Python BeautifulSoup基本用法详解(通过标签及class定位元素)
如下:

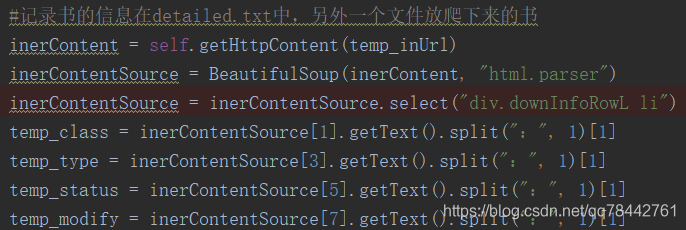
将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parser

tmp_soup.select里面的参数为:
div标签中class中带有listbg 下面 span标签中带有title,这种意思:
并且他们的类型如下:

都是ResultSet类型。

可以通过下面这种方式获取,
find('某个标签')['中包含的域']
当为li标签的时候,可以通过这样的方式获取:
到此这篇关于Python BeautifulSoup基本用法(通过标签及class定位元素)的文章就介绍到这了,更多相关Python BeautifulSoup用法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫库BeautifulSoup的介绍与简单使用实例
一.介绍 BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器.利用它不用编写正则表达式即可方便地实现网页信息的提取. Python常用解析库 解析器 使用方法 优势 劣势 Python标准库 BeautifulSoup(markup, "html.parser") Python的内置标准库.执行速度适中 .文档容错能力强 Python 2.7.3 or 3.2.2)前的版本中文容错能力差 lxml HTML 解析器 BeautifulSoup(markup,
-
python使用beautifulsoup4爬取酷狗音乐代码实例
这篇文章主要介绍了python使用beautifulsoup4爬取酷狗音乐代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, 安装方法:pip install beautifulsoup4 完整代码如下:双击就能直接运行 from bs4 import BeautifulSoup
-
python3 BeautifulSoup模块使用字典的方法抓取a标签内的数据示例
本文实例讲述了python3 BeautifulSoup模块使用字典的方法抓取a标签内的数据.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #python 2.7 #XiaoDeng #http://tieba.baidu.com/p/2460150866 #标签操作 from bs4 import BeautifulSoup import urllib.request import re #如果是网址,可以用这个办法来读取网页 #html_doc = "htt
-
Python爬虫实现使用beautifulSoup4爬取名言网功能案例
本文实例讲述了Python爬虫实现使用beautifulSoup4爬取名言网功能.分享给大家供大家参考,具体如下: 爬取名言网top10标签对应的名言,并存储到mysql中,字段(名言,作者,标签) #! /usr/bin/python3 # -*- coding:utf-8 -*- from urllib.request import urlopen as open from bs4 import BeautifulSoup import re import pymysql def find_
-

