python与字符编码问题
用python2的小伙伴肯定会遇到字符编码的问题。下面对编码问题做个简单的总结,希望对各位有些帮助。
故事零:编码的定义
我们从“SOS“(国际通用求助信号)开始,它的摩斯密码的编码是:
“…---…”,想一下为什么选用S、O、S来作为求救信号?因为它简单,容易辨别且不容易发错呀!
那么,字符编码就是:
´给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码。例如,我们给字符'A'赋予数值0x41,则0x41就是字符'A'的编码。字符编码是字符的表现、储存方式。
字符编码需要处理两件事:
(1)规定一个字符集中的字符由多少个字节表示;
(2)制定该字符集的字符编码表,即该字符集中每个字符对应的(二进制)值。
字符集:´给定一系列字符并赋予对应的编码后,所有这些字符和编码对组成的集合就是字符集。´比如,给定字符列表为{'A','B'}时,{'A'=>0x41,‘B'=>0x42}就是一个字符集。
常见字符集有:
ASCII
GB2312
GBK
GB18030
Big5
Unicode
一张图总结:

故事一:Python2与Python3的字符串类型?
python2中的字符串有str和unicode类型,而python3中字符串只有unicode类型。比如 ‘你好'是str字符串,而 u'你好'则是unicode字符串。
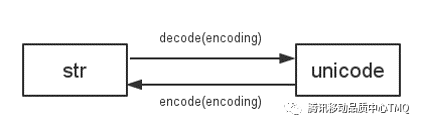
故事二:decode()和encode()傻傻分不清?
decode() 是将str字符串转化为unicode字符串;encode() 是将unicode字符串转化为str字符串。所以要做一些编码的转换通常是以unicode作为中间编码做转换。如name.decode(“GB2312”)表示将GB2312编码的字符串name转换成unicode编码,name.encode(“GB2312”)表示将unicode字符串name转换成GB2312编码。
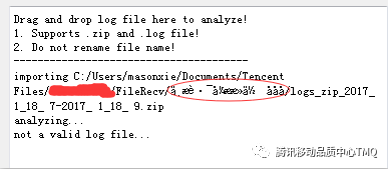
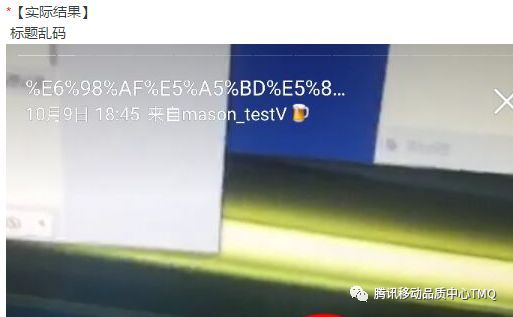
故事三:UnicodeEncodeError: ‘ascii' codec can't encode character?
我们先看看两张图,是不是很烦?
下面我们看个例子:

当用u'字符串'申明这个字符串变量时就指明了该字符串是使用unicode字符编码。当要将unicode字符串转换为str字符串或者写入文件时,python2默认使用ASCII 码保存数据,而ASCII 码无法识别大于128 的字符,于是报了上面的错误。
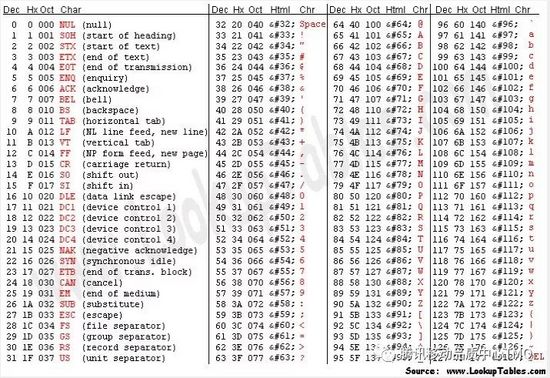
附ASCII码表:
故事四:unicode是什么?
unicode可以看做一个终极的字符编码方法,它给出了地球上常用字符的二进制映射,而且所有的二进制字符串唯一地表示一个字符。但是,unicode只给出了字符和二进制串的对应关系,并没有给出存储形式。而不同字符所占用的存储空间可能不同,比如ASCII 在unicode中只占用了一个字节即可,而常用汉字在unicode中需要占用两个字节,还有一些罗马字符可能需要三个或以上字节。如果直接存储的话可能导致无法分割字符串,也无法正确解码出字符。
故事五:UTF-8横空出世?
