详解python实现数据归一化处理的方式:(0,1)标准化
在机器学习过程中,对数据的处理过程中,常常需要对数据进行归一化处理,下面介绍(0, 1)标准化的方式,简单的说,其功能就是将预处理的数据的数值范围按一定关系“压缩”到(0,1)的范围类。
通常(0, 1)标注化处理的公式为:

即将样本点的数值减去最小值,再除以样本点数值最大与最小的差,原理公式就是这么基础。
下面看看使用python语言来编程实现吧
import numpy as np
import matplotlib.pyplot as plt
def noramlization(data):
minVals = data.min(0)
maxVals = data.max(0)
ranges = maxVals - minVals
normData = np.zeros(np.shape(data))
m = data.shape[0]
normData = data - np.tile(minVals, (m, 1))
normData = normData/np.tile(ranges, (m, 1))
return normData, ranges, minVals
x = np.array([[78434.0829, 26829.86612], [78960.4042, 26855.13451], [72997.8308, 26543.79201],
[74160.2849, 26499.56629], [75908.5746, 26220.11996], [74880.6989, 26196.03995],
[74604.7169, 27096.87862], [79547.6796, 25986.68579], [74997.7791, 24021.50132],
[74487.4915, 26040.18441], [77134.2636, 24647.274], [74975.2792, 24067.31441],
[76013.5305, 24566.02273], [79191.518, 26840.29867], [80653.4589, 25937.22248],
[79185.9935, 26996.18228], [74426.881, 24227.71439], [73246.4295, 26561.59268],
[77963.1478, 25580.05298], [74469.8778, 26082.15448], [81372.3787, 26649.69232],
[76826.8262, 24549.77367], [77774.2608, 25999.96037], [79673.1361, 25229.04353],
[75251.7951, 24902.72185], [78458.073, 23924.15117], [82247.5439, 29671.33493],
[82041.2247, 27903.34268], [80083.2029, 28692.35517], [80962.0043, 28519.81002],
[79799.8328, 28740.27736], [80743.9947, 28862.75402], [80888.449, 29724.53706],
[81768.4638, 30180.20618], [80283.8783, 30417.55057], [79460.7078, 29092.52867],
[75514.1202, 28071.73721], [80595.5945, 30292.25917], [80750.4876, 29651.32254],
[80020.662, 30023.70025], [82992.3395, 29466.83067], [80185.5946, 29943.15481],
[81854.6163, 29846.18257], [81526.4017, 30218.27078], [79174.5312, 29960.69999],
[78112.3051, 26467.57545], [80262.4121, 29340.23218], [81284.9734, 28257.71529],
[81928.9905, 28752.84811], [80739.2727, 29288.85126], [83135.3435, 30223.4974],
[83131.8223, 29049.10112], [82549.9076, 28910.15209], [81574.0822, 28326.55367],
[80507.399, 28553.56851], [82956.2103, 29157.62372], [81909.7132, 29359.24497],
[80893.5603, 29326.64155], [82520.1272, 30424.96703], [82829.8548, 31062.24418],
[80532.1495, 29198.10407], [80112.7963, 29143.47905], [81175.0882, 28443.10574]])
newgroup, _, _ = noramlization(x)
newdata = newgroup
plt.scatter(x[:, 0], x[:, 1], marker='*', c='r', s=24)
plt.show()
print(len(x[:, 0]))
print(len(x[:, 1]))
print(newdata)
将数据进行归一化处理后,并使用matplotlib绘制出处理后的散点图分布如下:
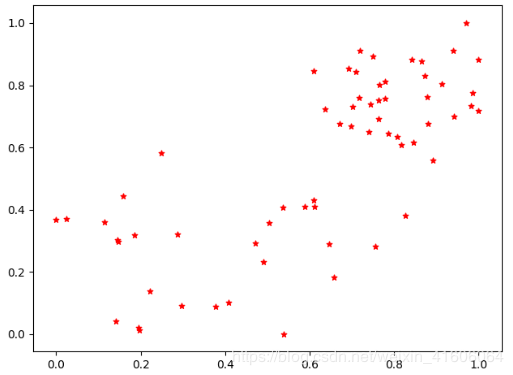
可以看到数据的数值范围均为(0,1)之间了
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
基于数据归一化以及Python实现方式
数据归一化: 数据的标准化是将数据按比例缩放,使之落入一个小的特定区间,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权. 为什么要做归一化: 1)加快梯度下降求最优解的速度 如果两个特征的区间相差非常大,其所形成的等高线非常尖,很有可能走"之字型"路线(垂直等高线走),从而导致需要迭代很多次才能收敛. 2)有可能提高精度 一些分类器需要计算样本之间的距离,如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时
-

详解python实现数据归一化处理的方式:(0,1)标准化
在机器学习过程中,对数据的处理过程中,常常需要对数据进行归一化处理,下面介绍(0, 1)标准化的方式,简单的说,其功能就是将预处理的数据的数值范围按一定关系"压缩"到(0,1)的范围类. 通常(0, 1)标注化处理的公式为: 即将样本点的数值减去最小值,再除以样本点数值最大与最小的差,原理公式就是这么基础. 下面看看使用python语言来编程实现吧 import numpy as np import matplotlib.pyplot as plt def noramlization(
-
详解Python小数据池和代码块缓存机制
前言 本文除"总结"外,其余均为认识过程:3.7.5:这部分官方文档不知道在哪里找,目前没有找到,有谁知道的可以麻烦留言吗? 谢谢了! 总结: 如果在同一代码块下,则采用同一代码块下的缓存机制: 如果是不同代码块,则采用小数据池的驻留机制: 需要注意的是,交互式输入时,每个命令都是一个代码块: 实现 Intern 保留机制的方式非常简单,就是通过维护一个字符串储蓄池,这个池子是一个字典结构,编译时,如果字符串已经存在于池子中就不再去创建新的字符串,直接返回之前创建好的字符串对象, 如果
-
详解Python进行数据相关性分析的三种方式
目录 相关性实现 NumPy 相关性计算 SciPy 相关性计算 Pandas 相关性计算 线性相关实现 线性回归:SciPy 实现 等级相关 排名:SciPy 实现 等级相关性:NumPy 和 SciPy 实现 等级相关性:Pandas 实现 相关性的可视化 带有回归线的 XY 图 相关矩阵的热图 matplotlib 相关矩阵的热图 seaborn 相关性实现 统计和数据科学通常关注数据集的两个或多个变量(或特征)之间的关系.数据集中的每个数据点都是一个观察值,特征是这些观察值的属性或属性.
