.NET Core 实现定时抓取网站文章并发送到邮箱
前言
大家好,我是晓晨。许久没有更新博客了,今天给大家带来一篇干货型文章,一个每隔5分钟抓取博客园首页文章信息并在第二天的上午9点发送到你的邮箱的小工具。比如我在2018年2月14日,9点来到公司我就会收到一封邮件,是2018年2月13日的博客园首页的文章信息。写这个小工具的初衷是,一直有看博客的习惯,但是最近由于各种原因吧,可能几天都不会看一下博客,要是中途错过了什么好文可是十分心疼的哈哈。所以做了个工具,每天归档发到邮箱,妈妈再也不会担心我错过好的文章了。为什么只抓取首页?因为博客园首页文章的质量相对来说高一些。
准备
作为一个持续运行的工具,没有日志记录怎么行,我准备使用的是NLog来记录日志,它有个日志归档功能非常不错。在http请求中,由于网络问题吧可能会出现失败的情况,这里我使用Polly来进行Retry。使用HtmlAgilityPack来解析网页,需要对xpath有一定了解。下面是详细说明:
| 组件名 | 用途 | github |
|---|---|---|
| NLog | 记录日志 | https://github.com/NLog/NLog |
| Polly | 当http请求失败,进行重试 | https://github.com/App-vNext/Polly |
| HtmlAgilityPack | 网页解析 | https://github.com/zzzprojects/html-agility-pack |
| MailKit | 发送邮件 | https://github.com/jstedfast/MailKit |
有不了解的组件,可以通过访问github获取资料。
参考文章
http://www.jb51.net/article/112595.htm
获取&解析博客园首页数据
我是用的是HttpWebRequest来进行http请求,下面分享一下我简单封装的类库:
using System;
using System.IO;
using System.Net;
using System.Text;
namespace CnBlogSubscribeTool
{
/// <summary>
/// Simple Http Request Class
/// .NET Framework >= 4.0
/// Author:stulzq
/// CreatedTime:2017-12-12 15:54:47
/// </summary>
public class HttpUtil
{
static HttpUtil()
{
//Set connection limit ,Default limit is 2
ServicePointManager.DefaultConnectionLimit = 1024;
}
/// <summary>
/// Default Timeout 20s
/// </summary>
public static int DefaultTimeout = 20000;
/// <summary>
/// Is Auto Redirect
/// </summary>
public static bool DefalutAllowAutoRedirect = true;
/// <summary>
/// Default Encoding
/// </summary>
public static Encoding DefaultEncoding = Encoding.UTF8;
/// <summary>
/// Default UserAgent
/// </summary>
public static string DefaultUserAgent =
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
;
/// <summary>
/// Default Referer
/// </summary>
public static string DefaultReferer = "";
/// <summary>
/// httpget request
/// </summary>
/// <param name="url">Internet Address</param>
/// <returns>string</returns>
public static string GetString(string url)
{
