手把手教学Android用jsoup解析html实例
1.jsoup介绍
很多时候,我们需要从各种网页上面抓取数据,而jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
jsoup官方文档:https://jsoup.org/cookbook/
2.使用场景
下面是一张关于美食的截图,可以留意到这是一个html网页,当我们想要抓取里面的数据的时候,jsoup就能帮到我们很多。
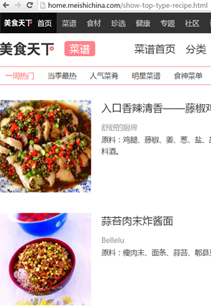
接下来开始手把手教学
首先,也是很重要的一步,就是下载jar包,丢到libs里面
jar包下载地址:http://jsoup.org/download
Android studio玩家可以不下载jar包,在Gradle里面加入
dependencies {
compile 'org.jsoup:jsoup:1.9.2'
}
然后,找到你心仪的网页去抓取数据
这里我们我继续使用美食的网页,然后右键查看网页源码,或者按F12,接下来可以看到一大堆标签:

找到需要的,例如上图这个 “美食天下” ,可以看到 “美食天下” 是放在以 <div class="top-bar" id="J_top_bar"> 为节点的 <a title="美食天下" 中,要获取这个“美食天下”,代码可以这样写:
try {
//从一个URL加载一个Document对象。
Document doc = Jsoup.connect("http://home.meishichina.com/show-top-type-recipe.html").get();
//选择“美食天下”所在节点
Elements elements = doc.select("div.top-bar");
//打印 <a>标签里面的title
Log.i("mytag",elements.select("a").attr("title"));
}catch(Exception e) {
Log.i("mytag", e.toString());
}
接下来看一下打印出来的结果:
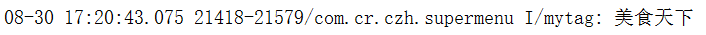
Jsoup.connect(String url)方法从一个URL加载一个Document对象。如果从该URL获取HTML时发生错误,便会抛出 IOException,应适当处理。
一旦拥有了一个Document,你就可以使用Document中适当的方法或它父类 Element和Node中的方法来取得相关数据。
public class Element extends Node public class Document extends Element
很多文章都是说一大堆原理然后放出一个简单的例子,就跟我上面简单的打了一个log一样,然后发现用起来的时候是没那么简单的。为了大家能不看文档也可以直接使用(并且看不懂那一大堆标签也可以用),我决定再举一个例子(其实也就是比上面多打几个log):
下图红色框框是我们要获取的数据,可以看到他们对应的节点就是蓝色圆圈里面的<div class="xxx">

废话不多说上代码
try {
//还是一样先从一个URL加载一个Document对象。
Document doc = Jsoup.connect("http://home.meishichina.com/show-top-type-recipe.html").get();
//“椒麻鸡”和它对应的图片都在<div class="pic">中
Elements titleAndPic = doc.select("div.pic");
//使用Element.select(String selector)查找元素,使用Node.attr(String key)方法取得一个属性的值
Log.i("mytag", "title:" + titleAndPic.get(1).select("a").attr("title") + "pic:" + titleAndPic.get(1).select("a").select("img").attr("data-src"));
//所需链接在<div class="detail">中的<a>标签里面
Elements url = doc.select("div.detail").select("a");
Log.i("mytag", "url:" + url.get(i).attr("href"));
//原料在<p class="subcontent">中
Elements burden = doc.select("p.subcontent");
//对于一个元素中的文本,可以使用Element.text()方法
Log.i("mytag", "burden:" + burden.get(1).text());
}catch(Exception e) {
Log.i("mytag", e.toString());
}
大功告成,接下来看看log

