解决使用openpyxl时遇到的坑
最近在用python处理Excel表格是遇到了一些问题
1, xlwt最多只能写入65536行数据, 所以在处理大批量数据的时候没法使用
2, openpyxl 这个库, 在使用的时候一直报错, 看下面代码
from openpyxl import Workbook
import datetime
wb = Workbook()
ws = wb.active
ws['A1'] = 42
ws.append([1,2,3])
ws['A2'] = datetime.datetime.now()
wb.save('test.xlsx')
报错信息如下
File "src\lxml\serializer.pxi", line 1652, in lxml.etree._IncrementalFileWriter.write TypeError: got invalid input value of type <class 'xml.etree.ElementTree.Element'>, expected string or Element
有没有人知道是什么原因呀? 惆怅!!!
got invalid input value of type <class ‘xml.etree.ElementTree.Element'>, expected string or Element
填坑:
出现这个问题好久了, 不知道怎么解决, 也去google 和baidu搜索, 一篇文章提到了可能是包冲突的问题, 抱着试一试的心态, 没想到解决了
lxml 这个包和openpyxl 起冲突, 解决办法, 先卸掉lxml
pip uninstall lxml
最后运行上面处理excel的代码, 运行成功, 无错误!!! 困扰了我很长时间的问题得以解决!!!
还有另一种方法:
由于lxml 包经常要用到, 所以每次卸载掉再安装实在是麻烦, 所以我有下面的想法
例如下面的代码, 从数据库中取数据存入表格
import pymysql
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://user:password@ip:port/database",encoding='utf-8')
sql = """SELECT catalog_1 as '目录一',catalog_2 as '目录二',catagory as '目录三',
region as '区域',year as '年份',data as '数据',unit as '单位' from table
where catalog_1 = "农业" limit 100
"""
df = pd.read_sql_query(sql, con=engine)
# writer = pd.ExcelWriter(r'C:\Users\Administrator\Desktop\test.xlsx')
# df.to_excel(writer)
# writer.save()
这时候, 我们不选择to_excel() 这个函数, 而是选择使用to_csv() ; 即可避免openpyxl 和lxml 的冲突
df.to_csv(r'C:\Users\Administrator\Desktop\test.csv',index=False) # 经过验证, 此种方法是行得通的
最后得到的csv 文件用Excel 可以直接打开, 也可以另存为*.xlsx文件
最终解决办法
今天发现我使用的openpyxl版本是3.0.2, 卸载此版本, 安装3.0.0版本
最新更新于2020-3-16, 经过测试, 此报错解除!
补充:Python—使用Openpyxl的dataframe_to_rows的一个小坑
这个坑说大不大,说小遇到了也头疼。
一般我们把dataframe直接写到Excel文件,直接 df.to_excel即可。不过如果想把多个表格写入同一个工作表呢,那就需要用openpyxl的dataframe_to_rows功能。
看下面一段代码。
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打开工作表
#把df1写入工作表
for row in dataframe_to_rows(df1):
ws.append(row)
#换行
ws.append([])
#把df2写入工作表
for row in dataframe_to_rows(df2):
ws.append(row)
wb.save('text.xlsx')
这段代码就是把df1,df2都写入到一个工作表,但一看结果,傻了,怎么标题行和内容之间多了空行啊

看看空行是如何产生的呢
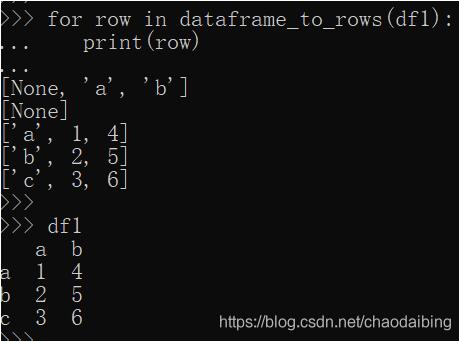
原来多了一个None啊,难怪是空行,目测None是index带来的,那就把index去掉呗

这回None是没有了,但是index的内容也想要显示,怎么办呢,这么办:

哈哈,这样就完美了。这里reset_index的意思就是把index列,变成普通列,比如:

