MySQL简单了解“order by”是怎么工作的
针对排序来说,order by 是我们使用非常频繁的关键字。结合之前我们对索引的了解再来看这篇文章会让我们深刻理解在排序的时候,是如何利用索引来达到少扫描表或者使用外部排序的。
先定义一个表辅助我们后面理解:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB;
这时我们写一条查询语句
select city,name,age from t where city='杭州' order by name limit 1000 ;
根据上面的表定义来看,city=xxx 可以使用到我们定义的一个索引。但是 order by name 明显我们没有索引,所以肯定需要先用索引查询到 city=xxx 然后再进行回表查询,最后再排序。
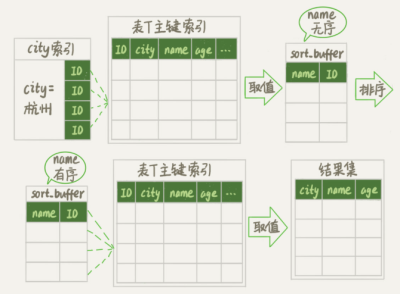
全字段排序
在 city 字段上面创建索引之后,我们使用执行计划来查看这个语句

可以看到有索引的情况下 我们这里还是使用了 "Using filesort" 表示需要排序,MySQL 会给每个线程分配一块内存用于排序 称为 sort_buffer。
我们在执行上面 select 语句的时候通常经历了这样一个过程
1. 初始化 sort_buffer, 确认放入 name, city, age 这三个字段。
2. 从索引 city 找到第一个满足 city='杭州'条件的主键 id。
3. 回表取到 name, city, age 三个字段值,存入 sort_buffer 中。
4. 从索引 city 取下一个主键 id 记录。
5. 重复 3-4 步骤,直到 city 不满足条件。
6. 对 sort_buffer 中的数据按照字段 name 做快速排序。
7. 排序结果取前 1000 行返回给客户端。
这被我们称为全字段排序。

按照 name 排序这个动作即可能在内存中完成,也可以能使用外部文件排序。这取决于 sort_buffer_size 。sort_buffer_size 的默认值是1048576 byte 也就是 1M,如果要排序的数据量小于 1m 排序就在内存中完成,如果排序数据量大,内存放不下,则使用磁盘临时文件辅助排序。
Rowid 排序
如果单行很大,需要的字段全部放进 sort_buffer 效果就不会很好。
MySQL 中专门用于控制排序的行数据长度有个参数 max_length_for_sort_data 默认是1024,如果超过了这个值就会使用 rowid 排序。那么执行上面语句的流程就变成了
1. 初始化 sort_buffe 确定放入两个字段即 name 和 id 。
2. 从索引 city 找到第一个满足 city = '杭州'条件的主键 id。
3. 回表取 name 和 id 两个字段 存入 sort_buffer 中。
4. 取下个满足条件的记录 重复 2 3 步骤。
5. 对 sort_buffer 中的 name 进行排序。
6.遍历结果取前 1000 行。然后按照 id 再回一次表取的结果字段返回给客户端。
其实并不是所有 oder by 语句都需要进行上面的二次排序操作。从上面分析的执行过程,我们可以注意到。MySQL 之所以需要生成临时表,是因为要在临时表上做排序,是因为之前我们取得的是数据是无序的。
如果我们对刚才的索引修改一下,使得他是一个联合索引,那么第二个字段我们拿到的值其实就是有序的了。
联合索引满足这么一个条件,当我们的第一个索引字段是相等的情况下,第二个字段是有序的。
这能保证如果我们建立 (city,name) 索引的话,当我们在搜索 city='杭州'的情况的是时候找到的目标第二个字段 name 其实是有序的。所以查询过程可以简化成。
1. 从索引 (city, name) 找到第一个满足 city = '杭州'条件的主键 id 。
2. 回表取到 name city age 三个值返回。
3. 取下一个 id 。
4. 重复2 3 两个步骤直到 1000 条记录,或者是不满足 city = '杭州'条件结束。
也因为查询过程都可以使用到索引的有序性,所以不再需要排序也不需要时使用 sort buffer 了。
更近一步的优化就是之前说过的索引覆盖,将需要查询的字段也覆盖进索引中,再省掉回表的步骤,可以让整个查询的速度更快。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Mysql带And关键字的多条件查询语句