var stream = GetStream(url);
string result;
using (StreamReader sr = new StreamReader(stream))
{
result = sr.ReadToEnd();
}
return result;
}
/// <summary>
/// httppost request
/// </summary>
/// <param name="url">Internet Address</param>
/// <param name="postData">Post request data</param>
/// <returns>string</returns>
public static string PostString(string url, string postData)
{
var stream = PostStream(url, postData);
string result;
using (StreamReader sr = new StreamReader(stream))
{
result = sr.ReadToEnd();
}
return result;
}
/// <summary>
/// Create Response
/// </summary>
/// <param name="url"></param>
/// <param name="post">Is post Request</param>
/// <param name="postData">Post request data</param>
/// <returns></returns>
public static WebResponse CreateResponse(string url, bool post, string postData = "")
{
var httpWebRequest = WebRequest.CreateHttp(url);
httpWebRequest.Timeout = DefaultTimeout;
httpWebRequest.AllowAutoRedirect = DefalutAllowAutoRedirect;
httpWebRequest.UserAgent = DefaultUserAgent;
httpWebRequest.Referer = DefaultReferer;
if (post)
{
var data = DefaultEncoding.GetBytes(postData);
httpWebRequest.Method = "POST";
httpWebRequest.ContentType = "application/x-www-form-urlencoded;charset=utf-8";
httpWebRequest.ContentLength = data.Length;
using (var stream = httpWebRequest.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
}
try
{
var response = httpWebRequest.GetResponse();
return response;
}
catch (Exception e)
{
throw new Exception(string.Format("Request error,url:{0},IsPost:{1},Data:{2},Message:{3}", url, post, postData, e.Message), e);
}
}
/// <summary>
/// http get request
/// </summary>
/// <param name="url"></param>
/// <returns>Response Stream</returns>
public static Stream GetStream(string url)
{
var stream = CreateResponse(url, false).GetResponseStream();
if (stream == null)
{
throw new Exception("Response error,the response stream is null");
}
else
{
return stream;
}
}
/// <summary>
