Python图像处理之识别图像中的文字(实例讲解)
①安装PIL:pip install Pillow(之前的博客中有写过)
②安装pytesser3:pip install pytesser3
③安装pytesseract:pip install pytesseract
④安装autopy3:
先安装wheel:pip install wheel
下载autopy3-0.51.1-cp36-cp36m-win_amd64.whl【点击打开链接】
执行命令:pip install E:\360安全浏览器下载\autopy3-0.51.1-cp36-cp36m-win_amd64.whl
##使用pip install autopy3时会报错如下:

④安装Tesseract-OCR:百度直接搜索Tesseract-OCR下载即可
这里要说明的是安装Tesseract-OCR后,其不会被默认添加至环境变量path中,已导致如下报错:

解决办法有两种:(先找到Tesseract-OCR安装文件夹,再找到tesseract.exe文件)
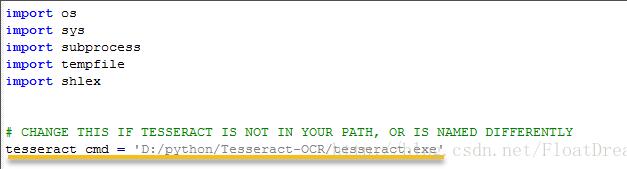
我这里的绝对路径是:D:\python\Tesseract-OCR\tesseract.exe
①将此路径添加至环境变量path中(不过我是这么做的,但是PyCharm仍旧报错)
②找到pytesseract.py文件
我这里是C:\Users\admin\AppData\Local\Programs\Python\Python36\Lib\site-packages\pytesseract\pytesseract.py
将文件中的tesseract_cmd修改为上方的绝对路径
进入正题,如何识别图像中文字
上原图:(这句是海上钢琴师中的一句经典台词)

接下来我们要通过python的pytesseract来识别图片中的字符了
# _*_ coding:utf-8 _*_ import pytesseract from PIL import Image __author__ = 'admin' im = Image.open(r'C:\Users\admin\Desktop\example.png') print(pytesseract.image_to_string(im))
效果图

以上这篇Python图像处理之识别图像中的文字(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- python 识别图片中的文字信息方法
- Python3一行代码实现图片文字识别的示例
- python实现识别手写数字 python图像识别算法
- python实现图像识别功能
- Python实现识别手写数字 Python图片读入与处理
- Python编程实现的图片识别功能示例
相关推荐
-
python实现图像识别功能
本文实例为大家分享了python实现图像识别的具体代码,供大家参考,具体内容如下 #! /usr/bin/env python from PIL import Image import pytesseract url='img/denggao.jpeg' image=Image.open(url) #image=image.convert('RGB') # RGB image=image.convert('L') # 灰度 image.load() text=pytesseract.image_
-