没有问题!那么教学可以结束了!
注意:
Jsoup.connect(String url)方法不能运行在主线程,否则会报NetworkOnMainThreadException
最后上一张应用在项目的效果图:
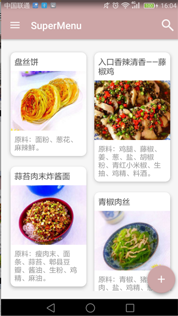
有没有发现熟悉的椒麻鸡?很酷炫有木有!
小结
整堂课分几步:
1.下载jar包并丢到libs(或者在gradle)
2.找到心仪的网页
3.用Jsoup.connect()获取网页的document
4.查看网页源码,对准你想要的地方,给他来一个Element.select(String selector)
5.用Node.attr(String key)或者Element.text()方法把数据抽出来
6.没有6了就是这么简单!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Android开发之利用jsoup解析HTML页面的方法
本文实例讲述了Android利用jsoup解析HTML页面的方法.分享给大家供大家参考,具体如下: 这节主要是讲解jsoup解析HTML页面.由于在android开发过程中,不可避免的涉及到web页面的抓取,解析,展示等等,所以,在这里我主要展示下利用jsoup jar包来抓取cnbeta.com网站的话题分类的实例. 下面是主要的代码,由于使用及其简单,我这里就不再多说了: package com.android.web; import java.io.BufferedInputStream;
-
Android使用Jsoup解析Html表格的方法
本文实例讲述了Android使用Jsoup解析Html表格的方法.分享给大家供大家参考,具体如下: 看代码吧,可解析表中的label text button 自己根据需要再添加,呵呵 import java.util.ArrayList; import java.util.List; import org.apache.http.NameValuePair; import org.apache.http.message.BasicNameValuePair; import org.jsoup.J
-
Jsoup解析HTML实例及文档方法详解
解析和遍历一个HTML文档 如何解析一个HTML文档: 复制代码 代码如下: String html = "<html><head><title>First parse</title></head>" + "<body><p>Parsed HTML into a doc.</p></body></html>";Document doc = Jso
-
Jsoup解析html实现招聘信息查询功能
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址.HTML 文本内容.它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据. 下面是招聘网站的html信息: <div class="newlist_list_content" id="newlist_list_content_table"> <table width="853" class=&
-
crawler4j抓取页面使用jsoup解析html时的解决方法
crawler4j对已有编码的页面抓取效果不错,用jsoup解析,很多会jquery的程序员都可以操作.但是,crawler4j对response没有指定编码的页面,解析成乱码,很让人烦恼.在找了苦闷之中,无意间发现一年代已久的博文,可以解决问题,修改 Page.load() 中的 contentData 编码即可,这让我心中顿时舒坦了很多,接下来的问题都引刃而解了. 复制代码 代码如下: public void load(HttpEntity entity) throws Exception
-
Java中使用开源库JSoup解析HTML文件实例
HTML是WEB的核心,互联网中你看到的所有页面都是HTML,不管它们是由JavaScript,JSP,PHP,ASP或者是别的什么WEB技术动态生成的.你的浏览器会去解析HTML并替你去渲染它们.不过如果你需要自己在Java程序中解析HTML文档并查找某些元素,标签,属性或者检查某个特定的元素是否存在的话,那又该如何呢?如果你已经使用Java编程多年了,我相信你肯定试过去解析XML,也使用过类似DOM或者SAX这样的解析器,不过很有可能你从未进行过任何的HTML解析的工作.更讽刺的是,在Jav
-
手把手教学Android用jsoup解析html实例
1.jsoup介绍 很多时候,我们需要从各种网页上面抓取数据,而jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据. jsoup官方文档:https://jsoup.org/cookbook/ 2.使用场景 下面是一张关于美食的截图,可以留意到这是一个html网页,当我们想要抓取里面的数据的时候,jsoup就能帮到我们很多. 接下来开始手把手教学 首先,也是很
-
android针对json数据解析方法实例分析
本文实例讲述了android针对json数据解析方法.分享给大家供大家参考.具体如下: JSON的定义: 一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性.业内主流技术为其提供了完整的解决方案(有点类似于正则表达式 ,获得了当今大部分语言的支持),从而可以在不同平台间进行数据交换.JSON采用兼容性很高的文本格式,同时也具备类似于C语言体系的行为. – Json.org JSON Vs XML 1.JSON和XML的数据可读性基本相同 2.JSON和XML同样拥有丰富的解析手段 3.
-
android 使用XStream解析xml的实例
1,要解析的xml文件文件 xml="<apps>\n" + " <app>\n" + " <id>1</id>\n" + " <name>burn</name>\n" + " <version>1.0</version>\n" + " <info>\n" + " <
-
android原生JSON解析实例
我们在android项目开发的时候,经常要对JSON进行解析,很多朋友在寻找相关的实例,小编整理详细的相关分析说明,一起来看下. JSONObject:JSON数据封装对象 JSONArray:JSON数据封装数组 <?xml version="1.0" encoding="utf-8"?> <LinearLayout android:orientation="vertical" xmlns:android="http
-
使用jsoup解析html的table中的文本信息实例
jsoup是一个非常好用的html解析工具.使用时需要下载相应的jar包. 下面就是我使用jsoup解析html的表格的java源代码. 亲测可用! public void parse(){ String htmlStr = "<table id=kbtable >" + "<tr> " + "<td width=123>" + "<div id=12>这里是要获取的数据1</div
-
Android json数据解析详解及实例代码
Android json数据解析详解 移动开发经常要与服务器数据交互,也常使用json数据格式,那就说说Android json解析. 1.最简单json格式解析如下: //解析json ry { JSONTokener jsonParser = new JSONTokener(strResult); JSONObject jsonObj = (JSONObject) jsonParser.nextValue(); String strsportsTitle = jsonObj.getStri