/// http post request
/// </summary>
/// <param name="url"></param>
/// <param name="postData">post data</param>
/// <returns>Response Stream</returns>
public static Stream PostStream(string url, string postData)
{
var stream = CreateResponse(url, true, postData).GetResponseStream();
if (stream == null)
{
throw new Exception("Response error,the response stream is null");
}
else
{
return stream;
}
}
}
}
获取首页数据
string res = HttpUtil.GetString(https://www.cnblogs.com);
解析数据
我们成功获取到了html,但是怎么提取我们需要的信息(文章标题、地址、摘要、作者、发布时间)呢。这里就亮出了我们的利剑HtmlAgilityPack,他是一个可以根据xpath来解析网页的组件。
载入我们前面获取的html:
HtmlDocument doc = new HtmlDocument(); doc.LoadHtml(html);

从上图中,我们可以看出,每条文章所有信息都在一个class为post_item的div里,我们先获取所有的class=post_item的div
//获取所有文章数据项
var itemBodys = doc.DocumentNode.SelectNodes("//div[@class='post_item_body']");
我们继续分析,可以看出文章的标题在class=post_item_body的div下面的h3标签下的a标签,摘要信息在class=post_item_summary的p标签里面,发布时间和作者在class=post_item_foot的div里,分析完毕,我们可以取出我们想要的数据了:
foreach (var itemBody in itemBodys)
{
//标题元素
var titleElem = itemBody.SelectSingleNode("h3/a");
//获取标题
var title = titleElem?.InnerText;
//获取url
var url = titleElem?.Attributes["href"]?.Value;
//摘要元素
var summaryElem = itemBody.SelectSingleNode("p[@class='post_item_summary']");
//获取摘要
var summary = summaryElem?.InnerText.Replace("\r\n", "").Trim();
//数据项底部元素
var footElem = itemBody.SelectSingleNode("div[@class='post_item_foot']");
//获取作者
var author = footElem?.SelectSingleNode("a")?.InnerText;
//获取文章发布时间
var publishTime = Regex.Match(footElem?.InnerText, "\\d+-\\d+-\\d+ \\d+:\\d+").Value;
Console.WriteLine($"标题:{title}");
Console.WriteLine($"网址:{url}");
Console.WriteLine($"摘要:{summary}");
Console.WriteLine($"作者:{author}");
Console.WriteLine($"发布时间:{publishTime}");
Console.WriteLine("--------------华丽的分割线---------------");
}
运行一下:
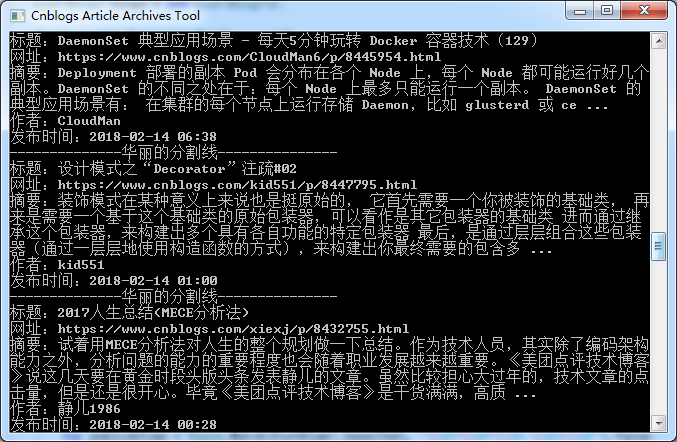
我们成功的获取了我们想要的信息。现在我们定义一个Blog对象将它们装起来。
public class Blog
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 博文url