如上图,如果直接reset_index,index列变成普通列,但是列头自动变成了index,这可不好,所以先给index列赋值,也就是df1.index.name=‘code'
最后代码如下
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
df1=pd.DataFrame([[1,4],[2,5],[3,6]] ,index=['a','b','c'],columns=['a','b'])
df2=pd.DataFrame([[1,4],[2,5],[3,6],[7,8]] ,index=['d','e','f','g'],columns=['a','b'])
wb=Workbook()
ws=wb.active #打开工作表
df1.index.name='code1'
df2.index.name='code2'
#把df1写入工作表
for row in dataframe_to_rows(df1.reset_index(),index=False):
ws.append(row)
#换行
ws.append([])
#把df2写入工作表
for row in dataframe_to_rows(df2.reset_index(),index=False):
ws.append(row)
wb.save('text.xlsx')
结果,哈哈,完美

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

详解Python openpyxl库的基本应用
1.导入文件 wb(可自定义) = openpyxl.load_workbook(#输入文件位置#) 2.转换为可处理的对象 sheet(可自定义)= wb['表格中对应的那一张的名称'] 3.sheet.cell(row=i, column=j) .value 可以显示对应单元格的值 4. wb.save['位置'] 保存表格 ''' # Created by Hailong Liu # for work # 2020.11.21 ''' import openpyxl #导入表格 w
-
详解Python中openpyxl模块基本用法
Python操作EXCEL库的简介 1.1 Python官方库操作excel Python官方库一般使用xlrd库来读取Excel文件,使用xlwt库来生成Excel文件,使用xlutils库复制和修改Excel文件,这三个库只支持到Excel2003. 1.2 第三方库openpyxl介绍 第三方库openpyxl(可读写excel表),专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易. 注意:如果文字编码是"gb2312" 读取后就会显示乱码,请
-
python openpyxl筛选某些列的操作
由于要复制excel 的某些单元格格式,需要对合并的单元格选出符合条件的 如下例是小于15的保留 然后在新表单中 wbsheet_new.merge_cells(cell2) wbsheet_new为新表单,cell2为筛选后保留的单元格,表达为I24:J24,K24:L24这样的格式 先正则筛选,筛选的结果为[('AO', 'AP')]这种list包含元组的表达方式,再用result[0][0]提取出第一个元素, 如果大于15列 column_index_from_string(result[
-
python中openpyxl和xlsxwriter对Excel的操作方法
前几天,项目中有个小需求:提供Excel的上传下载功能,使用模块:openpyxl 和 xlsxwriter,这里简单记录一下. 1.简介 Python中操作Excel的库非常多,为开发者提供了多种选择,如:xlrd. xlwt.xlutils.xlwings.pandas. win32com.openpyxl.xlsxwriter等等. 其中: 前三个一般混合使用,对Excel读写操作,适合旧版Excel,仅支持 xls 文件: win32com 库功能丰富,性能强大,适用于Windows:
-
浅谈openpyxl库,遇到批量合并单元格的问题
我就废话不多说了,大家还是直接看代码吧~ from openpyxl import Workbook from openpyxl import load_workbook from openpyxl.styles import NamedStyle, Border, Side, Alignment # 创建一个工作薄 wb = Workbook() # 创建一个工作表(注意是一个属性) table = wb.active # excel创建的工作表名默认为sheet1,一下代码实现了给新创建的工
-
python openpyxl 带格式复制表格的实现
有合并单元格的,先把合并单元格复制过去,合并单元格用wm=list(zip(wbsheet.merged_cells))得出合并单元格列表,把其中的(<CellRange A1:A4>,) 替换成为A1:A4格式 再从新表中合并单元格 再用.has_style: #拷贝格式 测试是否有格式,再复制格式和数据 其中: font(字体类):字号.字体颜色.下划线等 fill(填充类):颜色等 border(边框类):设置单元格边框 alignment(位置类):对齐方式 number_format
-
python openpyxl模块的使用详解
Python_Openpyxl 1. 安装 pip install openpyxl 2. 打开文件 ① 创建 from openpyxl import Workbook # 实例化 wb = Workbook() # 激活 worksheet ws = wb.active ② 打开已有 >>> from openpyxl import load_workbook >>> wb2 = load_workbook('文件名称.xlsx') 3. 储存数据 # 方式一:数据
-
解决使用openpyxl时遇到的坑