Python实现识别手写数字 Python图片读入与处理
写在前面 在上一篇文章Python徒手实现手写数字识别-大纲中,我们已经讲过了我们想要写的全部思路,所以我们不再说全部的思路. 我这一次将图片的读入与处理的代码写了一下,和大纲写的过程一样,这一段代码分为以下几个部分: 读入图片: 将图片读取为灰度值矩阵: 图片背景去噪: 切割图片,得到手写数字的最小矩阵: 拉伸/压缩图片,得到标准大小为100x100大小矩阵: 将图片拉为1x10000大小向量,存入训练矩阵中. 所以下面将会对这几个函数进行详解. 代码分析 基础内容 首先我们现在最前面定义基础
-
python实现识别手写数字 python图像识别算法
写在前面 这一段的内容可以说是最难的一部分之一了,因为是识别图像,所以涉及到的算法会相比之前的来说比较困难,所以我尽量会讲得清楚一点. 而且因为在编写的过程中,把前面的一些逻辑也修改了一些,将其变得更完善了,所以一切以本篇的为准.当然,如果想要直接看代码,代码全部放在我的GitHub中,所以这篇文章主要负责讲解,如需代码请自行前往GitHub. 本次大纲 上一次写到了数据库的建立,我们能够实时的将更新的训练图片存入CSV文件中.所以这次继续往下走,该轮到识别图片的内容了. 首先我们需要从文件夹中
-
Python编程实现的图片识别功能示例
本文实例讲述了Python编程实现的图片识别功能.分享给大家供大家参考,具体如下: 1. 安装PIL,官方没有WIN64位,Pillow替代 pip install Pillow-2.7.0-cp27-none-win_amd64.whl 2. 安装Pytesser 下载pytesser_v0.0.1.zip,解压后复制进Python27\Lib\site-packges\pytesser路径下,无pytesser则新建 在Python27\Lib\site-packges\pytesser中新
-
Python3一行代码实现图片文字识别的示例
自学Python3第5天,今天突发奇想,想用Python识别图片里的文字.没想到Python实现图片文字识别这么简单,只需要一行代码就能搞定 from PIL import Image import pytesseract #上面都是导包,只需要下面这一行就能实现图片文字识别 text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim') print(text) 我们以识别诗词为例 下面是我们要识别的图片 先
-
python 识别图片中的文字信息方法
最近朋友需要一个可以识别图片中的文字的程序,以前做过java验证码识别的程序: 刚好最近在做一个python项目,所以顺便用Python练练手 1.需要的环境: 2.7或者3.4版本的python 2.需要安装pytesseract库 依赖PIL和tesseract-ocr库 本地环境是ubuntu,下面说一下 具体步骤: 2.7 1.安装PIL: 直接使用pip 安装: pip install Pillow 2.安装tesseract-ocr: apt-get install tesserac
-
Python图像处理之识别图像中的文字(实例讲解)
①安装PIL:pip install Pillow(之前的博客中有写过) ②安装pytesser3:pip install pytesser3 ③安装pytesseract:pip install pytesseract ④安装autopy3: 先安装wheel:pip install wheel 下载autopy3-0.51.1-cp36-cp36m-win_amd64.whl[点击打开链接] 执行命令:pip install E:\360安全浏览器下载\autopy3-0.51.1-cp36
-
Python实现识别图像中人物的示例代码
目录 前言 环境部署 代码 总结 前言 接着上一篇:AI识别照片是谁,人脸识别face_recognition开源项目安装使用 根据项目提供的demo代码,调整了一下功能,自己写了一个识别人脸的工具代码. 环境部署 按照上一篇的安装部署就可以了. 代码 不废话,直接上代码. #!/user/bin/env python # coding=utf-8 """ @project : face_recognition @author : 剑客阿良_ALiang @file : te
-
python实现在函数图像上添加文字和标注的方法
如下所示: import matplotlib.pyplot as plt import numpy as np from matplotlib import font_manager #先确定字体,以免无法识别汉字 my_font = font_manager.FontProperties(fname= "C:/Windows/Fonts/msyh.ttc") X=np.linspace(-np.pi,np.pi,100) plt.figure(figsize=(6,5)) Y_x2
-
C#实现在图像中绘制文字图形的方法
本文实例讲述了C#实现在图像中绘制文字图形的方法.分享给大家供大家参考.具体实现方法如下: using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Text; using System.Windows.Forms; using System.Drawing.Drawing2D; using S
-
Python 获取div标签中的文字实例
预备知识点 compile 函数 compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用. 语法格式为: re.compile(pattern[, flags]) .compile(pattern[, flags]) 参数: pattern : 一个字符串形式的正则表达式 flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为: re.I 忽略大小写 re.L 表示特殊字符集 \w, \W,
-
python如何爬取网页中的文字
用Python进行爬取网页文字的代码: #!/usr/bin/python # -*- coding: UTF-8 -*- import requests import re # 下载一个网页 url = 'https://www.biquge.tw/75_75273/3900155.html' # 模拟浏览器发送http请求 response = requests.get(url) # 编码方式 response.encoding='utf-8' # 目标小说主页的网页源码 html = re
-
python opencv 找出图像中的最大轮廓并填充(生成mask)
本文主要介绍了python opencv 找出图像中的最大轮廓并填充,分享给大家,具体如下: import cv2 import numpy as np from PIL import Image from joblib import Parallel from joblib import delayed # Parallel 和 delayed是为了使用多线程处理 # 使用前需要安装joblib:pip install joblib # img_stack的shape为:num, h, w #
-
Unity实现识别图像中主体及其位置
目录 EasyDL图像分割介绍 创建应用 创建模型 EasyDL图像分割介绍 创建应用 1.进入百度AI开放平台打开控制台: 2.在左上角打开产品服务列表,找到EasyDL零门槛AI开放平台: 3.打开EasyDL图像: 4.在公有云部署-应用列表中创建一个应用: 5.创建完成后获取到AppID.API Key.Secret Key: 创建模型 1.进入EasyGL图像分割: 2.创建模型: 3.创建数据集: 4.数据导入: 上传图片,图片的数量尽量多些 导入完成后查看并标注: 框选目标所在范围
-
Python实现随机从图像中获取多个patch
经常有一些图像任务需要从一张大图中截取固定大小的patch来进行训练.这里面常常存在下面几个问题: patch的位置尽可能随机,不然数据丰富性可能不够,容易引起过拟合 如果原图较大,读图带来的IO开销可能会非常大,影响训练速度,所以最好一次能够截取多个patch 我们经常不太希望因为随机性的存在而使得图像中某些区域没有被覆盖到,所以还需要注意patch位置的覆盖程度 基于以上问题,我们可以使用下面的策略从图像中获取位置随机的多个patch: 以固定的stride获取所有patch的左上角坐标 对
-
Python 图像处理: 生成二维高斯分布蒙版的实例
在图像处理以及图像特效中,经常会用到一种成高斯分布的蒙版,蒙版可以用来做图像融合,将不同内容的两张图像结合蒙版,可以营造不同的艺术效果. 这里II 表示合成后的图像,FF 表示前景图,BB 表示背景图,MM 表示蒙版,或者直接用 蒙版与图像相乘, 形成一种渐变映射的效果.如下所示. 这里介绍一下高斯分布蒙版的特性,并且用Python实现. 高斯分布的蒙版,简单来说,就是一个从中心扩散的亮度分布图,如下所示: 亮度的范围从 1 到 0, 从中心到边缘逐渐减弱,中心的亮度值最高为1,边缘的亮度值最低