/// </summary>
public string Url { get; set; }
/// <summary>
/// 摘要
/// </summary>
public string Summary { get; set; }
/// <summary>
/// 作者
/// </summary>
public string Author { get; set; }
/// <summary>
/// 发布时间
/// </summary>
public DateTime PublishTime { get; set; }
}
http请求失败重试
我们使用Polly在我们的http请求失败时进行重试,设置为重试3次。
//初始化重试器
_retryTwoTimesPolicy =
Policy
.Handle<Exception>()
.Retry(3, (ex, count) =>
{
_logger.Error("Excuted Failed! Retry {0}", count);
_logger.Error("Exeption from {0}", ex.GetType().Name);
});
测试一下:
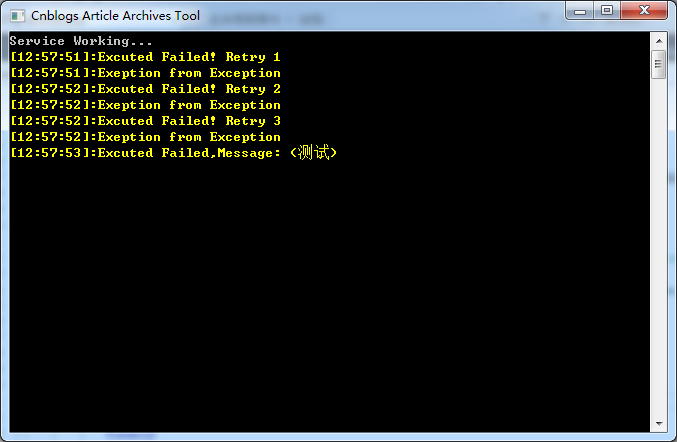
可以看到当遇到exception是Polly会帮我们重试三次,如果三次重试都失败了那么会放弃。
发送邮件
使用MailKit来进行邮件发送,它支持IMAP,POP3和SMTP协议,并且是跨平台的十分优秀。下面是根据前面园友的分享自己封装的一个类库:
using System.Collections.Generic;
using CnBlogSubscribeTool.Config;
using MailKit.Net.Smtp;
using MimeKit;
namespace CnBlogSubscribeTool
{
/// <summary>
/// send email
/// </summary>
public class MailUtil
{
private static bool SendMail(MimeMessage mailMessage,MailConfig config)
{
try
{
var smtpClient = new SmtpClient();
smtpClient.Timeout = 10 * 1000; //设置超时时间
smtpClient.Connect(config.Host, config.Port, MailKit.Security.SecureSocketOptions.None);//连接到远程smtp服务器
smtpClient.Authenticate(config.Address, config.Password);
smtpClient.Send(mailMessage);//发送邮件
smtpClient.Disconnect(true);
return true;
}
catch
{
throw;
}
}
/// <summary>
///发送邮件
/// </summary>
/// <param name="config">配置</param>
/// <param name="receives">接收人</param>
/// <param name="sender">发送人</param>
/// <param name="subject">标题</param>
/// <param name="body">内容</param>
/// <param name="attachments">附件</param>
/// <param name="fileName">附件名</param>
/// <returns></returns>
public static bool SendMail(MailConfig config,List<string> receives, string sender, string subject, string body, byte[] attachments = null,string fileName="")
{
var fromMailAddress = new MailboxAddress(config.Name, config.Address);
var mailMessage = new MimeMessage();
mailMessage.From.Add(fromMailAddress);
