使用VirtualBox模拟Linux集群的方法
1. 在主机Macbook上设置HOST
前文书已经把虚拟机的静态IP地址设置好,以后可以通过ip地址登录了。不过为了方便,还是设置一下,首先在Mac下修改hosts文件,这样在ssh时就不用输入ip地址了。
sudo vim /etc/hosts 或者 sudo vim /private/etc/hosts 这两个文件其实是一个,是通过link做的链接。注意要加上sudo, 以管理员运行,否则不能存盘。 ## # Host Database # # localhost is used to configure the loopback interface # when the system is booting. Do not change this entry. ## 127.0.0.1 localhost 255.255.255.255 broadcasthost ::1 localhost 50.116.33.29 sublime.wbond.net 127.0.0.1 windows10.microdone.cn # Added by Docker Desktop # To allow the same kube context to work on the host and the container: 127.0.0.1 kubernetes.docker.internal 192.168.56.100 hadoop100 192.168.56.101 hadoop101 192.168.56.102 hadoop102 192.168.56.103 hadoop103 192.168.56.104 hadoop104 # End of section
2. 复制虚拟机
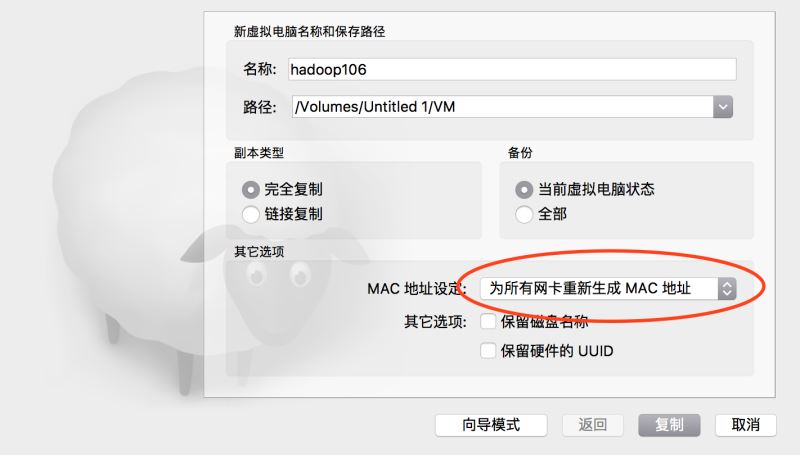
然后我们需要由上次配好的这一台虚拟机,复制出来多台,以便形成一个集群。首先关闭虚拟,在上面点右键,选复制,出现如下对话框,我选择把所有网卡都重新生成Mac地址,以便模拟完全不同的计算器环境。
3. 修改每一台的HOST, IP地址
复制完毕后,记得登录到虚拟机,按照前面提到的方法修改一下静态IP地址,免得IP地址冲突。
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3 vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
另外,最好也在每台Linux 虚拟机里也设置一下HOSTNAME,以便这些虚拟机之前相互通讯时也可以使用hostname。需要依次把几台机器的hostname都设置好。
[root@hadoop101 ~]# hostnamectl set-hostname hadoop107 [root@hadoop101 ~]# hostname hadoop107
4. xcall让服务器集群同时运行命令
因为我们同时有好几台机器,如果挨个挨个的登录上去操作,难免麻烦,可以写个shell脚本,以后从其中一台发起命令,让所有机器都执行就方便多了。下面是个例子。 我有hadopp100,hadopp101、hadopp102、hadopp103、hadopp104这个五台虚拟机。我希望以hadopp100为堡垒,统一控制所有其他的机器。 在/user/local/bin 下创建一个xcall的文件,内容如下:
touch /user/local/bin/xcall chmod +x /user/local/bin/xcall vi/user/local/bin/xcall #!/bin/bash pcount=$# if((pcount==0));then echo no args; exit; fi echo ---------running at localhost-------- $@ for((host=101;host<=104;host++));do echo ---------running at hadoop$host------- ssh hadoop$host $@ done ~
比如我用这个xcall脚本在所有机器上调用pwd名称,查看当前目录,会依次提示输入密码后执行。
[root@hadoop100 ~]# xcall pwd ---------running at localhost-------- /root ---------running at hadoop101------- root@hadoop101's password: /root ---------running at hadoop102------- root@hadoop102's password: /root ---------running at hadoop103------- root@hadoop103's password: /root ---------running at hadoop104------- root@hadoop104's password: /root [root@hadoop100 ~]#
