final关键字_动力节点Java学院整理
Java中的final关键字非常重要,它可以应用于类.方法以及变量.这篇文章中我将带你看看什么是final关键字?将变量,方法和类声明为final代表了什么?使用final的好处是什么?最后也有一些使用final关键字的实例.final经常和static一起使用来声明常量,你也会看到final是如何改善应用性能的. final关键字的含义? final在Java中是一个保留的关键字,可以声明成员变量.方法.类以及本地变量.一旦你将引用声明作final,你将不能改变这个引用了,编译器会检查代码,如
-
Java线程安全的常用类_动力节点Java学院整理
线程安全类 在集合框架中,有些类是线程安全的,这些都是jdk1.1中的出现的.在jdk1.2之后,就出现许许多多非线程安全的类. 下面是这些线程安全的同步的类: vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用.在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的. statck:堆栈类,先进后出 hashtable:就比hashmap多了个线程安全 除了这些之外,其他的集合大都是非线程安全的类和接口. 线程安全的类其方法是同步
-
Java中HashSet和HashMap的区别_动力节点Java学院整理
什么是HashSet? HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象.如果我们没有重写这两个方法,将会使用这个方法的默认实现.. public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true. 什
-
struts2数据处理_动力节点Java学院整理
Struts2框架框架使用OGNL语言和值栈技术实现数据的流转处理.值栈就相当于一个容器,用来存放数据,而OGNL是一种快速查询数据的语言. 值栈:ValueStack一种数据结构,操作数据的方式为:先进后出 OGNL : Object-GraphNavigation Language(对象图形导航语言)将多个对象的关系使用一种树形的结构展现出来,更像一个图形,那么如果需要对树形结构的节点数据进行操作,那么可以使用 对象.属性 的方式进行操作,OGNL技术底层采用反射实现. 一:数据的提交方式
-
Java 中HashCode作用_动力节点Java学院整理
第1 部分 hashCode的作用 Java集合中有两类,一类是List,一类是Set他们之间的区别就在于List集合中的元素师有序的,且可以重复,而Set集合中元素是无序不可重复的.对于List好处理,但是对于Set而言我们要如何来保证元素不重复呢?通过迭代来equals()是否相等.数据量小还可以接受,当我们的数据量大的时候效率可想而知(当然我们可以利用算法进行优化).比如我们向HashSet插入1000数据,难道我们真的要迭代1000次,调用1000次equals()方法吗?hashCod
-
Java Collections集合继承结构图_动力节点Java学院整理
面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式. 数组虽然也可以存储对象,但长度是固定的:集合长度是可变的,数组中可以存储基本数据类型,集合只能存储对象. 集合类的特点:集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象. 集合框架图 Collection (集合的最大接口)继承关系 --List 可以存放重复的内容 --Set 不能存放重复的内容,所以的重复内容靠hashCode()和equals()两个
-
Java7之forkjoin简介_动力节点Java学院整理
Java7引入了Fork Join的概念,来更好的支持并行运算.顾名思义,Fork Join类似与流程语言的分支,合并的概念.也就是说Java7 SE原生支持了在一个主线程中开辟多个分支线程,并且根据分支线程的逻辑来等待(或者不等待)汇集,当然你也可以fork的某一个分支线程中再开辟Fork Join,这也就可以实现Fork Join的嵌套. 有两个核心类ForkJoinPool和ForkJoinTask. ForkJoinPool实现了ExecutorService接口,起到线程池的作用.所以