foreach (var add in receives)
{
var toMailAddress = new MailboxAddress(add);
mailMessage.To.Add(toMailAddress);
}
if (!string.IsNullOrEmpty(sender))
{
var replyTo = new MailboxAddress(config.Name, sender);
mailMessage.ReplyTo.Add(replyTo);
}
var bodyBuilder = new BodyBuilder() { HtmlBody = body };
//附件
if (attachments != null)
{
if (string.IsNullOrEmpty(fileName))
{
fileName = "未命名文件.txt";
}
var attachment = bodyBuilder.Attachments.Add(fileName, attachments);
//解决中文文件名乱码
var charset = "GB18030";
attachment.ContentType.Parameters.Clear();
attachment.ContentDisposition.Parameters.Clear();
attachment.ContentType.Parameters.Add(charset, "name", fileName);
attachment.ContentDisposition.Parameters.Add(charset, "filename", fileName);
//解决文件名不能超过41字符
foreach (var param in attachment.ContentDisposition.Parameters)
param.EncodingMethod = ParameterEncodingMethod.Rfc2047;
foreach (var param in attachment.ContentType.Parameters)
param.EncodingMethod = ParameterEncodingMethod.Rfc2047;
}
mailMessage.Body = bodyBuilder.ToMessageBody();
mailMessage.Subject = subject;
return SendMail(mailMessage, config);
}
}
}
测试一下:

说明
关于抓取数据和发送邮件的调度,程序异常退出的数据处理等等,在此我就不详细说明了,有兴趣的看源码(文末有github地址)
抓取数据是增量更新的。不用RSS订阅的原因是RSS更新比较慢。
完整的程序运行截图:
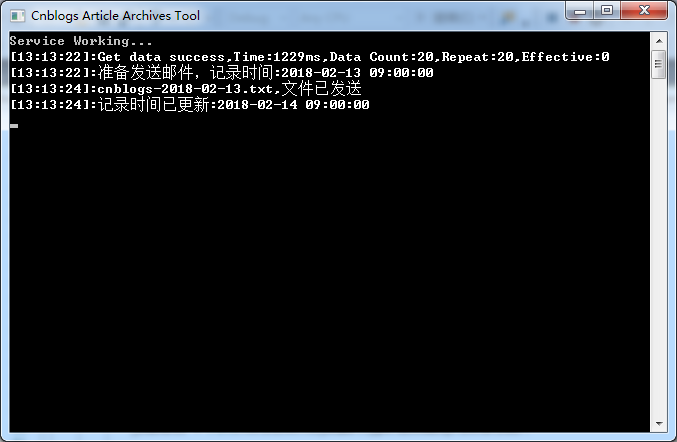
每发送一次邮件,程序就会将记录时间调整到今天的9点,然后每次抓取数据之后就会判断当前时间减去记录时间是否大于等于24小时,如果符合就发送邮件并且更新记录时间。
收到的邮件截图:
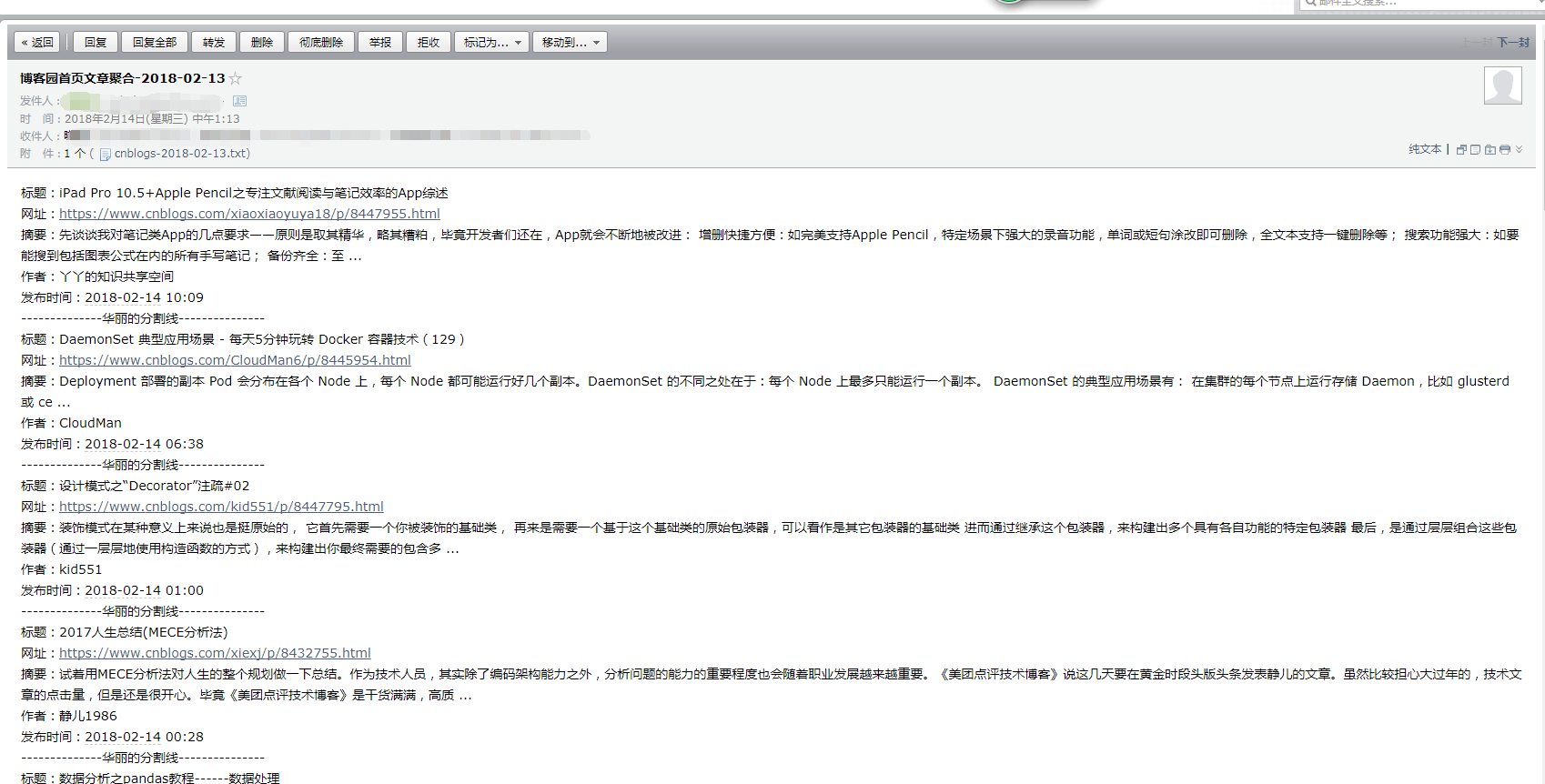
截图中的邮件标题为13日但是邮件内容为14日,是因为我为了演示效果,将今天(14日)的数据copy到了13日的数据里面,不要被误导了。
还提供一个附件便于收集整理:

好了介绍完毕,我自己已经将这个小工具部署到服务器,想要享受这个服务的可以在评论留下邮箱(手动滑稽)。
相关推荐
-

.NET Core 实现定时抓取网站文章并发送到邮箱
前言 大家好,我是晓晨.许久没有更新博客了,今天给大家带来一篇干货型文章,一个每隔5分钟抓取博客园首页文章信息并在第二天的上午9点发送到你的邮箱的小工具.比如我在2018年2月14日,9点来到公司我就会收到一封邮件,是2018年2月13日的博客园首页的文章信息.写这个小工具的初衷是,一直有看博客的习惯,但是最近由于各种原因吧,可能几天都不会看一下博客,要是中途错过了什么好文可是十分心疼的哈哈.所以做了个工具,每天归档发到邮箱,妈妈再也不会担心我错过好的文章了.为什么只抓取首页?因为博客园首页文章
-
PowerShell小技巧之定时抓取屏幕图像
