Java爬虫Jsoup+httpclient获取动态生成的数据
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细讲了一下Jsoup发现这玩意其实也就那样,只要是可以访问到的静态资源页面都可以直接用他来获取你所需要的数据,详情情跳转-Jsoup爬虫详解,但是很多时候网站为了防止数据被恶意爬取做了很多遮掩,比如说加密啊动态加载啊,这无形中给我们写的爬虫程序造成了很大的困扰,那么我们如何来突破这个梗获取我们急需的数据呢,
下面我们来详细讲解一下如何获取
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时其实已经获取到了整个页面的数据,但是商品价格是通过回调函数获取后再填充上去的,所以这就要求我们写爬虫的开发者要很有耐心的去寻找价格数据的回调接口,我们直接访问这个接口就可以直接获取这个价格,下面是演示:
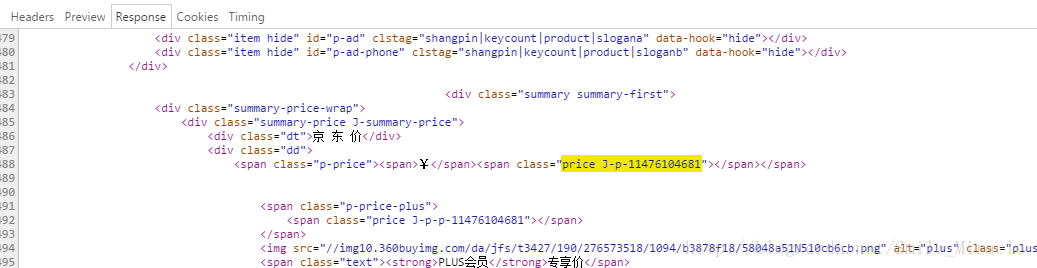
通过这张截图可以看到他传过来的只是一个静态资源页面根本没有价格参数,那么价格怎么来的呢,继续找发现这个接口:


你会发现在这个接口是很多参数拼接上去的,那么我们要做的就是分析是不是所有的参数都有用
https://p.3.cn/prices/mgets?callback=jQuery9734926&type=1&area=1&pdtk= pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以试着删除一些参数发现最终这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets?callback=jQuery9734926&type=1&area=1&skuIds=J_11476104681&source=item-pc
看到这里是不是很激动了,你其实可以换一些其他的JD商品ID一样能获取到当前价格和最高价格已经那什么价格我也不清楚,我们需要做的只是写一个Httpclient模拟请求这个接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets?callback=jQuery9734926&type=1&area=1&skuIds=J_"+"11476104681"+"&source=item-pc", null);
System.out.println(doGet);
结果是这样:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后面的你直接解析下JSON字符串那么你要的数据就GET到了。
注意一下
这是对回调请求到的数据进行的再请求获取,这只是对前面动态获取商品价格的一个补充,这种情况是价格本身通过主链接没有带到页面上而是加载过程中异步请求填充的,还有的时候是数据带过来了但是有相关的JS进行了相关处理我们还是获取不到,这个时候我们就得通过其他手段来获取这个数据,后面会讲解
将这些Jsoup和httpclient整合成一个爬虫模板完全可以完成你一些基本的爬取数据的操作,至于怎么整合就看个人喜好了。
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-
使用HttpClient实现文件的上传下载方法
1 HTTP HTTP 协议可能是现在 Internet 上使用得最多.最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源. 虽然在 JDK 的 java.net 包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活.HttpClient 用来提供高效的.最新的.功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议. 一般的情况下我们都是使用Chrome或者
-
httpclient模拟post请求json封装表单数据的实现方法
废话不说上代码: public static String httpPostWithJSON(String url) throws Exception { HttpPost httpPost = new HttpPost(url); CloseableHttpClient client = HttpClients.createDefault(); String respContent = null; // json方式 JSONObject jsonParam = new JSONObject(
-
java web中 HttpClient模拟浏览器登录后发起请求
HttpClient模拟浏览器登录后发起请求 浏览器实现这个效果需要如下几个步骤: 1请求一个需要登录的页面或资源 2服务器判断当前的会话是否包含已登录信息.如果没有登录重定向到登录页面 3手工在登录页面录入正确的账户信息并提交 4服务器判断登录信息是否正确,如果正确则将登录成功信息保存到session中 5登录成功后服务器端给浏览器返回会话的SessionID信息保存到客户端的Cookie中 6浏览器自动跳转到之前的请求地址并携带之前的Cookie(包含登录成功的SessionID) 7服务器
-
HttpClient基础解析
本文讲述了HttpClient基础知识,对相关概念进行解释在这里分享给大家,供大家参考. 1. 请求执行: HttpClient最重要的功能是执行HTTP方法.执行HTTP方法涉及一个或多个HTTP请求/ HTTP响应交换,通常由HttpClient内部处理.用户期望提供一个请求对象来执行,并且希望HttpClient将请求发送到目标服务器返回相应的响应对象,如果执行失败则抛出异常. 很自然,HttpClient API的主要入口点是定义上述合同的HttpClient接口. 这是一个请求执行过程
-
Java使用HttpClient实现Post请求实例
基于项目需求,想要实现Post消息推送,故采用HttpClient组件进行实现,相关代码如下(注:程序采用的httpclient和httpcore依赖包的版本为4.2.5): import org.apache.http.Header; import org.apache.http.HttpResponse; import org.apache.http.HttpStatus; import org.apache.http.client.HttpClient; import org.apache