MySQL带AND关键字的多条件查询,MySQL中,使用AND关键字,可以连接两个或者多个查询条件,只有满足所有条件的记录,才会被返回. SELECT * | {字段名1,字段名2,--} FROM 表名 WHERE 条件表达式1 AND 条件表达式2 [-- AND 条件表达式n]; 查询student表中,id字段值小于16,并且,gender字段值为nv的学生姓名 可以看出,查询条件必须都满足,才会返回 查询student表中,id字段值在12.13.14.15之中,name字段值以字符串
-
SQL语句中OR和AND的混合使用的小技巧
今天有这样得一个需求,如果登陆人是客服的话,会查询订单是'该客服'以及还没有匹配客服的,刚开始想的是直接在sql语句上拼写 or assigned_id is null 的,测试了一下发现这样的话,前面的其他条件都没有用了 这样的话,第一个i.server_org_id = 4这个条件已经不适用了,,,,,,,,从这里可以知道AND 的优先级比OR的优先级高,先执行了前面的AND 语句,然后执行后面的OR语句,所以查出来的数据不是我想要的数据 后来又想了一下,可以先将对应的assigned
-
.NET Core Dapper操作mysql数据库的实现方法
前言 现在ORM盛行,市面上已经出现了N款不同的ORM套餐了.今天,我们不谈EF,也不聊神马黑马,就说说 Dapper.如何在.NET Core中使用Dapper操作Mysql数据库呢,让我们跟随镜头(手动下翻)一看究竟. 配置篇 俗话说得好,欲要善其事必先利其器.首先,我们要引入MySql.Data 的Nuget包.有人可能出现了黑人脸,怎么引入.也罢,看在你骨骼惊奇的份上,我就告诉你,两种方式: 第一种方式 Install-Package MySql.Data -Version 8.0.15
-
MySQL中(JOIN/ORDER BY)语句的查询过程及优化方法
在MySQL查询语句过程和EXPLAIN语句基本概念及其优化中介绍了EXPLAIN语句,并举了一个慢查询例子: 可以看到上述的查询需要检查1万多记录,并且使用了临时表和filesort排序,这样的查询在用户数快速增长后将成为噩梦. 在优化这个语句之前,我们先了解下SQL查询的基本执行过程: 1.应用通过MySQL API把查询命令发送给MySQL服务器,然后被解析 2.检查权限.MySQL optimizer进行优化,经过解析和优化后的查询命令被编译为CPU可运行的二进制形式的查询计划(quer
-
MySQL简单了解“order by”是怎么工作的
针对排序来说,order by 是我们使用非常频繁的关键字.结合之前我们对索引的了解再来看这篇文章会让我们深刻理解在排序的时候,是如何利用索引来达到少扫描表或者使用外部排序的. 先定义一个表辅助我们后面理解: CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) D
-
Python操作MySQL简单实现方法
本文实例讲述了Python操作MySQL简单实现方法.分享给大家供大家参考.具体分析如下: 一.安装: 安装MySQL 安装MySQL不用多说了,下载下来安装就是,没有特别需要注意的地方. 一个下载地址:点击打开链接 二.示例: 复制代码 代码如下: # coding=utf-8 import MySQLdb #查询数量 def Count(cur): count=cur.execute('select * from Student') print 'there has %s r
-
mysql简单实现查询结果添加序列号的方法
本文实例讲述了mysql简单实现查询结果添加序列号的方法.分享给大家供大家参考,具体如下: 第一种方法: 复制代码 代码如下: select (@i:=@i+1) as i,table_name.* from table_name,(select @i:=0) as it 第二种方法: set @rownum=0; select @rownum:=@rownum+1 as rownum, t.username from auth_user t limit 1,5; 更多关于MySQL相关内容感兴
-
linux下安装mysql简单的方法