互联网的普及,强烈要求出现一种统一的编码方式。这时候UTF-8 出场。UTF-8 是unicode在计算机中的一种实现方式。UTF-8是一种变长编码,每个字符占1-4 个字节。UTF-8 将字节分为数值位和标识位,数值位真正保存字符编码数值,标识位表示这个字节是属于哪个字符的、或者该字符占多少个字节。UTF-8 编码方法:
单字节,首位为标识位0;多字节字符首字节标志位1··10开头,字符占多少字节则有多少1,其他字节标识位10开头;
§ 单字节字符: 0xxxxxxx (以0 开头标志位,数值位用x 表示)
§ 双字节字符: 110xxxxx 10xxxxxx
§ 三字节字符: 1110xxxx 10xxxxxx 10xxxxxx
§ 四字节字符: 11110xxx 10xxxxxx 10xxxxxx10xxxxxx
unicode变为UTF-8 编码非常简单,unicode二进制按照从低到高,填充UTF-8的数值位,除去那些不真正表示数值的标识位(字节开头的0,10,110,1110和11110),顺序也是由低到高。以汉字“你”为例,可见它的unicode编码为“4f60”(01001111 01100000)。
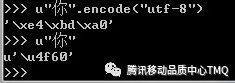
从“你”的unicode值范围可以看到需要三个字节,接着从低位字节向高位字节填充得到“你”的UTF-8 编码(高位没有填充完则用0补充)。

可以看到将UTF-8 用于标记位(红色)的位去掉,合并可以得到原始的unicode码。
故事六:"unicode-escape"与"unicode-unescape"
“\u”是表示unicode的转义字符,用\uxxxx这种方式表示unicode字符就是”unicode-escape”方式。说人话:´一句话:xxx.decode(“unicode-escape”)相当于把xxx解码成unicode类型并返回。
而用”%uxxxx”的方式表示unicode字符,这种方式就是”unicode-unescape”,常用于javascript。
番外故事七:读了那么多年书,你真的了解“全半角”?
全角---指一个字符占用两个标准字符位置。
半角---指一字符占用一个标准的字符位置。
引申:写程序时双引号、冒号、小括号等为啥如此纠结?
--我国专家在制定GB2312字符集时,ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码。
是不是脑壳疼呀,想想我国程序员因为中英文切换牺牲了多少宝贵时间啊,啊嘿!
总结
以上所述是小编给大家介绍的python与字符编码问题 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python判断文件和字符串编码类型的实例
python判断文件和字符串编码类型可以用chardet工具包,可以识别大多数的编码类型.但是前几天在读取一个Windows记事本保存的txt文件时,GBK却被识别成了KOI8-R,无解. 然后就自己写了个简单的编码识别方法,代码如下: coding.py # 说明:UTF兼容ISO8859-1和ASCII,GB18030兼容GBK,GBK兼容GB2312,GB2312兼容ASCII CODES = ['UTF-8', 'UTF-16', 'GB18030', 'BIG5'] # UTF-8 B
-
Python中的字符串操作和编码Unicode详解
本文主要给大家介绍了关于 Python中的字符串操作和编码Unicode的一些知识,下面话不多说,需要的朋友们下面来一起学习吧. 字符串类型 str:Unicode字符串.采用''或者r''构造的字符串均为str,单引号可以用双引号或者三引号来代替.无论用哪种方式进行制定,在Python内部存储时没有区别. bytes:二进制字符串.由于jpg等其他格式的文件不能用str进行显示,所以才用bytes来表示,bytes的每个字节为一个0-255的数字.如果打印的时候,Python会把能够用ASCI
-
python字符串与url编码的转换实例
主要应用的场景 爬虫生成带搜索词语的网址 1.字符串转为url编码 import urllib poet_name = "李白" url_code_name = urllib.quote(poet_name) print url_code_name #输出 #%E6%9D%8E%E7%99%BD 2.url编码转为字符串 import urllib url_code_name = "%E6%9D%8E%E7%99%BD" name = urllib.unquote(
-
Python 十六进制整数与ASCii编码字符串相互转换方法
在使用Pyserial与STM32进行通讯时,遇到了需要将十六进制整数以Ascii码编码的字符串进行发送并且将接收到的Ascii码编码的字符串转换成十六进制整型的问题.查阅网上的资料后,均没有符合要求的,遂结合各家之长,用了以下方法. 环境 Python2.7 + Binascii模块 十六进制整数转ASCii编码字符串 # -*- coding: utf-8 -*- import binascii #16进制整数转ASCii编码字符串 a = 0x665554 b = hex(a) #转换成相
-

Python3如何解决字符编码问题详解
编码 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节.比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295. 由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母.数字和一些符号,这个编码表被称为ASC
-
Python字符编码判断方法分析
本文实例讲述了Python字符编码判断方法.分享给大家供大家参考,具体如下: 方法一: isinstance(s, str) 用来判断是否为一般字符串 isinstance(s, unicode) 用来判断是否为unicode 或 if type(str).__name__!="unicode": str=unicode(str,"utf-8") else: pass 方法二: Python chardet 字符编码判断 使用 chardet 可以很方便的实现字符串
-
解决Python3中的中文字符编码的问题
python3中str默认为Unicode的编码格式 Unicode是一32位编码格式,不适合用来传输和存储,所以必须转换成utf-8,gbk等等 所以在Python3中必须将str类型转换成bytes类型的 在Python中使用encode的方式可以进行字符的编码 实际用法: >>>a = "中国" >>> a.encode("utf-8") b'\xe4\xb8\xad\xe5\x9b\xbd' >>> a.