最近在用python处理Excel表格是遇到了一些问题 1, xlwt最多只能写入65536行数据, 所以在处理大批量数据的时候没法使用 2, openpyxl 这个库, 在使用的时候一直报错, 看下面代码 from openpyxl import Workbook import datetime wb = Workbook() ws = wb.active ws['A1'] = 42 ws.append([1,2,3]) ws['A2'] = datetime.datetime.now() w
-
Python绘制雷达图时遇到的坑的解决
ValueError: The number of FixedLocator locations (9), usually from a call to set_ticks, does not match the number of ticklabels (8). 运行书中例题时发现了这个错误, 原代码如上: import numpy as np import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams['font
-
解决使用this.getClass().getResource()获取文件时遇到的坑
目录 使用this.getClass().getResource()获取文件时遇到的坑 解决方式一 解决方式二 1.其实 2.以上两种方法返回的都是 java.net.URL对象 3.类加载器ClassLoader 总结 使用this.getClass().getResource()获取文件时遇到的坑 最近在工作中遇到需要读取配置文件,然后第一想法就是将文件放到项目的resources目录下, 然后使用: String fileName = "config/zh.md" String
-
vue resource post请求时遇到的坑
使用 post 请求 // global Vue object Vue.http.get('/someUrl', [options]).then(successCallback, errorCallback); Vue.http.post('/someUrl', [body], [options]).then(successCallback, errorCallback); // in a Vue instance this.$http.get('/someUrl', [options]).th
-
Java实现发送邮件功能时碰到的坑
之前用163邮箱发邮件时明明是成功的,但是使用中国移动自己的邮箱时,无论如何在linux服务器中都发送不成功,一开始报如下错误: javax.mail.MessagingException: Unknown SMTP host: mail.chinamobilesz.com at com.sun.mail.smtp.SMTPTransport.openServer(SMTPTransport.java:1959) ~ [mail-1.4.7.jar:1.4.7] at com.sun.mail.
-
浅谈在django中使用filter()(即对QuerySet操作)时踩的坑
代码伺候: 先看如下代码: 例1: message = Message.objects.filter(pk=message_id2) message[0].id = message_id2 message[0].content = content2 message[0].message_type = message_type2 print(message[0].id) print(message[0].content) message[0].save() 可正常从QuerySet中读取数据,并打
-
Springboot处理配置CORS跨域请求时碰到的坑
最近开发过程中遇到了一个问题,之前没有太注意,这里记录一下.我用的SpringBoot版本是2.0.5,在跟前端联调的时候,有个请求因为用户权限不够就被拦截器拦截了,拦截器拦截之后打印日志然后response了一个错误返回了,但是前端Vue.js一直报如下跨域的错误,但是我是配置了跨域的. has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested res
-
Spring Security中用JWT退出登录时遇到的坑
最近有个粉丝提了个问题,说他在Spring Security中用JWT做退出登录的时无法获取当前用户,导致无法证明"我就是要退出的那个我",业务失败!经过我一番排查找到了原因,而且这个错误包括我自己的大部分人都犯过. Session会话 之所以要说Session会话,是因为Spring Security默认配置就是有会话的,所以当你登录以后Session就会由服务端保持直到你退出登录.只要Session保持住,你的请求只要进入服务器就可以从 ServletRequest 中获取到当前的
-
使用C++实现插件模式时的避坑要点(推荐)
本文不打算严格地.用标准术语来讲前因后果.本文主要分析实践中常见的.因为对原理不清楚而搞出来的产品里的坑. 什么是插件模式和为什么要用插件模式 插件,Plug-In,或者(IE/Edge称之为)加载项/Add-On,(Office称之为)外接程序/Add-In,(GIMP称之为)扩展/Extension,等等,总之看字面意思都是“额外增加功能”的这种东西,是一类开发模式.基本思路就是,研发软件本体的时候,外部需求不明确.直到使用期仍然经常会增加功能细节.为了把变动部分切割开,在设计的时候,通过对
-
vuex中使用modules时遇到的坑及问题
目录 vuex使用modules时遇到的坑 vuex中modules基本用法 1. store文件结构 3. app.js文件内容 5. 配置main.js vuex使用modules时遇到的坑 其实也不算坑,只是自己没注意看官网api,定义module另外命名时,需要在module中加一个命名空间namespaced: true 属性,否则命名无法暴露出来,导致报[vuex] module namespace not found in mapState()等错误. vuex中modules基本