python利用selenium进行浏览器爬虫
前言
相信大家刚开始在做爬虫的时候,是不是requests和sound这两个库来使用,这样确实有助于我们学习爬虫的知识点,下面来介绍一个算事较复杂的爬虫案例selenium进形打开浏览器爬取网站的信息
导入第三方库

自执行函数

解析信息

保存文件信息

打开浏览器

获取链接信息
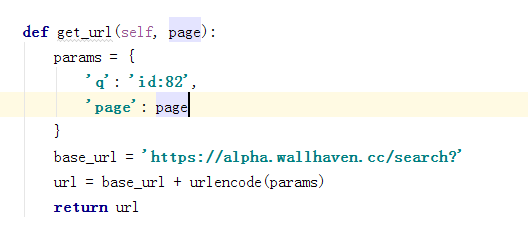
执行函数
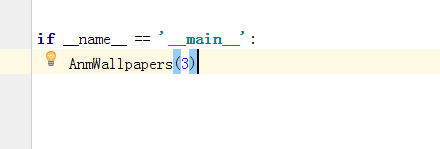
运行结果

总结
以上所述是小编给大家介绍的python利用selenium进行浏览器爬虫,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python爬虫 使用真实浏览器打开网页的两种方法总结
1.使用系统自带库 os 这种方法的优点是,任何浏览器都能够使用, 缺点不能自如的打开一个又一个的网页 import os os.system('"C:/Program Files/Internet Explorer/iexplore.exe" http://www.baidu.com') 2.使用python 集成的库 webbroswer python的webbrowser模块支持对浏览器进行一些操作,主要有以下三个方法: import webbrowser webbrowser.
-
Python3爬虫之urllib携带cookie爬取网页的方法
如下所示: import urllib.request import urllib.parse url = 'https://weibo.cn/5273088553/info' #正常的方式进行访问 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36' # } # 携带
-
python爬虫中get和post方法介绍以及cookie作用
首先确定你要爬取的目标网站的表单提交方式,可以通过开发者工具看到.这里推荐使用chrome. 这里我用163邮箱为例 打开工具后再Network中,在Name选中想要了解的网站,右侧headers里的request method就是提交方式.status如果是200表示成功访问下面的有头信息,cookie是你登录之后产生的存储会话(session)信息的.第一次访问该网页需要提供用户名和密码,之后只需要在headers里提供cookie就可以登陆进去. 引入requests库,会提供get和po
-
Python爬虫使用浏览器cookies:browsercookie过程解析
很多用Python的人可能都写过网络爬虫,自动化获取网络数据确实是一件令人愉悦的事情,而Python很好的帮助我们达到这种愉悦.然而,爬虫经常要碰到各种登录.验证的阻挠,让人灰心丧气(网站:天天碰到各种各样的爬虫抓我们网站,也很让人灰心丧气-).爬虫和反爬虫就是一个猫和老鼠的游戏,道高一尺魔高一丈,两者反复纠缠. 由于http协议的无状态性,登录验证都是通过传递cookies来实现的.通过浏览器登录一次,登录信息的cookie是就会被浏览器保存下来.下次再打开该网站时,浏览器自动带上保存的coo
-