Python如何使用BeautifulSoup爬取网页信息
这篇文章主要介绍了Python如何使用BeautifulSoup爬取网页信息,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 简单爬取网页信息的思路一般是 1.查看网页源码 2.抓取网页信息 3.解析网页内容 4.储存到文件 现在使用BeautifulSoup解析库来爬取刺猬实习Python岗位薪资情况 一.查看网页源码 这部分是我们需要的内容,对应的源码为: 分析源码,可以得知: 1.岗位信息列表在<section class="widg
-
python爬虫学习笔记--BeautifulSoup4库的使用详解
目录 使用范例 常用的对象–Tag 常用的对象–NavigableString 常用的对象–BeautifulSoup 常用的对象–Comment 对文档树的遍历 tag中包含多个字符串的情况 .stripped_strings 去除空白内容 搜索文档树–find和find_all select方法(各种查找) 获取内容 总结 使用范例 from bs4 import BeautifulSoup #创建 Beautiful Soup 对象 # 使用lxml来进行解析 soup = Beautif
-
使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解
下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最基础的内容 html_doc = """ <html><head><title>The Dormouse's story</title></head> <p class="title"><b>The Dormouse's story</b></p>
-
Python BeautifulSoup基本用法详解(通过标签及class定位元素)
如下: 将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parser tmp_soup.select里面的参数为: div标签中class中带有listbg 下面 span标签中带有title,这种意思: 并且他们的类型如下: 都是ResultSet类型. 可以通过下面这种方式获取, find('某个标签')['中包含的域'] 当为li标签的时候,可以通过这样的方式获取: 到此这篇关于Python BeautifulSoup基本用法(通过标签及class定位元素)的
-
Python在信息学竞赛中的运用及Python的基本用法(详解)
前言 众所周知,Python是一种非常实用的语言.但是由于其运算时的低效和解释型编译,在信息学竞赛中并不用于完成算法程序.但正如LRJ在<算法竞赛入门经典-训练指南>中所说的一样,如果会用Python,在进行一些小程序的编写,如数据生成器时将会非常方便,它的语法决定了其简约性.本文主要介绍一下简单的Python用法,不会深入. Python的安装和实用 Linux(以Ubuntu系统为例) 一般的Linux都自带了Python,在命令行中输入Python即可进入 如果没有出现上图的文字,可以使
-
python isinstance函数用法详解
这篇文章主要介绍了python isinstance函数用法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 isinstance() 函数来判断一个对象是否是一个已知的类型类似 type(). isinstance() 与 type() 区别: type() 不会认为子类是一种父类类型,不考虑继承关系. isinstance() 会认为子类是一种父类类型,考虑继承关系. 如果要判断两个类型是否相同推荐使用 isinstance(). 语法
-
Python ellipsis 的用法详解
背景 在 Python 的基本类型中单例模式的值有三个 None 类型的 None ,NotImplemented 类型的 NotImplemented, Ellipsis 类型的 ... . None 已经用的烂大街了,NotImplemented 也比较常用,唯独 ... 在江湖上只知它是三巨头之一,但不知其用法. Ellipsis Ellipsis 在 python 中代表"省略",用现在的流形语来表达就是"老铁,不要在意这些细节!".哪什么时候要告诉别人不要
-
python爬虫学习笔记之Beautifulsoup模块用法详解
本文实例讲述了python爬虫学习笔记之Beautifulsoup模块用法.分享给大家供大家参考,具体如下: 相关内容: 什么是beautifulsoup bs4的使用 导入模块 选择使用解析器 使用标签名查找 使用find\find_all查找 使用select查找 首发时间:2018-03-02 00:10 什么是beautifulsoup: 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(官方) beautif
-
Python中Threading用法详解
Python的threading模块松散地基于Java的threading模块.但现在线程没有优先级,没有线程组,不能被销毁.停止.暂停.开始和打断. Java Thread类的静态方法,被移植成了模块方法. main thread: 运行python程序的线程 daemon thread 守护线程,如果守护线程之外的线程都结束了.守护线程也会结束,并强行终止整个程序.不要在守护进程中进行资源相关操作.会导致资源不能正确的释放.在非守护进程中使用Event. Thread 类 (group=No
-
python BeautifulSoup使用方法详解
直接看例子: 复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*-from bs4 import BeautifulSouphtml_doc = """<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>T
-
Python help()函数用法详解
help函数是python的一个内置函数(python的内置函数可以直接调用,无需import),它是python自带的函数,任何时候都可以被使用.help函数能作什么.怎么使用help函数查看python模块中函数的用法,和使用help函数时需要注意哪些问题,下面来简单的说一下. 一.help()函数的作用在使用python来编写代码时,会经常使用python自带函数或模块,一些不常用的函数或是模块的用途不是很清楚,这时候就需要用到help函数来查看帮助.这里要注意下,help()函数是查看函
-
python and or用法详解
and 和 or 是python的两个逻辑运算符,可以使用and , or来进行多个条件内容的判断.下面通过代码简单说明下and or的用法: 1. or:当有一个条件为真时,该条件即为真.逻辑图如下: 测试代码如下: a=raw_input('please input somting:') if a=='a' or a=='b': print 'it is a or b' else: print 'it is not a or b' 执行代码,输入a,b,ac,结果如下: please inp
-
python的sorted用法详解
列表有自己的sort方法,其对列表进行原址排序,既然是原址排序,那显然元组不可能拥有这种方法,因为元组是不可修改的. 排序,数字.字符串按照ASCII,中文按照unicode从小到大排序 x = [4, 6, 2, 1, 7, 9]x.sort()print (x) # [1, 2, 4, 6, 7, 9] 如果需要一个排序好的副本,同时保持原有列表不变,怎么实现呢? x = [4, 6, 2, 1, 7, 9]y = x[:]y.sort()print(y) # [1, 2, 4, 6, 7,