在网上搜索Linux下安装MySQL的方法时,出现了很多的方法,但是很多的方法很复杂,而且还不一定成功,试了很久终于试验出一种简单的方法,下面来谈谈我是怎么安装的吧 1.准备安装包 (1)mysql-client-5.5.8-1.rhel5.x86_64.rpm (2)MySQL-devel-5.5.8-1.rhel5.x86_64.rpm (3)MySQL-server-5.5.8-1.rhel5.x86_64.rpm 2.将下载好的安装包上传到linux上 3.安装mysql的三个安装包 r
-
基于PHP+Mysql简单实现了图书购物车系统的实例详解
PHP+Mysql简单实现了图书购物车 本文主要讲述如何通过PHP+HTML简单实现图书购物车的功能,这是提取我们php项目的部分内容.主要内容包括: 1.通过JavaScript和Iframe实现局部布局界面 2.PHP如何定义类实现访问数据库功能 3.实现简单的添加购物车功能 4.实现了后台管理前台的页面 由于这个项目是在期末完成,PHP只是刚学的,比较简单. 效果图如下: 这是后台管理的页面: 这是前台页面: index.php页面: <!DOCTYPE h
-
MySQL不使用order by实现排名的三种思路总结
假定业务: 查看在职员工的薪资的第二名的员工信息 创建数据库 drop database if exists emps; create database emps; use emps; create table employees( empId int primary key,-- 员工编号 gender char(1) NOT NULL, -- 员工性别 hire_date date NOT NULL -- 员工入职时间 ); create table salaries( empId int
-
golang 基于 mysql 简单实现分布式读写锁
目录 业务场景 什么是分布式读写锁 分布式读写锁的访问原则 读锁 写锁 具体实现 通过 gorm 连接 mysql 实现读锁模式 实现写锁模式 总结 业务场景 因为项目刚上线,目前暂不打算引入其他中间件,所以打算通过 mysql 来实现分布式读写锁:而该业务场景也满足分布式读写锁的场景,抽象后的业务场景是:特定资源 X,可以执行 2 种操作:读操作和写操作,2种操作需要满足下面条件: 执行操作的机器分布式在不同的节点中,也就是分布式的: 读操作是共享的,也就是说同时可以有多个 goroutine
-
mysql中提高Order by语句查询效率的两个思路分析
因为可能需要对数据库的记录进行重新排序.在这篇文章中,笔者就谈谈提高Order By语句查询效率的两个思路,以供大家参考. 在MySQL数据库中,Order by语句的使用频率是比较高的.但是众所周知,在使用这个语句时,往往会降低数据查询的性能.因为可能需要对数据库的记录进行重新排序.在这篇文章中,笔者就谈谈提高Order By语句查询效率的两个思路,以供大家参考. 498)this.width=498;" border=0> 一.建议使用一个索引来满足Order By子句. 在条件允许的
-
MySQL数据库索引order by排序精讲
排序这个词,我的第一感觉是几乎所有App都有排序的地方,淘宝商品有按照购买时间的排序.B站的评论有按照热度排序的... 对于MySQL,一说到排序,你第一时间想到的是什么?关键字order by?order by的字段最好有索引?叶子结点已经是顺序的?还是说尽量不要在MySQL内部排序? 事情的起因 现在假设有一张用户的朋友表: CREATE TABLE `user` ( `id` int(10) AUTO_INCREMENT, `user_id` int(10), `friend_addr`
-
MySQL数据库索引order by排序精讲
目录 事情的起因 解剖文件排序 文件排序很慢,还有其他办法吗 不想回表,不想再次排序 总结 排序这个词,我的第一感觉是几乎所有App都有排序的地方,淘宝商品有按照购买时间的排序.B站的评论有按照热度排序的... 对于MySQL,一说到排序,你第一时间想到的是什么?关键字order by?order by的字段最好有索引?叶子结点已经是顺序的?还是说尽量不要在MySQL内部排序? 事情的起因 现在假设有一张用户的朋友表: CREATE TABLE `user` ( `id` int(10) AUT