python数据分析数据标准化及离散化详解
本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下
标准化
1、离差标准化
是对原始数据的线性变换,使结果映射到[0,1]区间。方便数据的处理。消除单位影响及变异大小因素影响。
基本公式为:
x'=(x-min)/(max-min)
代码:
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#离差标准化
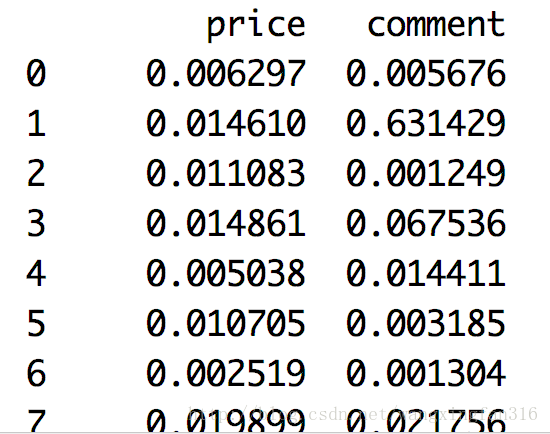
data1 = (data-data.min())/(data.max()-data.min())
print(data1)
运行结果
2、标准差标准化
消除单位影响以及变量自身变异影响。(零-均值标准化)
基本公式为:
x'=(x-平均数)/标准差
python代码:
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#标准差标准化
data1 = (data-data.mean())/data.std()
print(data1)
运行结果:

3、小数定标标准化
消除单位影响
基本公式为:
其中j=lg(max(|x|)),即以10为底的x的绝对值最大的对数
x' = x/10^j
实现代码为:
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
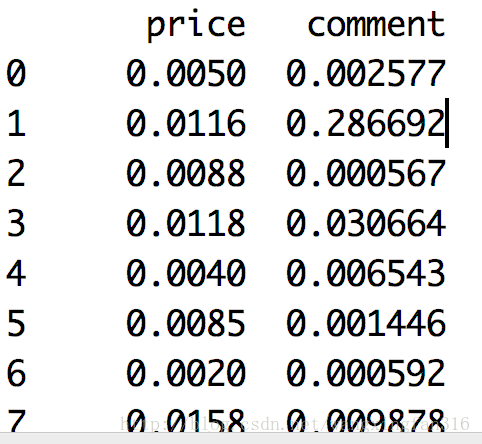
#标准差标准化
j = np.ceil(np.log10(data.abs().max()))#进一取整,abs()为取绝对值
data1 = data/10**j
print(data1)
结果:
离散化
离散化是程序设计中一个常用的技巧,它可以有效的降低时间复杂度。其基本思想就是在众多可能的情况中,只考虑需要用的值。离散化可以改进一个低效的算法,甚至实现根本不可能实现的算法
1、等宽离散化
将连续数据按照等宽区间标准离散化数据,好处之一是处理的数据是有限个数据而不是无限多。
使用pandas的cut方法。非等宽只需要更改cut的第二个参数,例如:第二个参数为[1,100,3000,10000,200000],即划分为了四个区间。
#!/user/bin/env python
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select price,comment from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#离散化
data1 = data['price'].T.values#获取价格的一维数组
lable=['很低','低','中','高','很高']
data2 = pd.cut(data1,5,labels=lable)
print(data2)
执行结果:

2、等频率离散化
将相同数量的数据放进一个区间。
3、一维聚类离散化
按属性对数据进行聚类离散。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python运用于数据分析的简单教程
- 在MAC上搭建python数据分析开发环境
- R语言 vs Python对比:数据分析哪家强?
- 利用python实现数据分析
- Python数据分析之真实IP请求Pandas详解
- Python数据分析之如何利用pandas查询数据示例代码
- Python数据分析中Groupby用法之通过字典或Series进行分组的实例
- 对Python进行数据分析_关于Package的安装问题
- R vs. Python 数据分析中谁与争锋?
- Python使用SQLite和Excel操作进行数据分析
相关推荐
-

