基于序列化存取实现java对象深度克隆的方法详解
我们知道,在java中,将一个非原型类型类型的对象引用,赋值给另一个对象的引用之后,这两个引用就指向了同一个对象,如:
代码如下:
public class DeepCloneTest {
private class CloneTest {
private Long myLong = new Long(1);
}
public static void main(String args[]) {
new DeepCloneTest().Test();
}
public void Test() {
CloneTest ct1 = new CloneTest();
CloneTest ct2 = ct1;
// to see if ct1 and ct2 are one same reference.
System.out.println("ct1: " + ct1);
System.out.println("ct2: " + ct2);
// if ct1 and ct2 point to one same object, then ct1.myLong == ct2.myLong.
System.out.println("ct1.myLong: " + ct1.myLong);
System.out.println("ct2.myLong: " + ct2.myLong);
// we change ct2's myLong
ct2.myLong = 2L;
// to see whether ct1's myLong was changed.
System.out.println("ct1.myLong: " + ct1.myLong);
System.out.println("ct2.myLong: " + ct2.myLong);
}
}
out put:
ct1: DeepCloneTest$CloneTest@c17164
ct2: DeepCloneTest$CloneTest@c17164
ct1.myLong: 1
ct2.myLong: 1
ct1.myLong: 2
ct2.myLong: 2
这个很easy,估计学java的都知道(不知道的是学java的么?)。
在内存中,对象的引用存放在栈中,对象的数据,存放在堆中,栈中的引用指向了堆中的对象。这里就是两个栈中的引用,指向了堆中的同一个对象,所以,当改变了 ct2 的 myLong,可以看到,ct1 的 myLong 值也随之改变,如果用图来表示,就很容易理解了:

左边的是栈区,该区中有两个引用,值相同,它们指向了右边堆区的同一个对象。
大多时候,我们会用 java 语言的这一特性做我们想做的事情,比如,将对象的引用作为入参传入一个方法中,在方法中,对引用所指对象做相应修改。但有时,我们希望构造出一个和已经存在的对象具有完全相同的内容,但引用不同的对象,为此,可以这样做:
代码如下:
public class DeepCloneTest{
// must implements Cloneable.
private class CloneTest implements Cloneable{
private Object o = new Object();
public CloneTest clone() {
CloneTest ct = null;
try {
ct = (CloneTest)super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return ct;
}
}
public static void main(String args[]) {
new DeepCloneTest().Test();
}
public void Test() {
CloneTest ct1 = new CloneTest();
CloneTest ct2 = ct1.clone();
// to see if ct1 and ct2 are one same reference.
System.out.println("ct1: " + ct1);
System.out.println("ct2: " + ct2);
// whether ct1.o == ct2.o ? yes
System.out.println("ct1.o " + ct1.o);
System.out.println("ct1.o " + ct1.o);
}
}
out put:
ct1: DeepCloneTest$CloneTest@c17164
ct2: DeepCloneTest$CloneTest@1fb8ee3
ct1.o java.lang.Object@61de33
ct1.o java.lang.Object@61de33
从输出可以看出:ct1 和 ct2 确实是两个不同的引用,所以我们想当然的认为,ct1.o 和 ct2.o 也是两个不同的对象了,但从输出可以看出并非如此!ct1.o 和 ct2.o 是同一个对象!原因在于,虽然用到了克隆,但上面只是浅度克隆,用图形来表示:
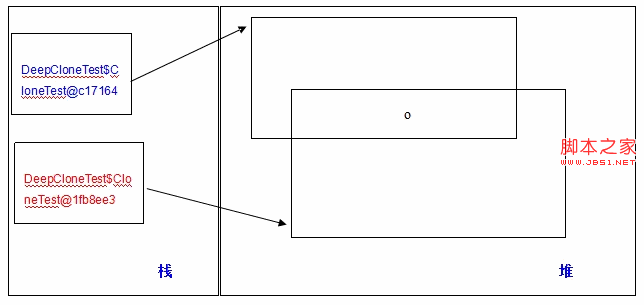
看到上面的 o 了么?其实是两个对象共享的。这就相当于,你本来有一个羊圈1,里面有一只羊,然后你又弄了一个羊圈2,在不将羊从羊圈1里牵出来的情况下,将羊也圈在了羊圈2中,你以为你有两条羊了,其实呢?大家都知道。
这就是浅度克隆的结果:如果你想让两个对象具有独立的 o,就必须再对 o 做克隆操作。可能有些人认为这没有什么,做就做呗,但想过没有,如果不止一个 o, 还有很多很多的类似 o 的东东,你都逐一去做克隆吗?显然是不太现实的。
一种解决方法是:将对象先序列化存储到流中,然后再从留中读出对象,这样就可以保证读取出来的数据和之前的对象,里面的值完全相同,就像是一个完全的拷贝。
代码如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class DeepCloneTest {
// must implements Cloneable.