昨天的博文写了定时记录操作系统行为,其实说白了就是抓取了击键的记录和对应窗口的标题栏,而很多应用程序标题栏又包含当时记录的文件路径和文件名,用这种方式可以大致记录操作了哪些程序,打开了哪些文件,以及敲击了哪些按键.事实上这样记录操作系统的行为显得相对单薄一点,因为记录的内容不太形象,对于新手来说太过于隐晦了,对于人类来说,图像会比文字更加有利于用户理解.当操作系统不方便装屏幕记录软件,但又需要看已经登录用户在干什么的时候,用PowerShell的脚本来实现定时抓取图像的方式记录操作,查看图像就知
-
python通过链接抓取网站详解
在本篇文章里,你将会学习把这些基本方法融合到一个更灵活的网站 爬虫中,该爬虫可以跟踪任意遵循特定 URL 模式的链接. 这种爬虫非常适用于从一个网站抓取所有数据的项目,而不适用于从特 定搜索结果或页面列表抓取数据的项目.它还非常适用于网站页面组织 得很糟糕或者非常分散的情况. 这些类型的爬虫并不需要像上一节通过搜索页面进行抓取中采用的定位 链接的结构化方法,因此在 Website 对象中不需要包含描述搜索页面 的属性.但是由于爬虫并不知道待寻找的链接的位置,所以你需要一些 规则来告诉它选择哪种页
-
Nginx反爬虫策略,防止UA抓取网站
新增反爬虫策略文件: vim /usr/www/server/nginx/conf/anti_spider.conf 文件内容 #禁止Scrapy等工具的抓取 if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) { return 403; } #禁止指定UA及UA为空的访问 if ($http_user_agent ~ "WinHttp|WebZIP|FetchURL|node-superagent|java/|FeedDemon|Jullo|Ji
-
python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
JAVA使用爬虫抓取网站网页内容的方法
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法.分享给大家供大家参考.具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下: // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar
-
php抓取网站图片并保存的实现方法
php如何实现抓取网页图片,相较于手动的粘贴复制,使用小程序要方便快捷多了,喜欢编程的人总会喜欢制作一些简单有用的小软件,最近就参考了网上一个php抓取图片代码,封装了一个php远程抓取图片的类,测试了一下,效果还不错分享给大家,代码如下: 以上就是为大家分享的php抓取网站图片并保存的实现方法,希望对大家的学习有所帮助.
-
C#使用正则表达式抓取网站信息示例
本文实例讲述了C#使用正则表达式抓取网站信息的方法.分享给大家供大家参考,具体如下: 这里以抓取京东商城商品详情为例. 1.创建JdRobber.cs程序类 public class JdRobber { /// <summary> /// 判断是否京东链接 /// </summary> /// <param name="param"></param> /// <returns></returns> public
-
Python使用scrapy抓取网站sitemap信息的方法
本文实例讲述了Python使用scrapy抓取网站sitemap信息的方法.分享给大家供大家参考.具体如下: import re from scrapy.spider import BaseSpider from scrapy import log from scrapy.utils.response import body_or_str from scrapy.http import Request from scrapy.selector import HtmlXPathSelector c
-
thinkphp 抓取网站的内容并且保存到本地的实例详解
thinkphp 抓取网站的内容并且保存到本地的实例详解 我需要写这么一个例子,到电子课本网下载一本电子书. 电子课本网的电子书,是把书的每一页当成一个图片,然后一本书就是有很多张图片,我需要批量的进行下载图片操作. 下面是代码部分: public function download() { $http = new \Org\Net\Http(); $url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/"; $localUrl =