基于PHP的简单采集数据入库程序
说到采集,无非就是远程获取信息->提取所需内容->分类存储->读取->展示
也算是简单"小偷程序"的加强版吧
下面是对应核心代码(别拿去做坏事哦^_^)
所要采集的内容是某游戏网站上的公告,如下图:
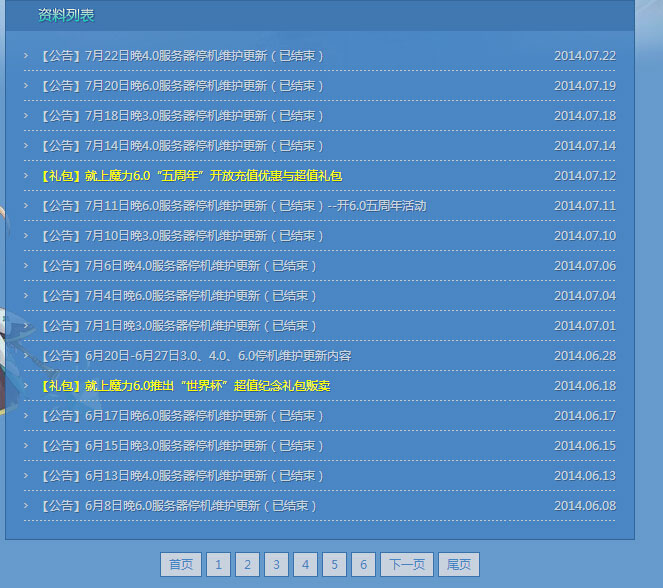
可先利用file_get_contents和简单正则获取基本页面信息

整理下基本信息,采集入库:
<?php
include_once("conn.php");
if($_GET['id']<=8&&$_GET['id']){
$id=$_GET['id'];
$conn=file_get_contents("http://www.93moli.com/news_list_4_$id.html");//获取页面内容
$pattern="/<li><a title=\"(.*)\" target=\"_blank\" href=\"(.*)\">/iUs";//正则
preg_match_all($pattern, $conn, $arr);//匹配内容到arr数组
//print_r($arr);die;
foreach ($arr[1] as $key => $value) {//二维数组[2]对应id和[1]刚好一样,利用起key
$url="http://www.93moli.com/".$arr[2][$key];
$sql="insert into list(title,url) value ('$value', '$url')";
mysql_query($sql);
//echo "<a href='content.php?url=http://www.93moli.com/$url'>$value</a>"."<br/>";
}
$id++;
echo "正在采集URL数据列表$id...请稍后...";
echo "<script>window.location='list.php?id=$id'</script>";
}else{
echo "采集数据结束。";
}
?>
conn.php是数据库连接文件
list.php是本页面
由于要采集的数据是分页显示的,且页面地址是规律递增,所以我用了js跳转代码,利用id传值控制采集的页数,也避免了for循环数目过大。