5. scp与rsync
然后我们说一下 scp这个工具。 scp可以在linux间远程拷贝数据。如果要拷贝整个目录,加 -r 就可以了。
[root@hadoop100 ~]# ls anaconda-ks.cfg [root@hadoop100 ~]# scp anaconda-ks.cfg hadoop104:/root/ root@hadoop104's password: anaconda-ks.cfg 100% 1233 61.1KB/s 00:00 [root@hadoop100 ~]#
另外还可以用rsync, scp是不管目标机上情况如何,都要拷贝以便。 rsync是先对比一下,有变化的再拷贝。如果要远程拷贝的东西比较大,用rsync更快一些。 不如rsync在centOS上没有默认安装,需要首先安装一下。在之前的文章中,我们的虚拟机已经可以联网了,所以在线安装就可以了。
[root@hadoop100 ~]# xcall sudo yum install -y rsync
比如,把hadoop100机器上的java sdk同步到102上去:
[root@hadoop100 /]# rsync -r /opt/modules/jdk1.8.0_121/ hadoop102:/opt/modules/jdk1.8.0_121/
好了,到现在基本的工具和集群环境搭建起来了,后面就可以开始hadoop的学习了。
总结
以上所述是小编给大家介绍的使用VirtualBox模拟Linux集群的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

Virtualbox主机和虚拟机之间文件夹共享及双向拷贝(Windows<->Windows, Windows<->Linux)
最近学习Virtualbox的一些知识,记录下,Virtualbox下如何实现主机和虚拟机之间文件夹共享及双向拷贝 关于双向拷贝 1.设置虚拟机为"双向"共享粘贴 有的人反应只要设置双向粘贴就可以,但是我的不行,我还需要再给虚拟机安装一下增强功能.需要启动虚拟机,安装菜单项"设备"中的最后一项. 安装完增强功能,注意要重启虚拟机,双向拷贝才被启用. 关于文件夹共享 情况一: Host操作系统:Windows 7 Guest操作系统:Windows Server 1.
-
virtualbox 中的linux 共享文件的方法
首先要安装VirtualBox的增强版功能(VBoxGuestAdditions) 在 设备--->安装增强版功能----->运行,重启电脑. 1.Linux本地的共享文件夹建立 mkdir /mnt/localShare 2./etc/下的fstab 修改添加 win_share /mnt/localShare vboxsf rw, gid=100, uid=1000, auto 0 0 保存,这个是开机自动挂在,要重启生效 3.在终端可以执行以下命令: mount -t vboxsf wi
-
Linux 开发环境中为VirtualBox安装增强功能
VirtualBox安装CentOS后,再安装增强功能就可以共享文件夹.粘贴板以及鼠标无缝移动,主要步骤如下: 1.yum -y update 2.yum -y install g++gcc gcc-c++ make kernel-* #主要是在安装增强工具提示没有安装这些软件 3.yum -y install bzip2* # 增强工具用的是bzip2压缩 4.重启虚拟机 [root@localhost ~] reboot 5.点击 VirtualBox菜单栏中的[设备]->[分配光驱]->
-
VirtualBox安装Archlinux并配置桌面环境
最近无聊,就找来archlinux来玩一玩,去archlinux wiki上看了一下教程.以下是操作过程. 1. 下载镜像,下载地址; 2. 启动archlinux并选择Boot Arch Linux,然后就会进入字符安装界面; 3. 联网并安装基础系统: 1).联网并测试: root@archiso ~ # dhcpcd root@archiso ~ # ping archlinux.org -c 4 2).更新系统时间: root@archiso ~ # timedatectl set-nt
-
VirtualBox的Linux虚拟机文本模式和图形模式的切换问题
1.默认开机进入文本模式 如果想让开机自动进纯文本模式, 修改/etc/inittab 找到其中的 id:5:initdefault: 这行指示启动时的运行级是5,也就是图形模式 改成3就是文本模式了 id:3:initdefault: 这是因为Linux操作系统有六种不同的运行级(run level),在不同的运行级下,系统有着不同的状态,这六种运行级分别为: 0:停机(记住不要把initdefault 设置为0,因为这样会使Linux无法启动) 1:单用户模式,就像Win9X下的安全模式.