-
详解Python中matplotlib模块的绘图方式
目录 1.matplotlib之父简介 2.matplotlib图形结构 3.matplotlib两种画绘图方法 方法一:使用matplotlib.pyplot 方法二:面向对象方法 1.matplotlib之父简介 matplotlib之父John D. Hunter已经去世,他的一生辉煌而短暂,但是他开发的的该开源库还在继续着辉煌.国内介绍的资料太少了,查阅了一番整理如下: 1968 出身于美国的田纳西州代尔斯堡. 之后求学于普林斯顿大学. 2003年发布Matplotlib 0.1版,初衷
-
详解Python连接MySQL数据库的多种方式
上篇文章分享了windows下载mysql5.7压缩包配置安装mysql 后续可以选择 ①在本地创建一个数据库,使用navicat工具导出远程测试服务器的数据库至本地,用于学习操作,且不影响测试服务器的数据 ②连接测试服务器的数据库账号和密码,在测试服务器上操作,内部测试服务器的数据库账号和密码在分配时会给不同账号做权限限制,如不同账号允许登录的方式.开放的数据库范围.账号可读写操作的权限都会不一样,若出现一直使用代码登录不上远程数据库服务器,应检查下账号是否具有权限,可询问负责管理测试服务器数
-
详解python 模拟豆瓣登录(豆瓣6.0)
最近在学习python爬虫,看到网上有很多关于模拟豆瓣登录的例子,随意找了一个试了下,发现不能运行,对比了一下代码和豆瓣网站,发现原来是豆瓣网站做了修改,增加了反爬措施. 首先看下要模拟登录的网站: 打开开发者模式: 在账号和密码随意填入数据: 发现会发送一个post请求: ur是:https://accounts.douban.com/j/mobile/login/basic 数据格式是: 于是可以来编写代码: import requests def main(): url_basic = '
-
详解tensorflow载入数据的三种方式
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
详解Python发送email的三种方式
Python发送email的三种方式,分别为使用登录邮件服务器.使用smtp服务.调用sendmail命令来发送三种方法 Python发送email比较简单,可以通过登录邮件服务来发送,linux下也可以使用调用sendmail命令来发送,还可以使用本地或者是远程的smtp服务来发送邮件,不管是单个,群发,还是抄送都比较容易实现.本米扑博客先介绍几个最简单的发送邮件方式记录下,像html邮件,附件等也是支持的,需要时查文档即可. 一.登录邮件服务器 通过smtp登录第三方smtp邮箱发送邮件,支
-
详解Python之数据序列化(json、pickle、shelve)
一.前言 1. 现实需求 每种编程语言都有各自的数据类型,其中面向对象的编程语言还允许开发者自定义数据类型(如:自定义类),Python也是一样.很多时候我们会有这样的需求: 把内存中的各种数据类型的数据通过网络传送给其它机器或客户端: 把内存中的各种数据类型的数据保存到本地磁盘持久化: 2.数据格式 如果要将一个系统内的数据通过网络传输给其它系统或客户端,我们通常都需要先把这些数据转化为字符串或字节串,而且需要规定一种统一的数据格式才能让数据接收端正确解析并理解这些数据的含义.XML 是早期被
-
详解python的几种标准输出重定向方式
一. 背景 在Python中,文件对象sys.stdin.sys.stdout和sys.stderr分别对应解释器的标准输入.标准输出和标准出错流.在程序启动时,这些对象的初值由sys.__stdin__.sys.__stdout__和sys.__stderr__保存,以便用于收尾(finalization)时恢复标准流对象. Windows系统中IDLE(Python GUI)由pythonw.exe,该GUI没有控制台.因此,IDLE将标准输出句柄替换为特殊的PseudoOutputFile