private class CloneTest implements Serializable{
private static final long serialVersionUID = 1L;
private Object o = new Object();
public CloneTest deepClone() {
CloneTest ct = null;
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois= new ObjectInputStream(bais);
ct = (CloneTest)ois.readObject();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return ct;
}
}
public static void main(String args[]) {
new DeepCloneTest().Test();
}
public void Test() {
CloneTest ct1 = new CloneTest();
CloneTest ct2 = ct1.deepClone();
// to see if ct1 and ct2 are one same reference.
System.out.println("ct1: " + ct1);
System.out.println("ct2: " + ct2);
// whether ct1.o == ct2.o ? no
System.out.println("ct1.o " + ct1.o);
System.out.println("ct1.o " + ct1.o);
}
}
这个时候,内存中的数据就是这样的了:

克隆任务完成。
相关推荐
-
java 对象的克隆(浅克隆和深克隆)
java 对象的克隆 一.对象的浅克隆 (1)需要克隆类需要重写Object类的clone方法,并且实现Cloneable接口(标识接口,无需实现任何方法) (2)当需要克隆的对象中维护着另外一个引用对象,浅克隆不会克隆另外一个引用对下,而是直接复制维护的另外一个引用对象的地址. (3)对象的浅克隆也不会调用到构造方法. 以下为对象的浅克隆的一个例子: package com.clone; import java.io.Serializable; /** * Description: * 实现了
-
深入JAVA对象深度克隆的详解
有时候,我们需要把对象A的所有值复制给对象B(B = A),但是这样用等号给赋值你会发现,当B中的某个对象值改变时,同时也会修改到A中相应对象的值!也许你会说,用clone()不就行了?!你的想法只对了一半,因为用clone()时,除了基础数据和String类型的不受影响外,其他复杂类型(如集合.对象等)还是会受到影响的!除非你对每个对象里的复杂类型又进行了clone(),但是如果一个对象的层次非常深,那么clone()起来非常复杂,还有可能出现遗漏!既然用等号和clone()复制对象都会对原来
-

Java中对象的序列化方式克隆详解
Java 序列化技术可以使你将一个对象的状态写入一个Byte 流里,并且可以从其它地方把该Byte 流里的数据读出来,重新构造一个相同的对象. 简述: 用字节流的方式,复制Java对象 代码: 流克隆复制函数 public static Object deepClone(Object obj){ if(obj == null){ return null; } try { ByteArrayOutputStream byteOut = new ByteArrayOutputStream(); Ob
-
Java中对象的深复制(深克隆)和浅复制(浅克隆)介绍
1.浅复制与深复制概念 ⑴浅复制(浅克隆) 被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象.换言之,浅复制仅仅复制所考虑的对象,而不复制它所引用的对象. ⑵深复制(深克隆) 被复制对象的所有变量都含有与原来的对象相同的值,除去那些引用其他对象的变量.那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象.换言之,深复制把要复制的对象所引用的对象都复制了一遍. 2.Java的clone()方法 ⑴clone方法将对象复制了一份并返回
-
基于序列化存取实现java对象深度克隆的方法详解
我们知道,在java中,将一个非原型类型类型的对象引用,赋值给另一个对象的引用之后,这两个引用就指向了同一个对象,如: 复制代码 代码如下: public class DeepCloneTest { private class CloneTest { private Long myLong = new Long(1); } public static void main(String args[]) { new DeepCloneTest().Test(); } public void Te
-
基于js对象,操作属性、方法详解