-
Oracle VM VirtualBox 在linux系统下安装增强插件实现访问主机的共享文档方法
一.安装增强插件 1 选择"设备"--"安装增强功能",然后可以看到在虚拟机的光驱中自动加载了增强iso的文件(VBoxGuestAdditions.iso) 2在linux 中挂载光驱 mount /dev/cdrom /mnt 3在将/mnt文件中的所有文件拷在/tmp目录下 cp -r /mnt/* /tmp 4在安装增强文件之前安装相应的包,安装后重启 yum install kernel yum install kernel-headers kernel-
-
使用VirtualBox模拟Linux集群的方法
1. 在主机Macbook上设置HOST 前文书已经把虚拟机的静态IP地址设置好,以后可以通过ip地址登录了.不过为了方便,还是设置一下,首先在Mac下修改hosts文件,这样在ssh时就不用输入ip地址了. sudo vim /etc/hosts 或者 sudo vim /private/etc/hosts 这两个文件其实是一个,是通过link做的链接.注意要加上sudo, 以管理员运行,否则不能存盘. ## # Host Database # # localhost is used to c
-
在linux上搭建Solr集群的方法
什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求. SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心. Solr集群的系统架构 需要实现的solr集群架构 Zooke
-
在Ubuntu 16.04上用Docker Swarm和DigitalOcean创建一个Docker容器集群的方法
介绍 Docker Swarm是用于部署Docker主机集群的Docker本地解决方案.您可以使用它来快速部署在本地计算机或受支持的云平台上运行的Docker主机集群. 在Docker 1.12之前,设置和部署Docker主机集群需要使用外部键值存储(如etcd或Consul)来进行服务发现.但是,使用Docker 1.12,不再需要外部发现服务,因为Docker提供了一个内置的键值存储,可以开箱即用. 在本教程中,您将了解如何使用Docker 1.12上的Swarm功能部署一组Docker机器
-
在 RHEL8 /CentOS8 上建立多节点 Elastic stack 集群的方法
Elastic stack 俗称 ELK stack,是一组包括 Elasticsearch.Logstash 和 Kibana 在内的开源产品.Elastic Stack 由 Elastic 公司开发和维护.使用 Elastic stack,可以将系统日志发送到 Logstash,它是一个数据收集引擎,接受来自可能任何来源的日志或数据,并对日志进行归一化,然后将日志转发到 Elasticsearch,用于分析.索引.搜索和存储,最后使用 Kibana 表示为可视化数据,使用 Kibana,我们
-
手把手教你在腾讯云上搭建hadoop3.x伪集群的方法
一.环境准备 CentOS Linux release 7.5.1804 (Core) 系统下 安装 创建文件夹 $ cd /home/centos $ mkdir software $ mkdir module 将安装包导入software文件夹 $ cd software # 然后把文件拖进去即可 这里使用的安装包是 /home/centos/software/hadoop-3.1.3.tar.gz /home/centos/software/jdk-8u212-linux-x64.tar.
-
docker搭建Zookeeper集群的方法步骤
目录 0.前言 1.前提 2.开始搭建 解释 创建zoo.cfg 3.docker搭建 1.docker创建网络 2.启动第1个zk节点 3.启动第2个zk节点 4.启动第3个zk节点 4.访问节点 1.进入zk第一个节点的docker容器内部 2.使用zk的客户端进行访问 3.在zk中使用命令 0.前言 之前在学springcloud的时候,提到有些项目还是使用zookeeper作为注册中心. 因此决定掌握这个技能,但是本地为了测试而部署一套zookeeper集群还是比较麻烦的. 所以打算使用
-
Laravel框架实现redis集群的方法分析
本文实例讲述了Laravel框架实现redis集群的方法.分享给大家供大家参考,具体如下: 在app/config/database.php中配置如下: 'redis' => array( 'cluster' => true, 'default' => array( 'host' => '172.21.107.247', 'port' => 6379, ), 'redis1' => array( 'host' => '172.21.107.248', 'port'
-
使用docker快速搭建Spark集群的方法教程
前言 Spark 是 Berkeley 开发的分布式计算的框架,相对于 Hadoop 来说,Spark 可以缓存中间结果到内存而提高某些需要迭代的计算场景的效率,目前收到广泛关注.下面来一起看看使用docker快速搭建Spark集群的方法教程. 适用人群 正在使用spark的开发者 正在学习docker或者spark的开发者 准备工作 安装docker (可选)下载java和spark with hadoop Spark集群 Spark运行时架构图 如上图: Spark集群由以下两个部分组成 集
-
Linux 集群技术
目前,越来越多的网站采用Linux操作系统,提供邮件.Web.文件存储.数据库等服务. 也有非常多的公司在企业内部网中利用Linux服务器提供这些服务.随着人们对Linux服务器依赖的加深,对其可靠性.负载能力和计算能力也倍加关注.Linux集群技术应运而生,可以以低廉的成本,很好地满足人们的这些需要. Linux竞争力很强的原因之一,是它可以运行于极为普及的PC机上,不需要购买昂贵的专用硬件设备.在几台运行Linux的PC机上,只要加入相应的集群软件,就可以组成具有超强可靠性.负载能力和计算能
-
PHP访问数据库集群的方法小结
本文总结分析了PHP访问数据库集群的方法.分享给大家供大家参考,具体如下: 一般常见的有三种做法: 1.自动判断sql是否为读,来选择数据库的连接: 实例化php DB类的时候,需要一次连接两台服务器,然后根据slq选择不同的连接,举个例子: $link_w = mysql_connect($w_host,$user,$pwd); $link_r = mysql_connect($r_host,$user,$pwd); //执行sql if(preg_match("/^select/i"