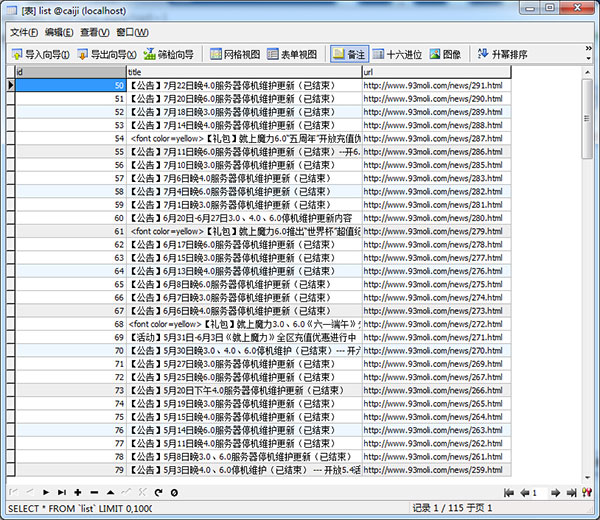
轻轻松松数据入库,下篇文章写关于具体url采集信息的过程。
相关推荐
-
开启CURL扩展,让服务器支持PHP curl函数(远程采集)
curl().file_get_contents().snoopy.class.php这三个远程页面抓取或采集中用到的工具,默迹还是侵向于用snoopy.class.php,因为他效率比较高且不需要服务器特定配置支持,在普通虚拟主机中即可使用,file_get_contents()效率稍低些,常用失败的情况.curl()效率挺高的,支持多线程,不过需要开启下curl扩展.下面是curl扩展开启的步骤: 1.将PHP文件夹下的三个文件php_curl.dll,libeay32.dll,ssleay
-
PHP采集类snoopy详细介绍(snoopy使用教程)
Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单,可以用来开发一些采集程序和小偷程序,本文章详细介绍snoopy的使用教程. Snoopy的一些特点: 抓取网页的内容 fetch 抓取网页的文本内容 (去除HTML标签) fetchtext 抓取网页的链接,表单 fetchlinks fetchform 支持代理主机 支持基本的用户名/密码验证 支持设置 user_agent, referer(来路), cookies 和 header content(头文件) 支持
-
php file_get_contents函数轻松采集html数据
复制代码 代码如下: <?php //全国,判断条件是$REQUEST_URI是否含有html if (!strpos($_SERVER["REQUEST_URI"],".html")) { $page="http://qq.ip138.com/weather/"; $html = file_get_contents($page,'r'); $pattern="/<B>全国主要城市.县当天和未来五天天气趋势预报在线查询
-
PHP采集利器 Snoopy 试用心得
Snoopy是什么? (下载snoopy) Snoopy是一个php类,用来模仿web浏览器的功能,它能完成获取网页内容和发送表单的任务. Snoopy的一些特点: * 方便抓取网页的内容 * 方便抓取网页的文本内容 (去除HTML标签) * 方便抓取网页的链接 * 支持代理主机 * 支持基本的用户名/密码验证 * 支持设置 user_agent, referer(来路), cookies 和 header content(头文件) * 支持浏览器转向,并能控制转向深度 * 能把网页中的链接扩展
-
snoopy 强大的PHP采集类使用实例代码
下载地址: http://www.jb51.net/codes/33397.html Snoopy的一些特点: 1抓取网页的内容 fetch 2 抓取网页的文本内容 (去除HTML标签) fetchtext 3抓取网页的链接,表单 fetchlinks fetchform 4 支持代理主机 5支持基本的用户名/密码验证 6 支持设置 user_agent, referer(来路), cookies 和 header content(头文件) 7支持浏览器重定向,并能控制重定向深度 8能把网页中的
-
PHP 采集程序 常用函数
当前的脚本网址 function get_php_url(){ if(!empty($_SERVER["REQUEST_URI"])){ $scriptName = $_SERVER["REQUEST_URI"]; $nowurl = $scriptName; }else{ $scriptName = $_SERVER["PHP_SELF"]; if(empty($_SERVER["QUERY_STRING"])) $nowu
-

基于PHP的cURL快速入门教程 (小偷采集程序)
最爽的是,PHP也支持 cURL 库.本文将介绍 cURL 的一些高级特性,以及在PHP中如何运用它. 为什么要用 cURL? 是的,我们可以通过其他办法获取网页内容.大多数时候,我因为想偷懒,都直接用简单的PHP函数: $content = file_get_contents("http://www.jb51.net");// or$lines = file("http://www.jb51.net");// orreadfile(http://www.jb51.
-
利用PHP命令行模式采集股票趋势信息
话不多说,下面直接来看实现代码. 主要函数只有一个类实现(stock.class.php): <?php class StockClass{ public $stockId; public function __construct($stockId){ $this -> stockId = $stockId; } private function getUrl(){ return "http://stockpage.10jqka.com.cn/" . $this ->
-
PHP实现采集抓取淘宝网单个商品信息
调用淘宝的数据可以使用淘宝提供的api,如果只需调用淘宝商品图片名称等公开信息在自己网站上,使用php中的 file_get_contents 函数实现即可. 思路: file_get_contents(url) 该函数根据 url 如 http://www.baidu.com 将该网页内容(源码)以字符串形式输出(一个整字符串),然后配合preg_match,preg_replace等这些正则表达式操作就可以实现获取该url特定div,img等信息了.当然前题是淘宝在单个商品页面的结构是固定的
-
PHP 采集获取指定网址的内容
参考别人想法变成自己的想法,你会发现慢慢下来以后你就拥有了临时解决很多问题的思路与方法. 复制代码 代码如下: <?php /* 功能:获取页面内容,存储下来阅读; lost63 */ Class GetUrl{ var $url; //地址 var $result; //结果 var $content; //内容 var $list; //列表 function GetUrl($url){ $this->url=$url; $this->GetContent(); $this->