一,概述 在Java语言中,我们可以定义自己的类,并根据这些类创建对象来使用,在Javascript中,我们也可以定义自己的类,例如定义User类.Hashtable类等等. 目前在Javascript中,已经存在一些标准的类,例如Date.Array.RegExp.String.Math.Number等等,这为我们编程提供了许多方便.但对于复杂的客户端程序而言,这些还远远不够. 与Java不同,Java2提供给我们的标准类很多,基本上满足了我们的编程需求,但是Javascript提供的标准类很
-
Java实现深度搜索DFS算法详解
目录 DFS概述 解释 思路 案例题-单身的蒙蒙 题目描述 题解 整体代码 DFS概述 深度优先搜索是一种在开发爬虫早期使用较多的方法.它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) .在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链.深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链.当不再有其他超链可选择时,
-
Java AtomicInteger类的使用方法详解
首先看两段代码,一段是Integer的,一段是AtomicInteger的,为以下: public class Sample1 { private static Integer count = 0; synchronized public static void increment() { count++; } } 以下是AtomicInteger的: public class Sample2 { private static AtomicInteger count = new AtomicIn
-
Java实现字符串切割的方法详解
今天给大家介绍一个小知识点,但是会非常的实用,就是平时我们写Java代码的时候,如果要对字符串进行切割,我们巧妙的运用一些技巧,可以把性能提升5~10倍.下面不说废话,直接来给大家上干货! 工作中常用的split()切割字符串效率高吗? 首先,我们用下面的一段代码,去拼接出来一个用逗号分隔的超长字符串,把从0开始一直到9999的每个数字都用逗号分隔,拼接成一个超长的字符串,以便于我们可以进行实验,代码如下所示: public class StringSplitTest { public stat
-
java 中enum的使用方法详解
java 中enum的使用方法详解 enum 的全称为 enumeration, 是 JDK 1.5 中引入的新特性,存放在 java.lang 包中. 下面是我在使用 enum 过程中的一些经验和总结. 原始的接口定义常量 public interface IConstants { String MON = "Mon"; String TUE = "Tue"; String WED = "Wed"; String THU = "Thu
-
Java this 关键字的使用方法详解
Java this 关键字的使用方法详解 构造方法中的this关键字 构造方法是一个类的对象在通过new关键字创建时自动调用的,在程序中不能向调用其他方法一样通过方法名(也就是类名)来调用.但如果一个类有多个构造方法,可以在一个构造方法中通过this(paras-)来调用其他的构造方法. 使用this来调用其他构造方法有如下几个约束. 1) 只能在构造方法中通过this来调用其他构造方法,普通方法中不能使用. 2) 不能通过this递归调用构造方法,即不能在一个构造方法中通过this直接或间接调
-
java 中迭代器的使用方法详解
java 中迭代器的使用方法详解 前言: 迭代器模式将一个集合给封装起来,主要是为用户提供了一种遍历其内部元素的方式.迭代器模式有两个优点:①提供给用户一个遍历的方式,而没有暴露其内部实现细节:②把元素之间游走的责任交给迭代器,而不是聚合对象,实现了用户与聚合对象之间的解耦. 迭代器模式主要是通过Iterator接口来管理一个聚合对象的,而用户使用的时候只需要拿到一个Iterator类型的对象即可完成对该聚合对象的遍历.这里的聚合对象一般是指ArrayList,LinkedList和底层实现为数
-
基于Python的Post请求数据爬取的方法详解
为什么做这个 和同学聊天,他想爬取一个网站的post请求 观察 该网站的post请求参数有两种类型:(1)参数体放在了query中,即url拼接参数(2)body中要加入一个空的json对象,关于为什么要加入空的json对象,猜测原因为反爬虫.既有query参数又有空对象体的body参数是一件脑洞很大的事情. 一开始先在apizza网站 上了做了相关实验才发现上面这个规律的,并发现该网站的请求参数要为raw形式,要是直接写代码找规律不是一件容易的事情. 源码 import requests im
-
Java线程三种命名方法详解
这篇文章主要介绍了Java线程三种命名方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.实例化一个线程对象 Thread t = new Thread(); t.setName("甲"); 2.实例化一个线程对象的同时,通过构造方法对线程进行命名 Thread(Runnable r, String name) Thread t = new Thread(() -> {}, "甲"); 3.使用自定义