R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W
-
Python数据分析之如何利用pandas查询数据示例代码
前言 在数据分析领域,最热门的莫过于Python和R语言,本文将详细给大家介绍关于Python利用pandas查询数据的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 示例代码 这里的查询数据相当于R语言里的subset功能,可以通过布尔索引有针对的选取原数据的子集.指定行.指定列等.我们先导入一个student数据集: student = pd.io.parsers.read_csv('C:\\Users\\admin\\Desktop\\student.csv')
-
在MAC上搭建python数据分析开发环境
最近工作转型到数据开发领域,想在本地搭建一个数据开发环境.自己有三年python开发经验,马上想到使用numpy.scipy.sklearn.pandas搭建一套数据开发环境. ubuntu的环境,百度中文章比较多,搭建起来非常顺利.MAC环境的资料比较少,百度出来的,已经不对了,那我就来补充一篇吧. MAC自带python,python的安装我就不多说了. 安装pip 我喜欢用pip安装python库,非常方便,pip的安装只能用源码了. #下载源代码 https://pypi.python.
-
Python数据分析之真实IP请求Pandas详解
前言 pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的 .Series 和 DataFrame 分别对应于一维的序列和二维的表结构.pandas 约定俗成的导入方法如下: from pandas import Series,DataFrame import pandas as pd 1.1. Pandas分析步骤 1.载入日志数据 2.载
-
利用python实现数据分析
1:文件内容格式为json的数据如何解析 import json,os,sys current_dir=os.path.abspath(".") filename=[file for file in os.listdir(current_dir) if ".txt" in file]#得到当前目录中,后缀为.txt的数据文件 fn=filename[0] if len(filename)==1 else "" #从list中取出第一个文件名 if
-
R vs. Python 数据分析中谁与争锋?
当我们想要选择一种编程语言进行数据分析时,相信大多数人都会想到R和Python--但是从这两个非常强大.灵活的数据分析语言中二选一是非常困难的. 我承认我还没能从这两个数据科学家喜爱的语言中选出更好的那一个.因此,为了使事情变得有趣,本文将介绍一些关于这两种语言的详细信息,并将决策权留给读者.值得一提的是,有多种途径可以了解这两种语言各自的优缺点.然而在我看来,这两种语言之间其实有很强的关联. Stack Overflow趋势对比 上图显示了自从2008年(Stack Overflow 成立)以
-
Python使用SQLite和Excel操作进行数据分析
昨日,女票拿了一个Excel文档,里面有上万条数据要进行分析,刚开始一个字段分析,Excel用的不错,还能搞定,到后来两个字段的分析,还有区间比如年龄段的数据分析,实在是心疼的不行,于是就想给她程序处理之. 当然,我是一直C++和Qt的,当时就想直接Qt+sqlite3写入数据库,然后就各种数据查询就行了,可做起来却发现,她机器上没有Qt环境,没有C++编译器,得,如果配置环境也得几个小时了,可当时根本没有那么多时间来做,幸好,之前还看过一些Python的东西,并且Python环境好配啊,于是就
-
Python运用于数据分析的简单教程
最近,Analysis with Programming加入了Planet Python.作为该网站的首批特约博客,我这里来分享一下如何通过Python来开始数据分析.具体内容如下: 数据导入 导入本地的或者web端的CSV文件: 数据变换: 数据统计描述: 假设检验 单样本t检验: 可视化: 创建自定义函数. 数据导入 这是很关键的一步,为了后续的分析我们首先需要导入数据.通常来说,数据是CSV格式,就算不是,至少也可以转
-
对Python进行数据分析_关于Package的安装问题
一.为什么要使用Python进行数据分析? python拥有一个巨大的活跃的科学计算社区,拥有不断改良的库,能够轻松的集成C,C++,Fortran代码(Cython项目),可以同时用于研究和原型的构建以及生产系统的构建. 二.Python的优势与劣势: 1.Python是一种解释型语言,运行速度比编译型数据慢. 2.由于python有一个全局解释器锁(GIL),防止解释器同时执行多条python字节码,所以python不适用于高并发.多线程的应用程序. 三.使用Python进行数据分析常用的扩
-
Python数据分析中Groupby用法之通过字典或Series进行分组的实例
在数据分析中有时候需要自己定义分组规则 这里简单介绍一下用一个字典实现分组 people=DataFrame( np.random.randn(5,5), columns=['a','b','c','d','e'], index=['Joe','Steve','Wes','Jim','Travis'] ) mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'} by_column=people.grou