-
python与字符编码问题
用python2的小伙伴肯定会遇到字符编码的问题.下面对编码问题做个简单的总结,希望对各位有些帮助. 故事零:编码的定义 我们从"SOS"(国际通用求助信号)开始,它的摩斯密码的编码是: "-----",想一下为什么选用S.O.S来作为求救信号?因为它简单,容易辨别且不容易发错呀! 那么,字符编码就是: ´给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码.例如,我们给字符'A'赋予数值0x41,则0x41就是字符'A'的编码.字
-
Python中字符编码简介、方法及使用建议
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号.不过ASCII只用到了其中的一半(\x80以下),这也是MBCS得以实现的基础. 1.2. MBCS 然而计算机世界里很快就有了其他语言,单字节的ASCII已无法满足需求.后来每个语言就制定了一套自己的编码,由于单字节
-
彻底搞懂Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 encode.decode 函数翻来覆去的转换,有时试着试着问题就解决了,有时候怎么试都没辙,只有借用 Google 大神帮忙,但似乎很少去关心问题的本质是什么,下次遇到类似的问题重蹈覆辙,那么你有没有想过一次性彻底把 Python 字符编码给搞懂呢? 完全理解字符编码 与 Python 的渊源前,我们有
-
Python字符编码与函数的基本使用方法
一.Python2中的字符存在的解码编码问题 如果是现在正在用Python2的人应该都知道存在字符编码问题,就举一个最简单的例子吧:Python2是无法在命令行直接打印中文的,当然他也是不会报错的,顶多是一堆你看不懂的乱码.如果想在直接显示中文,我们是可以在Python2文件头部申明字符编码的格式.如下图 这里 #-*-coding:utf-8 -*- 是用来申明下面的代码是用什么编码来解释: 1.1.Python2中的解码和编码: 在编码和解码的世界中,我们得需要找一个大家都知道的文字.也可以
-
快速入手Python字符编码
前言 对于很多接触Python的人而言,字符的处理和语言整体的温顺可靠相比显得格外桀骜不驯难以驾驭. 文章针对Python 2.7,主要因为3对的编码已经有了很大的改善并且实际原理一样,更改一下操作命令即可. 了解完本文,你可以轻松解决文字处理,特殊平台(Windows?)下的编码,爬虫编码等问题. 阅读建议 本文分为如下几个部分: 1.原理 2.具体操作 3.建议的使用习惯 4.疑难问题解答 如果想要了解我给出的使用习惯,可以直接跳到建议的使用习惯. 如果只想要解决相关问题可以直接跳到疑难问题
-
老生常谈Python基础之字符编码
前言 字符编码非常容易出问题,我们要牢记几句话: 1.用什么编码保存的,就要用什么编码打开 2.程序的执行,是先将文件读入内存中 3.unicode是父编码,只能encode解码成其他编码格式 utf-8,GBK这些是子8编码,只能decode编码成Unicode 一.什么是字符编码 我们知道,计算机只能识别二进制,我们平时写的代码都需要转成二进制才能被计算机识别.所以,我们写的字符怎么转换成二进制呢,这个过程实际就是通过一个标准使我们写的字符与特定数字一一对应,这个标准就称为字符编码. 字符-
-
再谈Python中的字符串与字符编码(推荐)
本节内容: 1.前言 2.相关概念 3.Python中的默认编码 4.Python2与Python3中对字符串的支持 5.字符编码转换 一.前言 Python中的字符编码是个老生常谈的话题,同行们都写过很多这方面的文章.有的人云亦云,也有的写得很深入.近日看到某知名培训机构的教学视频中再次谈及此问题,讲解的还是不尽人意,所以才想写这篇文字.一方面,梳理一下相关知识,另一方面,希望给其他人些许帮助. Python2的 默认编码 是ASCII,不能识别中文字符,需要显式指定字符编码:Python3的
-
深入浅析Python字符编码
Python的字符串编码规则一直让我很头疼,花了点时间研究了下,并不复杂.主要涉及的内容有常用的字符编码的特点,并介绍了在python2.x中如何与编码问题作战,本文关于Python的内容仅适用于2.x,3.x中str和unicode有翻天覆地的变化,具体请查阅相关资料. 1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有英文,而单字节可以表示25
-
跟老齐学Python之坑爹的字符编码
字符编码,在编程中,是一个让学习者比较郁闷的东西,比如一个str,如果都是英文,好说多了.但恰恰不是如此,中文是我们不得不用的.所以,哪怕是初学者,都要了解并能够解决字符编码问题. >>> name = '老齐' >>> name '\xe8\x80\x81\xe9\xbd\x90' 在你的编程中,你遇到过上面的情形吗?认识最下面一行打印出来的东西吗?看人家英文,就好多了 >>> name = "qiwsir" >>&g