Python中urllib+urllib2+cookielib模块编写爬虫实战
超文本传输协议http构成了万维网的基础,它利用URI(统一资源标识符)来识别Internet上的数据,而指定文档地址的URI被称为URL(既统一资源定位符),常见的URL指向文件.目录或者执行复杂任务的对象(如数据库查找,internet搜索),而爬虫实质上正是通过对这些url进行访问.操作,从而获取我们想要的内容.对于没有商业需求的我们而言,想要编写爬虫的话,使用urllib,urllib2与cookielib三个模块便可以完成很多需求了. 首先要说明的是,urllib2并非是urllib的
-
Python实现爬虫设置代理IP和伪装成浏览器的方法分享
1.python爬虫浏览器伪装 #导入urllib.request模块 import urllib.request #设置请求头 headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") #创建一个opener opene
-
python爬虫使用cookie登录详解
前言: 什么是cookie? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么我们可以利用Urllib库保存我们登录的Cookie,然后再抓取其他页面,这样就达到了我们的目的. 一.Urllib库简介 Urllib是python内置的HTTP请求库,官方地址:https://docs.python.org/3/library/urllib.ht
-
Python爬虫利用cookie实现模拟登陆实例详解
Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 举个例子,某些网站是需要登录后才能得到你想要的信息的,不登陆只能是游客模式,那么我们可以利用Urllib2库保存我们以前登录过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取.理解cookie主要是为我们快捷模拟登录抓取目标网页做出准备. 我之前的帖子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有ur
-
python利用selenium进行浏览器爬虫
前言 相信大家刚开始在做爬虫的时候,是不是requests和sound这两个库来使用,这样确实有助于我们学习爬虫的知识点,下面来介绍一个算事较复杂的爬虫案例selenium进形打开浏览器爬取网站的信息 导入第三方库 自执行函数 解析信息 保存文件信息 打开浏览器 获取链接信息 执行函数 运行结果 总结 以上所述是小编给大家介绍的python利用selenium进行浏览器爬虫,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持! 如果你觉得本
-
Python使用Selenium模拟浏览器自动操作功能
概述 在进行网站爬取数据的时候,会发现很多网站都进行了反爬虫的处理,如JS加密,Ajax加密,反Debug等方法,通过请求获取数据和页面展示的内容完全不同,这时候就用到Selenium技术,来模拟浏览器的操作,然后获取数据.本文以一个简单的小例子,简述Python搭配Tkinter和Selenium进行浏览器的模拟操作,仅供学习分享使用,如有不足之处,还请指正. 什么是Selenium? Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在
-
Python利用Selenium实现网站自动签到功能
目录 什么是Selenium 前情提要 准备工作 代码及讲解 点击登录 点击跳过弹窗 小结 什么是Selenium 先带领大家学习下Selenium的基本概念吧. Selenium主要用于web应用程序的自动化测试,但并不局限于此,它还支持所有基于web的管理任务自动化. 它的特点如下: 开源,免费 多浏览器支持:Firefox.Chrome.IE等 多平台支持:Linux.Windows.Mac 多语言支持:Java.Python.Ruby.C#.JavaScript.C++ 对web页面有良
-
C# 利用Selenium实现浏览器自动化操作的示例代码
概述 Selenium是一款免费的分布式的自动化测试工具,支持多种开发语言,无论是C. java.ruby.python.或是C# ,你都可以通过selenium完成自动化测试.本文以一个简单的小例子,简述C# 利用Selenium进行浏览器的模拟操作,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 要实现本例的功能,除了要掌握Html ,JavaScript,CSS等基础知识,还涉及以下知识点: log4net:主要用于日志的记录和存储,本例采用log4net进行日志记录,便于过程跟踪
-
Python利用selenium建立代理ip池访问网站的全过程
目录 一.使用selenium前? 1.安装selenium 2.安装浏览器驱动 3.配置环境 二.使用selenium 1.引入库 2.完整代码 总结 一.使用selenium前? 1.安装selenium pip install Selenium 2.安装浏览器驱动 Chrome驱动文件下载:点击下载 3.配置环境 1.将下载文件放进C:\Program Files (x86)\Google\Chrome\Application下就可以 2.然后配置下系统变量:我的电脑–>属性–>系统设置
-
Python利用Selenium实现弹出框的处理
目录 JavaScript三种弹出对话框的简单介绍 alert() - 警告框 confirm() - 确认框 cprompt() - 提示框 selenium 处理弹出对话框的常用方法 selenium 处理 alert() 弹窗 selenium 处理 confirm() 弹窗 selenium 处理 prompt() 弹窗 现如今经常出现在网页上的基于 JavaScript 实现的弹出框有三种,分别是 alert.confirm.prompt .该章节主要是学习如何利用 selenium
-
Python利用splinter实现浏览器自动化操作方法
利用Splinter开发浏览器自动化操作,编写代码比较简单. 案例一: from splinter import Browser with Browser() as browser: # Visit URL url = "http://www.google.com" browser.visit(url) browser.fill('q', 'splinter - python acceptance testing for web applications') # Find and cl
-
Python利用Selenium实现自动观看学习通视频
目录 一.登录 二.进行一个页面的视频观看 三.所有视频的观看 四.总代码 其他 一.登录 以信号与系统课程为例,直接输入网址则出现登录界面: 由于学号登录需要验证码,因此选择电话登录: 直接在开发者工具中找到手机号输入框.密码输入框和登录按钮,并进行输入和点击: import time from selenium.webdriver import Chrome web = Chrome() web.get('https://mooc2-ans.chaoxing.com/mycourse/stu
-
Python之Selenium自动化浏览器测试详解
目录 Python之Selenium(自动化浏览器测试) 1.安装selenium 2.下载对应版本的浏览器驱动 3.测试code,打开一个网页,并获取网页的标题 4.一个小样例 总结 Python之Selenium(自动化浏览器测试) 1.安装selenium pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple 2.下载对应版本的浏览器驱动 http://npm.taobao.org/mirrors/chromedr
-
python使用selenium模拟浏览器进入好友QQ空间留言功能
首先下载selenium模块,pip install selenium,下载一个浏览器驱动程序(我这里使用谷歌). #导入 #注意python各版本find_element()方法的变化(python3.10) from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By # 创建一个模拟浏览器对象,然