-
java 中HttpClient传输xml字符串实例详解
java 中HttpClient传输xml字符串实例详解 介绍:我现在有一个对象page,需要将page对象转换为xml格式并以binary方式传输到服务端 其中涉及到的技术点有: 1.对象转xml流 2.输出流转输入流 3.httpClient发送二进制流数据 POM文件依赖配置 <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifact
-

Java爬虫Jsoup+httpclient获取动态生成的数据
Java爬虫Jsoup+httpclient获取动态生成的数据 前面我们详细讲了一下Jsoup发现这玩意其实也就那样,只要是可以访问到的静态资源页面都可以直接用他来获取你所需要的数据,详情情跳转-Jsoup爬虫详解,但是很多时候网站为了防止数据被恶意爬取做了很多遮掩,比如说加密啊动态加载啊,这无形中给我们写的爬虫程序造成了很大的困扰,那么我们如何来突破这个梗获取我们急需的数据呢, 下面我们来详细讲解一下如何获取 String startPage="https://item.jd.com/1147
-
详解java爬虫jsoup解析多空格class数据
在使用jsoup爬取其他网站数据的时候,发现class是带空格的多选择,如果直接使用doc.getElementsByClass("class的值"),这种方法获取不到想要的数据. 1.问题描述: 在使用jsoup爬取其他网站数据的时候,发现class是带空格的多选择,如果直接使用doc.getElementsByClass("class的值"),这种方法获取不到想要的数据. 爬取网站页面结构如下: 2.其中文章列表的div为:<div class="
-
Java爬虫(Jsoup与WebDriver)的使用
一.Jsoup爬虫 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据. 以博客园首页为例 1.idea新建maven工程 pom.xml导入jsoup依赖 <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <
-
vue类名如何获取动态生成的元素
目录 类名获取动态生成的元素 如何获取并操作dom元素 类名获取动态生成的元素 首先注意的是,该元素必须在id为app这个元素里面 new Vue({ el: "#app", }) 其次是由于动态生成的,想获取到该元素,需要在created里使用nextTick. 并且可以 $(’.circle’ + i)拼接想要的元素类名. this.$nextTick(() => { for (var i = 1; i < this.carlist.leng
-
通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求.异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据. 至于读取静态网页内容的方式,有兴趣的可以查看本文内容. 这里我们以爬取淘宝评论为例子讲解一下如何去做到的. 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析json数据
-
java爬虫jsoup解析HTML的工具学习
目录 前言 下载 一个文档的对象模型 获取 Document 对象 解析并提取 HTML 元素 使用传统的操作DOM的方式 选择器 修改获取数据 前言 使用python写爬虫的人,应该都听过beautifulsoup4这个包,用来它来解析网页甚是方便.那么在java里有没有类似的包呢?当然有啦!而且也非常好用.下面隆重介绍jsoup! jsoup 实现了 WHATWG HTML5 规范,能够与现代浏览器解析成相同的DOM.其解析器能够尽最大可能从你提供的HTML文档来创建一个干净的解析结果,无论
-
jQuery获取动态生成的元素示例
需求描述:页面上可以动态添加数据,比如table,点击按钮可以动态添加行.又或页面 加载时table数据是通过ajax从后台获取的.而这时我们想要获取其中的某个值,又该如何获取呢? 如果是要通过某个事件来获取的比如click,mouseover等等,则可以使用live()方法 复制代码 代码如下: $(".button").live("click",function(){ console.info($("#mytd").html()); }) 而
-
C#获取动态生成的CheckBox值
给你推荐两种方法,一种是向服务器容器控件里添加子控件(即向runat=server的控件的Controls里添加控件),第二种是就是你的这种拼接HTML的方法不过这种方法必须设置控件的name属性,然后在Request.Form["控件的name"]里获得控件的值,推荐使用第一种方法,更直观一些,第二种无法记录提交以后的状态,代码如下 第一种 后台 using System.Web.UI.HtmlControls; protected void Page_Load(object sen
-
Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
1.需求及配置 需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格. 使用Maven项目,log4j记录日志,日志仅导出到控制台. Maven依赖如下(pom.xml) <dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId>
-
Java 爬虫工具Jsoup详解
Java 爬虫工具Jsoup详解 Jsoup是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址.HTML 文本内容.它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据. jsoup 的主要功能如下: 1. 从一个 URL,文件或字符串中解析 HTML: 2. 使用 DOM 或 CSS 选择器来查找.取出数据: 3. 可操作 HTML 元素.属性.文本: jsoup 是基于 MIT 协议发布的,可放心使用于商业项目. js